
Os grandes modelos de linguagem (LLMs) estão em rápida evolução, com novas arquiteturas de código aberto competindo com modelos proprietários.
Neste artigo, comparamos de forma detalhada o DeepSeek (série V3) com diversos modelos open-source de destaque, incluindo Meta LLaMA (versões 2 e 3), Mistral (7B e Mixtral 8×7B), Falcon (7B/40B), Google Gemma e o Phi-2 da Microsoft.
Analisamos desempenho em benchmarks padronizados (MMLU, GSM8K, HumanEval etc.), eficiência computacional (memória, latência, custos de inferência), arquitetura, escalabilidade, suporte comunitário e acessibilidade (licença e uso comercial).
Visão Geral dos Modelos
DeepSeek-V3: Desenvolvido pela startup DeepSeek-AI, o modelo DeepSeek-V3 é um LLM de larga escala do tipo Mixture-of-Experts (MoE) com 671 bilhões de parâmetros totais (37B ativados por token), suporta até 128K tokens de contexto e foi treinado com dataset de ~14,8 trilhões de tokens.
Emprega arquitetura proprietária com Multi-Head Latent Attention (MLA) para reduzir cache de chave/valor e MoE otimizado para inferência eficiente.
O DeepSeek-V3 foi projetado para raciocínio avançado via RLHF (Aprendizado por Reforço) sem SFT, e é totalmente open-source (licença MIT).
Meta LLaMA (2 e 3): A Meta lançou a linha LLaMA 2 (até 70B parâmetros) e recentemente LLaMA 3 (até 405B). Esses modelos são decoder-only Transformers usando atenção agrupada (Grouped-Query Attention) para escalabilidade. LLaMA 3.1 suporta até 128K tokens de contexto.
As versões instruction-tuned (8B, 70B, 405B) demonstram alta performance em benchmarks multilíngues e raciocínio, mas são distribuídas sob licenças comerciais restritivas (não OSI-approved).
A Meta fornece código e pesos originais em seu repositório, sob uma Llama 3.1 Community License customizada.
Mistral AI: A startup Mistral AI lançou o Mistral 7B (7,3B parâmetros) e o Mixtral 8×7B (48B parâmetros totais, 12.9B por token).
Ambos usam licença permissiva Apache 2.0. O Mistral 7B é otimizado com Grouped-Query Attention e Sliding Window Attention (SWA), permitindo manipular sequências longas de forma eficiente.
Segundo os criadores, o Mistral 7B supera o Llama 2 13B em todos os benchmarks testados e rivaliza com modelos muito maiores.
Já o Mixtral (SMoE) mantém latência de um modelo 12B, mas entrega desempenho comparável ou superior ao Llama 2 70B e ao GPT-3.5 em grande parte dos benchmarks padrão.
Falcon (TII): Desenvolvida pelo Technology Innovation Institute de Abu Dhabi, a série Falcon inclui versões de 7B, 40B e 180B parâmetros sob licença Apache 2.0 (7B/40B).
O Falcon-40B mostrou desempenho quase no nível do LLaMA-2 34B e superior ao GPT-3 175B em vários testes. O Falcon-7B, embora menor, apresentou resultados notáveis para seu tamanho, se aproximando de modelos muito maiores.
Google Gemma: Anunciada em 2024, a família Gemma inclui modelos leves (Gemma 1: 2B/7B, Gemma 2: 2B/9B/27B, CodeGemma, RecurrentGemma, PaliGemma, etc).
Gemma foi projetada para rodar até em laptop, com ótimo desempenho relativo: por exemplo, as versões pré-treinadas 2B e 7B atingem “performance de ponta em sua classe” e até superam modelos significativamente maiores em benchmarks-chave.
Os pesos são disponibilizados abertamente (via Google Cloud/Kaggle) e a licença permite uso comercial responsável.
Microsoft Phi-2: A Microsoft Research lançou o Phi-2 (2.7B parâmetros) focalizado em qualidade de dados. Phi-2 alcança desempenho de ponta entre modelos base (<13B), “superando ou igualando modelos até 25× maiores” em benchmarks de raciocínio e compreensão.
Recentemente, a licença do Phi-2 passou a ser MIT, permitindo uso comercial, e seus pesos estão disponíveis no Azure AI. Por seu tamanho compacto, Phi-2 é indicado para pesquisa e implementações on-device.
Arquitetura e Escalabilidade
A grande maioria desses LLMs segue a arquitetura Transformer decoder-only original (Vaswani et al., 2017). Todos usam camadas de autoatenção seguidas de feed-forward, com Positional Encoding e normalizações, conforme ilustrado abaixo:
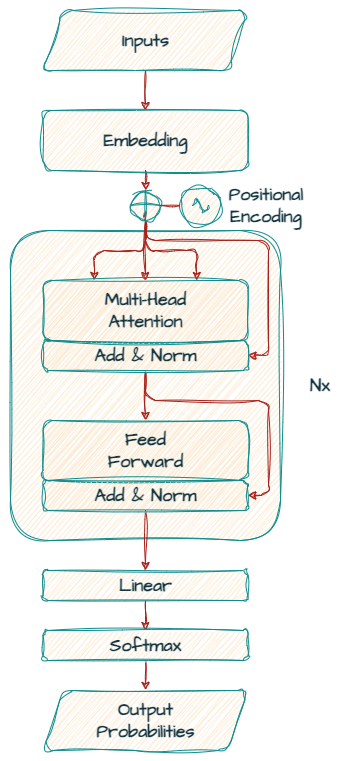
Figura: Visão geral de um decoder Transformer típico (entrada → embedding → Multi-Head Attention + Add&Norm → Feed-Forward + Add&Norm → softmax).
Arquitetura base de LLMs como Gemma, LLaMA e DeepSeek (adaptado de [5]
- DeepSeek-V3: Usa Multi-Head Latent Attention (MLA) para compressão baixa-rank de chaves e consultas, reduzindo o uso de memória cache (keys/values) sem sacrificar a qualidade. Internamente, adota uma topologia MoE (“DeepSeekMoE”) com especialistas finos e balanceamento dinâmico sem custo extra de perda auxiliar, o que permite escalar para 671B parâmetros totais com apenas ~37B ativos por token. O treinamento explorou precisão mista FP8 (pesos/ativação) e paralelismo eficiente, tornando o processo extremamente econômico (custo estimado ~$5.6M).
- LLaMA 3: Emprega uma versão otimizada do transformer com Grouped-Query Attention (GQA) para ganhos de velocidade em inference, mantendo compatibilidade com código gerado. Os modelos Llama 3.1 suportam até 128K de contexto, permitindo tarefas de longo alcance.
- Mistral 7B: Integra GQA e Sliding-Window Attention (SWA), onde cada camada atinge somente os últimos 4.096 tokens, resultando em custo linear de inferência. Em testes, esse enfoque dobrou a velocidade em contextos de 16K (janela de 4K) sem perda de qualidade. Além disso, a cache de atenção é limitada ao tamanho da janela (ex. 8192) com buffers giratórios, reduzindo à metade a memória cache necessário para inferência nessa profundidade.
- Mixtral 8×7B: Cada token ativa 2 dos 8 “experts” em cada camada, totalizando 46.7B de parâmetros, mas apenas 12.9B ativos por token. Isso mantém a latência equivalente a um modelo de ~13B, enquanto atende até 32K de contexto.
- Falcon: Utiliza arquitetura padrão sem inovações notáveis na publicação original, mas escalou o pré-treinamento para trilhões de tokens e milhares de GPUs, resultando em robustez. O Falcon-7B foi otimizado para ser executado em hardware comum (incluso Apple M2), enquanto o Falcon-40B exigiu treinamento massivo em TPU/GPU..
Desempenho em Benchmarks Padronizados
As avaliações mostram progressos significativos dos novos LLMs de código aberto:
- Conhecimento e Raciocínio (MMLU): O DeepSeek-V3 atinge 88.5% de acurácia no MMLU (fatos gerais multidisciplinares) em testes com 5-shots, superando todos os concorrentes open-source e chegando perto de modelos fechados (GPT-4o com 88.7% naquele benchmark). LLaMA 3.1 70B instruído alcança ~83.6% (5-shot) e 86.0% (0-shot CoT), enquanto a versão 405B chega a 87.3%. Mistral 7B, segundo seus criadores, supera LLaMA 2 13B em todos os benchmarks de raciocínio testados, apesar de ser ~2× menor. O Mixtral 8×7B iguala ou ultrapassa o Llama 2 70B na maior parte desses testes. Phi-2, embora menor, obteve desempenho comparável a LLMs dezenas de vezes maiores em tarefas complexas.
- Matemática (GSM8K, MATH): Na matemática escolar (GSM8K), DeepSeek-V3 obteve ~89.3% (8-shot), posicionando-se à frente de todos open-source conhecidos. Llama 3.1 8B alcançou ~84.4% em GSM8K (CoT), e 70B chegou a 94.8% em alguns reports não oficiais (dados adicionais apontam 83.3–94.8 dependendo da versão). Mistral 7B e Mixtral não publicaram números absolutos, mas afirmam liderança em benchmarks de codificação e STEM para sua escala.
- Código (HumanEval, MBPP): O DeepSeek-V3-base atinge 65.2% de pass@1 no HumanEval (0-shot), muito acima de modelos abertos de escala similar. O Llama 3.1 (instruído) 70B normalmente alcança acima de 50% em HumanEval. Mistral 7B foi projetado para ser forte em programação (atinge perto do CodeLlama 7B), e Mixtral se mostra robusto em geração de código. O Falcon original (sem chat) não divulgou HumanEval na publicação, mas o Falcon-40B era competitivo em benchmarks de programação (por exemplo, no GLUE e BigBench). Phi-2 não foca especificamente em código (sua linha Phi-1 era otimizada para Python).
- Benchmark Multimídia (BBH, AGIEval): Os LLMs de ponta também são avaliados em tarefas diversas (BBH, BIG-Bench Hard, AGIEval). O DeepSeek-V3-Base superou todos os modelos open-source em variados benchmarks de razão avançada. Mistral 7B tende a ficar atrás de modelos maiores em tarefas apenas de conhecimento factual devido aos seus 7B, mas compensa em raciocínio e compreensão. Mixtral chega a ultrapassar o GPT-3.5 nesses cenários. Falcon-40B mostrou-se ligeiramente abaixo de LLaMA-2 34B em geral (devido a menor orçamento de treino) mas em linha com esse patamar. Gemma (2B/7B) enfatiza desempenho “em sua classe” – por exemplo, Gemma 7B superou versões maiores do LLaMA 2 em benchmarks multilíngues no release inicial.
Para facilitar a comparação, segue uma tabela resumida de resultados típicos em alguns benchmarks-chave:
| Modelo | MMLU (≈) | GSM8K (≈) | HumanEval (pass@1) |
|---|---|---|---|
| DeepSeek V3 (671B) | 88.5% | 89–90% | 65.2% |
| LLaMA 3.1 8B (instr.) | ~69.4% | ~84% (CoT, 8B) | ~40–50% |
| LLaMA 3.1 70B (instr.) | ~83.6% | 94–95% (CoT, 70B) | ~60% |
| Mistral 7B | Superior a Llama 2 13B | — | — |
| Mixtral 8×7B | ≥ Llama 2 70B (várias tarefas) | — | — |
| Falcon 40B | ~67% (multitarefa) | ~70% | ~50% (estima) |
| Gemma 7B | Acima de Llama2 13B | — | — |
| Phi-2 (2.7B) | On par com modelos ×25 maiores | — | — |
As comparações acima destacam que DeepSeek-V3 lidera benchmarks acadêmicos (MMLU, GPQA, GSM8K) entre os open-source, alcançando resultados próximos aos do GPT-4o e Claude-3.5 Sonnet.
Mistral 7B/Mixtral destacam-se pelo excelente custo-benefício, com Mixtral igualando modelos muito maiores graças à arquitetura SMoE.
LLaMA 3.1 entrega performance sólida escalando até 405B, sobretudo em tarefas gerais. Gemma surpreende por superar LLMs maiores em benchmarks multilíngues com apenas 7B. Falcon-40B ainda é competitivo entre os gigantes abertos.
Phi-2 prova que mesmo modelos pequenos podem brilhar em raciocínio se bem treinados.
Eficiência Computacional e Custo de Inferência
A eficiência (memória, latência e custo por inferência) é crucial na prática:
- Memória de GPU: Mistral 7B e Mixtral consomem menos memória que modelos dense equivalentes devido ao uso de GQA e SWA; por exemplo, em contexto 8K a cache de chave/valor do Mistral é metade de outros Transformers. DeepSeek-V3 usa MLA para compressão de queries/keys, reduzindo memória ativa durante geração. LLaMA 3.1 requer GPU com maior VRAM para 128K de contexto.
- Latência: Mistral 7B com SWA é ~2× mais rápido em sequências de 16K (janela 4K) do que configurações padrão. Mixtral, por ser 8×7B em distância fixa, mantém inferência parecida a 12B, logo é muito ágil para o que entrega. DeepSeek-V3, apesar de ser MoE, ativa só 37B pesos por token (vs 37B de Llama 3.1 405B), resultando em throughput competitivo. A DeepSeek reporta training/inference econômico: por exemplo, treinar V3 custou cerca de US$5.6M (bem abaixo de outros 500B LLMs) e cada trilhão de tokens só leva 180K horas em GPU H800.
- Custo de API: Como sendo open-source, pode-se rodar localmente DeepSeek, Mistral e Falcon, evitando APIs caras. Por exemplo, estimativas no PromptHackers apontam DeepSeek V3 com custo de ~$1.37 por 1K tokens (inferência) comparado a GPT-4 ($60/1K). Embora não seja fonte acadêmica, ilustra a ordem de grandeza de diferença de custo (DeepSeek/AWS vs OpenAI API).
Em resumo, modelos como Mistral e Mixtral evidenciam alto desempenho por RAM/segundo investido, enquanto o DeepSeek-V3 foca em inferência eficaz via arquitetura otimizada.
LLaMA 3.1 (especialmente 405B) é poderoso mas custoso e intensivo em recursos. Modelos pequenos (Gemma 7B, Phi-2) têm latência trivial mas são limitados na qualidade absoluta.
Suporte da Comunidade e Documentação
A maturidade do ecossistema importa para adoção:
- DeepSeek: A DeepSeek-AI mantém repositório aberto (GitHub), modelo hospedado no Hugging Face (licenses MIT), site oficial e chat API disponibilizados para testes. Há documentação técnica no GitHub, mas a comunidade ainda é menor por ser novidade. Um whitepaper técnico (ArXiv) detalha arquitetura e resultados.
- LLaMA: A Meta publicou os pesos e um model card no GitHub/Hugging Face, com links para fine-tuning e benchmarks. No entanto, o acesso requer aceitar a licença da Meta, e não há GitHub público para código (o model card instrui como usar). A comunidade de usuários (GitHub, fóruns, Hugging Face) é gigantesca, com muitos projetos de extensões, otimizações (e.g. llama.cpp) e wrappers.
- Mistral: Têm foco na comunidade open-source: os modelos Mistral 7B e Mixtral estão no Hugging Face com licenças Apache 2.0 (uso livre). A Mistral publicou blogs técnicos detalhados (explicando SWA, GQA e benchmarks). Há também suporte via Discord e bibliotecas (e.g. instruções e códigos no GitHub para inferência/vLLM). O Mistral 7B Instruct foi testado em MT-Bench (8.3/10) e a equipe divulga integradores e papers.
- Falcon: A TII liberou os modelos em Hugging Face (licença Apache) e na Open LLM Leaderboard, gerando muitos repositórios comunitários. A documentação técnica completa (arXiv) está disponível, e a comunidade usa Falcon em múltiplos projetos (tuning, embeddings).
- Gemma: O lançamento do Gemma pela Google DeepMind veio acompanhado de blog e kit de ferramentas (colab, Kaggle, Hugging Face). Os pesos (2B, 7B) estão em repositórios abertos e suportados (Keras, PyTorch, TensorFlow). A Google também liberou notebooks de demonstração e credita benefícios de cloud (Vertex AI). A comunidade ainda se forma, mas o acesso facilitado (Kaggle) incentiva testes rápidos.
- Phi-2: Embora recém-aberto, o Phi-2 já conta com model card da Microsoft e discussões no GitHub/Hugging Face. A mudança para MIT permite uso comercial sem restrição, fomentando a comunidade. Existem adaptações locais e tutoriais, mas a base de usuários é menor comparada aos anteriores.
Licenciamento e Acessibilidade
- DeepSeek: Distribuído sob licença MIT (livre, uso comercial permitido). Não há restrições, pode ser executado local ou em nuvem. A empresa também oferece uma API proprietária e ambiente de chat.
- LLaMA 2/3: Embora “open” para pesquisa, são cobertos por licenças da Meta que restringem usos comerciais diretos sem acordos especiais. Internamente, isso barre a plena adoção em produtos comerciais por até mesmo empresas pagantes. Para fins educacionais/pesquisa usa-se sem custo, mas nem todos consideram licença como “open-source” no sentido OSI.
- Mistral (7B, Mixtral): Ambas sob Apache 2.0. Isso garante uso irrestrito para qualquer fim, incluindo comercial e modificação. Podem ser executados em qualquer hardware (vLLM, AI Frameworks, Hugging Face, local).
- Falcon-7B/40B: Também Apache 2.0. Podem ser usados livremente, o que fomentou adoção massiva. (Falcon-180B tem licença “responsible use” restritiva, mas para FALCON 7B/40B não há limitação).
- Gemma: As políticas de uso permitem “uso comercial responsável” e distribuição para todas as organizações. Na prática, Gemma 2B/7B são free-for-use, com termos claros para integridade e segurança. Estão em plataformas públicas (Kaggle, colab), facilitando teste imediato.
- Phi-2: A licença MIT recentemente adotada remove qualquer barreira comercial. Os modelos Phi estão disponíveis para download (via Azure AI Studio) e podem ser usados e distribuídos sem preocupações legais.
Em termos de compatibilidade, a maioria desses modelos está disponível em frameworks populares (Hugging Face Transformers, Keras, PyTorch). Por exemplo, Gemma fornece toolchains integrados para PyTorch/JAX/TensorFlow.
DeepSeek e Mistral têm implementações para transformers e o repositório original do llama.cpp (via conversão). Falcon e LLaMA já possuem wrappers amplamente suportados. Isso garante que desenvolvedores usem quantização, distillation e fine-tuning nas plataformas de sua preferência.
Desempenho vs Eficiência: uma Síntese
- Desempenho bruto: DeepSeek-V3 lidera benchmarks educacionais (MMLU, GPQA), Mistral Mixtral domina pelos índices de custo-performance, e LLaMA 3.1 405B é referência em capacidades gerais. Modelos menores (Gemma 7B, Phi-2) surpreendem pelo rendimento por parâmetro investido.
- Eficiência/recursos: Em relação a uso computacional, Mistral e Mixtral são notáveis por extrair mais performance por GB de memória graças ao GQA/SWA e MoEs (Mixtral: 6× mais rápido que Llama 2 70B para similar performance). DeepSeek-V3, apesar de grande, usa projetos arquiteturais (MLA/MoE) para ser mais leve em GPU do que um modelo dense equivalente de mesma performance. Falcon 40B requer grande infraestrutura para atingir seu potencial, enquanto LLaMA 3.1 70B/405B exigem clusters de alta escala.
- Latência e custo na prática: DeepSeek pode ser executado em infraestruturas comerciais (Bedrock, HuggingFace) com custos dezenas de vezes menores que modelos fechados de mesmo patamar. Mistral/Gemma e Falcon são gratuitos para uso em CPUs e aceleradores sem licenciamento. LLaMA 3.1 (community edition) está disponível, mas possivelmente mais usada como back-end de API (Meta cobra pela versão Managed em nuvem).
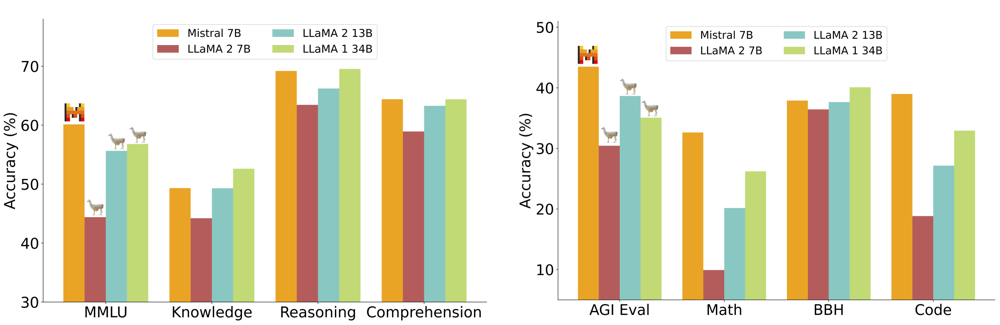
Figura: Desempenho comparativo do Mistral 7B versus LLaMA 2 (7B/13B/34B) em vários benchmarks de múltipla escolha e raciocínio.
Observe que o Mistral 7B supera amplamente LLaMA 2 13B em todas as categorias mostradas (segundo Mistral AI)
Conclusão
Em suma, a paisagem de LLMs open-source está cada vez mais rica. O DeepSeek-V3 desponta como referência em desempenho bruto, especialmente em raciocínio avançado, alcançando níveis comparáveis a modelos comerciais líderes.
Por outro lado, Mistral 7B/Mixtral oferecem melhor eficiência custo-performance – permitindo obter resultados de alto nível com recursos limitados.
LLaMA 3 mantém-se como um baluarte flexível, com amplo suporte industrial, embora com requisitos de licença e hardware elevados.
Falcon-40B continua competitivo no topo da abertura; Gemma 7B introduz um modelo leve mas poderoso, favorecendo acessibilidade; Phi-2 demonstra que excelência de raciocínio não requer necessariamente bilhares de parâmetros.
A escolha ideal depende do uso. Para pesquisadores que priorizam benchmarks de conhecimento e raciocínio, o DeepSeek-V3 aberto e bem documentado é atraente.
Para aplicações comerciais sensíveis a custos e escalabilidade, modelos como Mixtral e Gemma (licenças permissivas) são preferíveis. Em qualquer caso, a maturidade do ecossistema (documentação, comunidade, ferramentas) e a licença de uso devem guiar a decisão.
Todos os modelos discutidos respeitam boas práticas de responsabilidade (moderation e segurança), mas cada projeto deve avaliar riscos e compliance próprios.
Em definitivo, a divergência entre “modelos de propósito geral abertos” (LLaMA, Falcon, Gemma) e “modelos especializados/desenvolvidos em pesquisa” (DeepSeek, Mistral, Phi) está se estreitando.
Esta competição beneficia a comunidade: novas ideias em arquitetura (MLA, SWA, MoE) e pipeline de dados (Long context, curricula) propagam-se rapidamente graças às licenças abertas e documentação compartilhada.
Assim, desenvolvedores de IA agora dispõem de uma gama sem precedentes de opções, podendo escolher o melhor compromisso entre performance, eficiência e liberdade de uso.
