
A DeepSeek AI anunciou o lançamento do DeepSeek-R1-0528, uma atualização significativa de seu modelo de linguagem de código aberto focado em raciocínio.
Este novo modelo, lançado em 28 de maio de 2025, eleva o desempenho do DeepSeek-R1 a patamares próximos aos dos líderes proprietários do setor, como o modelo OpenAI o3 e o Google Gemini 2.5 Pro.
Assim como seu predecessor de janeiro, o R1-0528 é distribuído sob licença MIT aberta, permitindo uso comercial e customizações pela comunidade de pesquisadores e desenvolvedores.
A atualização foi projetada para entregar raciocínio mais profundo e respostas mais confiáveis em tarefas complexas de matemática, ciência, negócios e programação, consolidando o modelo como um dos principais sistemas de IA de código aberto da atualidade.
Principais Melhorias em Relação à Versão Anterior
Em relação à versão anterior do modelo, o DeepSeek-R1-0528 apresenta avanços expressivos em capacidade de raciocínio e qualidade de respostas.
Um destaque é o salto na profundidade das cadeias de pensamento geradas: em testes desafiadores como o AIME 2025 (exame de matemática), o novo modelo passou a utilizar em média 23 mil tokens para raciocinar cada questão, contra 12 mil tokens anteriormente, resultando em um aumento da taxa de acerto de 70% para 87,5%.
Essa melhoria reflete um raciocínio mais elaborado e verificações internas mais robustas antes de chegar à resposta final.
Também houve progresso notável nas habilidades de programação e lógica. Em um benchmark de codificação como o LiveCodeBench, a acurácia do modelo subiu de 63,5% para 73,3%, indicando respostas de código mais corretas e funcionais.
Em um desafio geral de raciocínio de alto nível conhecido como “Humanity’s Last Exam”, a nova versão mais que duplicou sua pontuação (de 8,5% para 17,7%), reduzindo a distância em relação aos modelos proprietários de ponta nesses testes extremos.
Além disso, o R1-0528 demonstrou melhorias sutis em conhecimentos gerais (por exemplo, pequeno ganho no benchmark MMLU) e conseguiu lidar melhor com tarefas complexas sem se perder, graças a um decréscimo significativo na taxa de alucinações do modelo.
Em resumo, o DeepSeek-R1-0528 traz ganhos de desempenho em múltiplas frentes: raciocínio matemático mais preciso, geração de código mais confiável, respostas lógicas mais coerentes e menos alucinações.
Esses aprimoramentos aproximam seu desempenho global ao de modelos fechados de última geração, reforçando o potencial das abordagens open-source em alcançar paridade de qualidade com sistemas proprietários.
Arquitetura Técnica e Aprendizado por Reforço
O desenvolvimento do DeepSeek-R1-0528 envolveu inovações na arquitetura e no processo de treinamento do modelo.
A base deste modelo é o DeepSeek-V3-Base, uma arquitetura do tipo Mixture-of-Experts (MoE, mistura de especialistas) que contém 671 bilhões de parâmetros no total, embora apenas cerca de 37 bilhões sejam ativados em cada token gerado.
Essa arquitetura de especialistas permite escalar a capacidade do modelo sem um custo proporcional de inferência.
Além disso, ela suporta um contexto extremamente longo, de até 128 mil tokens, possibilitando ao DeepSeek-R1 processar entradas ou conversas muito extensas sem perda de coerência – uma janela de contexto bem acima da maioria dos modelos atuais.
No que tange ao treinamento, a série R1 enfatiza o aprendizado por reforço (RL) em larga escala para incentivar habilidades de raciocínio.
Primeiro, a equipe treinou o DeepSeek-R1-Zero aplicando RL diretamente sobre o modelo base (sem uma etapa preliminar de fine-tuning supervisionado).
Surpreendentemente, essa abordagem permitiu que o modelo desenvolvesse, por si só, comportamentos complexos de raciocínio, incluindo cadeias de pensamento longas, auto-verificação de respostas e reflexão sobre o problema.
Os pesquisadores ressaltam que o DeepSeek-R1-Zero foi o primeiro experimento aberto a demonstrar que LLMs podem adquirir capacidade de raciocínio puramente via RL, sem necessidade de SFT (fine-tuning supervisionado) – um feito que “abre caminho para futuros avanços na área”.
Contudo, o modelo resultante somente com RL apresentava algumas limitações, como tendência a repetições e respostas menos legíveis.
Para contornar esses problemas e refinar ainda mais a performance, o DeepSeek-R1 (versão completa) seguiu um pipeline de treinamento em múltiplas etapas: combinando duas fases de RL (uma focada em descobrir padrões aprimorados de raciocínio e outra em alinhar o modelo às preferências humanas via modelos de recompensa) intercaladas com duas fases de SFT (supervised fine-tuning convencional, fornecendo dados iniciais “cold start” para orientar tanto as habilidades de raciocínio quanto de linguagem geral).
Esse processo híbrido – primeiro deixar o modelo “pensar por conta própria” via reforço, depois ajustar com dados humanos e repetir – mostrou-se eficaz em produzir um sistema com alta capacidade de raciocínio e boa fluência linguística.
O resultado, DeepSeek-R1, atingiu desempenho comparável ao modelo OpenAI-o1 em tarefas diversas de matemática, código e lógica validando a eficácia do pipeline proposto.
Desempenho em Benchmarks Técnicos
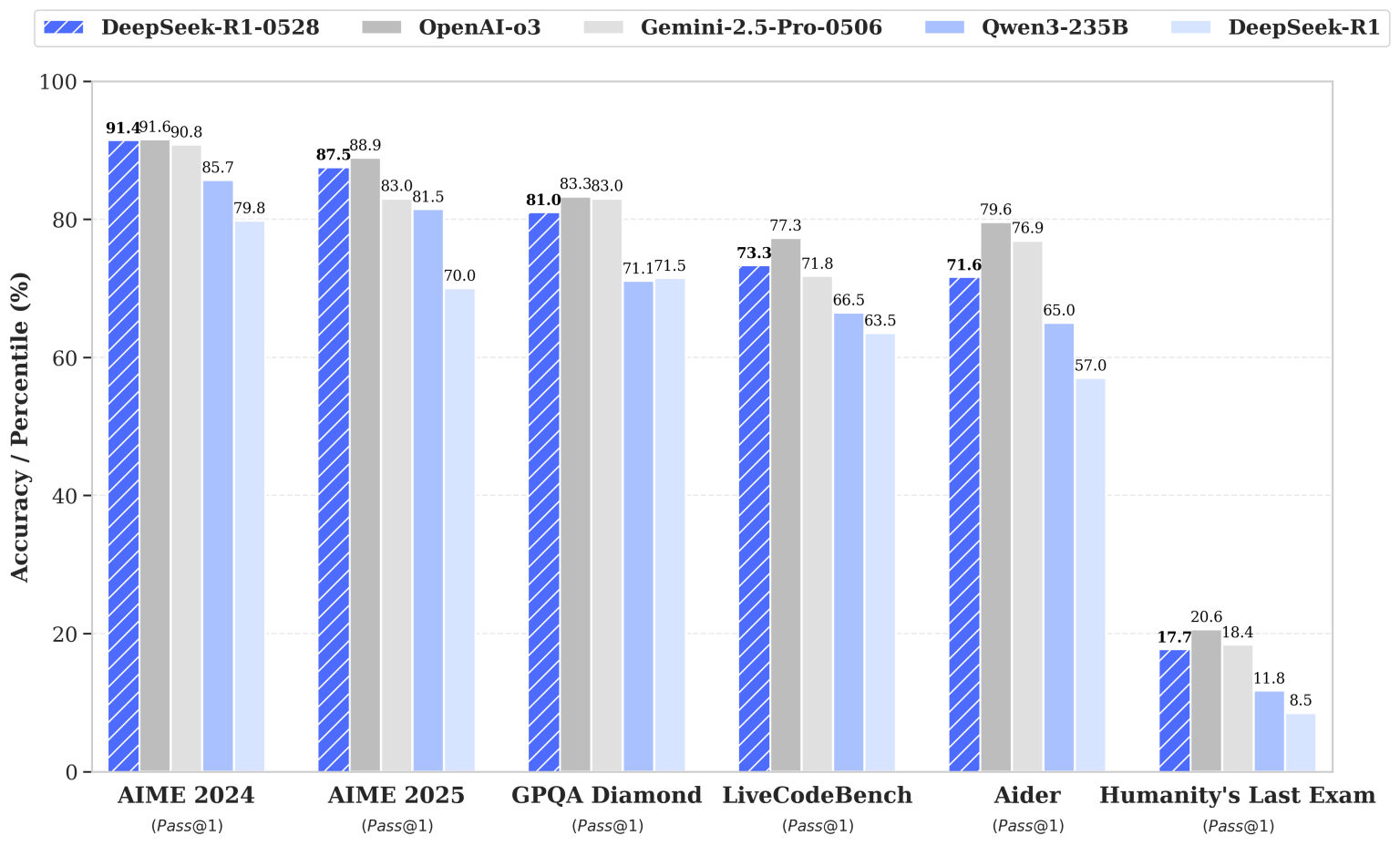
Comparativo de desempenho do DeepSeek-R1-0528 em benchmarks selecionados, em comparação a modelos de ponta (barras cinza: OpenAI-o3; roxo: Google Gemini-2.5-Pro-0506; azul claro: Qwen3-235B) e à versão anterior DeepSeek-R1 (azul claro, última barra). Métricas de acurácia ou percentil (Pass@1) em tarefas de matemática (AIME 2024/2025), Q&A avançado (GPQA Diamond), programação (LiveCodeBench), raciocínio assistido (Aider) e exame geral (Humanity’s Last Exam).
O DeepSeek-R1-0528 foi submetido a uma bateria de benchmarks padronizados, evidenciando ganhos substanciais sobre a versão anterior em múltiplas categorias.
Em matemática avançada, o modelo agora supera 90% de acurácia no exame AIME 2024 (saltando de 79,8% para 91,4%) e quase dobrou sua taxa de acerto no exigente desafio HMMT 2025 (de 41,7% para 79,4%).
No AIME 2025, como citado, atingiu 87,5% (vs. 70% antes), aproximando-se do nível dos melhores modelos fechados.
Já no campeonato chinês CNMO 2024, chegou a 86,9% (antes 78,8%), demonstrando ampla melhoria em problemas matemáticos de alta complexidade.
Em tarefas de programação e engenharia de software, o R1-0528 também apresentou avanços notáveis.
Seu desempenho no LiveCodeBench – conjunto de problemas de codificação ao vivo – subiu para 73,3% de acerto (ante 63,5% previamente).
Em desafios de algoritmos competitivos (Codeforces Divisão 1), o rating estimado do modelo foi elevado de ~1530 para 1930, indicando soluções mais corretas e eficientes.
Além disso, em um teste de depuração de código conhecido como SWE Verified, a proporção de bugs resolvidos aumentou de 49,2% para 57,6%, e em um cenário de programação multilíngue (Aider-Polyglot), a acurácia saltou de 53,3% para 71,6% – um ganho expressivo que sugere maior habilidade em seguir instruções complexas e gerar código consistente em diferentes linguagens.
No domínio de conhecimento geral e raciocínio lógico, o modelo atingiu 81,0% no difícil benchmark de perguntas e respostas de lógica GPQA Diamond, ante 71,5% da versão anterior.
Embora testes como o MMLU mostrem apenas melhorias modestas (por exemplo, 85,0% vs 84,0% no conjunto profissional), o progresso em tarefas de raciocínio puro é mais pronunciado. No desafiador Humanity’s Last Exam, que simula questões de alto nível abrangendo diversos campos, o DeepSeek-R1-0528 alcançou 17,7% de acerto – mais que o dobro da versão anterior (8,5%).
Apesar de porcentagens absolutas ainda baixas nesse teste específico, a melhora rápida indica que o modelo está fechando a lacuna em relação aos líderes (que giram na faixa de 20% nesse desafio).
Também em tarefas de compreensão multi-turnos e uso de ferramentas (como o benchmark BFCL v3 e o Tau-Bench), o novo modelo passou a registrar resultados significativos – por exemplo, 37% de acurácia em diálogos multi-turno com busca em ferramentas, onde antes não obtinha pontuação mensurável.
Em suma, o DeepSeek-R1-0528 estabelece novos recordes de desempenho entre modelos abertos em diversos cenários de teste, aproximando-se ou até superando modelos proprietários semelhantes em vários indicadores.
Esses resultados reforçam a validade da abordagem de treinamento adotada e evidenciam o estado da arte alcançado pelo modelo em raciocínio matemático, geração de código e compreensão geral.
Novos Recursos e Redução de Alucinações
Além dos ganhos de desempenho puro, a atualização R1-0528 introduziu recursos e aprimoramentos funcionais importantes que melhoram a usabilidade do modelo, especialmente para desenvolvedores que desejam integrá-lo em aplicações.
Entre as novidades, destaca-se o suporte nativo a saída em formato JSON e a chamadas de função durante as gerações de texto.
Na prática, isso significa que o modelo pode retornar respostas estruturadas em JSON (útil para integração direta com sistemas) e pode interpretar instruções para invocar funções de uma API, facilitando a criação de agentes de IA que interajam com ferramentas externas de forma controlada.
Essas capacidades tornam a incorporação do DeepSeek-R1-0528 em pipelines de software mais simples e robusta, reduzindo a necessidade de post-processing complexo nas respostas.
O front-end e a interface de chat do modelo também foram refinados. A experiência de uso via plataforma oficial ganhou melhorias de responsividade e eficiência, resultando em interações mais fluidas segundo a DeepSeek.
Para os desenvolvedores que utilizam o modelo via API ou localmente, um ajuste significativo foi a remoção da necessidade de um token especial para ativar o “modo pensamento” do modelo.
Na versão anterior, era necessário prefixar a resposta com um marcador específico (por exemplo, uma tag <think>) para induzir o modelo a expor seu raciocínio passo a passo.
Agora, com as otimizações na arquitetura, o R1-0528 dispensa esse artifício, engajando-se automaticamente em cadeias de raciocínio quando apropriado.
Essa mudança simplifica a implementação e garante que o modelo utilize seu máximo potencial de raciocínio sem configurações adicionais – basta enviar a pergunta normalmente que o mecanismo interno de chain-of-thought será acionado de forma transparente.
Outro aspecto crucial aprimorado foi a redução da taxa de alucinações. Alucinações referem-se a respostas factualmente incorretas ou invenções desconectadas da pergunta.
Com técnicas de reforço voltadas à verdade factual e filtros mais apurados, o DeepSeek-R1-0528 apresenta respostas mais confiáveis e consistentes, o que é especialmente valioso em cenários como assistentes inteligentes e aplicações profissionais onde precisão é mandatória.
Em conjunto com isso, o modelo demonstrou melhor manutenção de contexto em conversas longas, graças à janela de 128k tokens e a estratégias de cache de contexto apresentadas em releases anteriores.
Em suma, a atualização não apenas tornou o modelo mais inteligente, mas também mais prático para uso real, ao adicionar recursos demandados pela comunidade e melhorar a segurança e coerência das respostas.
Open-Source e Disponibilidade
Um dos diferenciais do DeepSeek-R1-0528 é a sua natureza open-source e a disponibilidade ampla para a comunidade.
Assim como a versão R1 inicial, o modelo 0528 está licenciado sob MIT License, uma licença permissiva que permite uso comercial, modificação e redistribuição livre.
A DeepSeek disponibilizou os pesos completos do modelo publicamente através do Hub da Hugging Face, facilitando para pesquisadores baixarem e executarem a IA em suas próprias infraestruturas.
A documentação técnica detalhada também está acessível no repositório GitHub do projeto, incluindo instruções para configuração local e exemplos de integração via API.
Para quem prefere usar a solução pronta na nuvem, a DeepSeek manteve seu serviço de API compatível com OpenAI.
Usuários atuais da API tiveram suas instâncias automaticamente atualizadas para utilizar o modelo R1-0528 sem custo adicional.
Novos usuários podem testar gratuitamente o modelo através do site oficial de chat (chat.deepseek.com), que agora conta com o modo “DeepThink” aprimorado.
Vale notar que a DeepSeek opera um modelo de custos significativamente baixo: de acordo com a empresa, o custo por milhão de tokens de entrada na API é de apenas $0,14 (com descontos em horários ociosos) – uma fração do custo das APIs de modelos proprietários de desempenho similar.
Isso reforça o compromisso da DeepSeek em democratizar o acesso a modelos avançados de IA, removendo barreiras financeiras e de licenciamento.
Outra contribuição importante do lançamento foi a disponibilização de variantes menores do modelo, obtidas via distilação.
A equipe liberou seis modelos dense de menor porte, com tamanhos de 1.5B, 7B, 8B, 14B, 32B e 70B parâmetros, todos treinados a partir do DeepSeek-R1 usando bases abertas consagradas (como Qwen 2.5 e Llama 3 series).
Essas versões distilled retêm em boa parte os padrões de raciocínio do modelo grande, mas podem ser executadas em hardware bem mais modesto.
Por exemplo, a variante DeepSeek-R1-0528-Qwen3-8B (8 bilhões de parâmetros) alcança state-of-the-art entre modelos abertos de seu porte – superando o Qwen-8B original em 10% no teste AIME 2024 – e pode rodar integralmente em uma única GPU de 16 GB (ou até em placas de 8–12 GB usando quantização).
Isso viabiliza experimentos e aplicações em instituições acadêmicas e empresas com recursos computacionais limitados, ampliando o alcance do modelo.
Nas palavras da própria DeepSeek, a disponibilidade dessas versões enxutas deve “empoderar a comunidade” e possibilitar tanto pesquisas em raciocínio quanto usos industriais em escala menor.
Em suma, o DeepSeek-R1-0528 mantém-se 100% aberto e colaborativo, com um ecossistema de suporte que inclui fórum comunitário, canal Discord ativo e documentação completa.
A empresa incentiva usuários a fornecer feedback e compartilhar casos de uso, evidenciando uma filosofia de desenvolvimento conjunta com a comunidade..
Essa postura transparente contrasta com os modelos proprietários de ponta, e sugere que a inovação em IA pode prosperar também em modelos abertos de classe mundial.
Declarações dos Desenvolvedores
Os desenvolvedores do DeepSeek enfatizaram o caráter inovador e a missão por trás do modelo R1-0528. Em seu relatório técnico, a equipe afirma que o DeepSeek-R1 “atinge desempenho comparável ao OpenAI-o1 em tarefas de matemática, código e raciocínio”, reforçando que seu método de treinamento foi validado ao equiparar um modelo aberto com os melhores resultados dos sistemas fechados.
Eles destacam ainda a importância do uso de aprendizado por reforço puro no processo, assinalando que o projeto DeepSeek-R1-Zero representou “o primeiro experimento aberto a validar que capacidades de raciocínio de LLMs podem ser incentivadas puramente via RL, sem a necessidade de SFT”.
Essa visão reflete a confiança dos pesquisadores de que novas estratégias de treinamento, aliadas à abertura do código, podem impulsionar o estado da arte de forma colaborativa.
Embora o foco principal seja técnico, a equipe também enxerga implicações maiores na disponibilização de um modelo de ponta aberto.
Em entrevistas, o fundador Liang Wenfeng sugeriu que a abordagem da DeepSeek busca “deixar de seguir, para liderar” no cenário de IA, indicando a ambição de colocar a China e a comunidade open-source na vanguarda da pesquisa em modelos de linguagem avançados.
A receptividade da comunidade até agora valida esse objetivo – a atualização R1-0528 rapidamente gerou entusiasmo entre desenvolvedores e entusiastas nas redes sociais, com comentários destacando que o modelo “está quase no nível do o3 e Gemini 2.5” e demonstra capacidades impressionantes especialmente em programação.
Para a DeepSeek, essas reações confirmam que seu esforço em unir alta performance com transparência e abertura está no caminho certo.
Aplicações Potenciais e Futuro
Com suas melhorias técnicas e licença aberta, o DeepSeek-R1-0528 abre uma série de possibilidades de aplicação tanto em pesquisa quanto na indústria.
Sua aptidão para resolver problemas matemáticos complexos sugere uso em tutoriais inteligentes, assistentes educacionais ou mesmo descobertas científicas auxiliadas por IA, onde é necessário manipular cadeias lógicas extensas.
A evolução significativa em geração de código torna o modelo um candidato atraente para servir como assistente de programação, auxiliando desenvolvedores a escrever, depurar e analisar código em múltiplas linguagens de forma eficiente.
Empresas podem incorporar o R1-0528 em ferramentas de DevOps ou IDEs, aproveitando o suporte a chamadas de função para que o modelo execute ações diretas em ambientes controlados.
Na área de processamento de linguagem natural geral, o DeepSeek-R1-0528 pode atuar como motor de chatbots avançados, capazes de conduzir diálogos de atendimento ao cliente ou consultoria interna que requeiram raciocínio complexo e respostas precisas baseadas em grande contexto (por exemplo, análise de documentos extensos, relatórios financeiros ou artigos acadêmicos inteiros, graças ao contexto de 128k tokens).
Pesquisadores acadêmicos, por sua vez, podem usar o modelo como um alicerce para novas pesquisas: seja para estudar como o chain-of-thought emergente via RL melhora o desempenho, seja para realizar fine-tuning em domínios específicos (médico, jurídico, científico) tirando proveito da base poderosa já treinada.
O fato de a comunidade poder inspecionar e modificar o modelo permite também trabalhos em interpretabilidade e alinhamento ético, visando compreender melhor as decisões internas do modelo de raciocínio.
Importante frisar que a disponibilidade de versões menores (distilled) expande o leque de usos para dispositivos e servidores menos robustos – por exemplo, possibilitando rodar um assistente avançado offline num laptop de alto desempenho ou em um servidor local, aumentando a privacidade e controle sobre os dados.
Pequenas e médias empresas (PMEs) podem adotar o DeepSeek-R1-0528 como sua IA fundamental personalizada, adaptando-o às suas necessidades particulares sem os custos elevados ou riscos de dependência de APIs de terceiros.
No horizonte, a comunidade especula que esta versão pode ser o último grande aprimoramento da série “R1”, possivelmente preparando terreno para um futuro DeepSeek-R2.
Independentemente dos próximos lançamentos, o DeepSeek-R1-0528 já se consolidou como um marco: um modelo de IA de alto desempenho em raciocínio, open-source e acessível, que demonstra na prática o potencial de unir pesquisa avançada e colaboração aberta.
Para os pesquisadores em inteligência artificial, ele representa tanto uma ferramenta de ponta disponível para experimentação imediata quanto um case de estudo sobre até onde métodos inovadores (como RL em larga escala) podem levar os modelos de linguagem modernos.
Em suma, o DeepSeek-R1-0528 não é apenas uma atualização incremental, mas um avanço substancial que reforça a posição da DeepSeek e da comunidade de IA aberta na fronteira da inovação em modelos de linguagem.


