
O DeepSeek V3.2-Exp é um modelo de linguagem de inteligência artificial de última geração, projetado para lidar com contextos extremamente longos (até 128 mil tokens) e oferecer capacidades avançadas de raciocínio e interação com ferramentas externas. Trata-se de um modelo experimental de alto desempenho, disponibilizado pela empresa DeepSeek, que visa explorar novos avanços em eficiência de processamento e usabilidade para desenvolvedores. Em outras palavras, o DeepSeek V3.2-Exp traz melhorias significativas que permitem analisar e gerar texto em janelas de contexto muito amplas, com rapidez e custo reduzido, sem perder a qualidade nas respostas.
Na prática, a proposta do DeepSeek V3.2-Exp é viabilizar aplicações que antes eram limitadas pelo tamanho do contexto ou pelo custo computacional. Sua arquitetura incorpora inovações como o mecanismo DeepSeek Sparse Attention (DSA), que otimiza a maneira como o modelo “presta atenção” às partes relevantes de entradas longas. Além disso, o modelo suporta um modo de raciocínio encadeado (com cadeia de pensamentos interna) e integração com ferramentas externas via chamadas de função. Tudo isso o torna especialmente interessante para desenvolvedores e equipes de tecnologia que precisam trabalhar com grandes volumes de texto, construir agentes autônomos inteligentes ou fornecer assistentes virtuais mais contextuais e poderosos.
A seguir, vamos detalhar as características técnicas do DeepSeek V3.2-Exp, seus casos de uso práticos, exemplos de utilização com código, formas de integração (via API ou localmente), benefícios para equipes de engenharia e produto, melhores práticas de uso, considerações de desempenho e limitações, encerrando com uma conclusão que convida à experimentação com esse modelo inovador.
Características Técnicas do DeepSeek V3.2-Exp
Janela de contexto de 128K tokens
Uma das características mais marcantes do DeepSeek V3.2-Exp é o suporte a uma janela de contexto de até 128 mil tokens – um patamar muito superior ao dos modelos de linguagem tradicionais. Em termos práticos, isso significa que o modelo consegue processar entradas de texto muito extensas, equivalentes a centenas de páginas ou vários documentos concatenados, em uma única consulta. Essa capacidade é confirmada pela especificação do modelo na documentação da API DeepSeek, que indica context length = 128K tokens.
Com 128K de contexto, tarefas que envolvem analisar documentos longos, conversas prolongadas ou grandes bases de conhecimento tornam-se possíveis sem necessidade de dividir o texto em partes menores. Por exemplo, é factível fornecer ao modelo um dossiê inteiro, código-fonte extenso ou um log de conversação enorme, e ainda assim obter uma resposta contextualizada considerando todas as informações relevantes. Essa amplitude de contexto reduz a dependência de técnicas de resumir ou fazer chunking do input, permitindo soluções mais diretas e simples.
É importante destacar que, para viabilizar esse contexto extenso sem explodir o custo computacional, o DeepSeek V3.2-Exp emprega otimizações especiais de atenção esparsa (detalhadas a seguir). Na prática, os desenvolvedores podem aproveitar a janela de 128K tokens de forma eficiente, sem sacrificar desempenho ou gastar fortunas em computação, desde que usem as estratégias adequadas oferecidas pelo modelo.
DeepSeek Sparse Attention (DSA) – Atenção esparsa otimizada
O DeepSeek Sparse Attention (DSA) é a inovação técnica central introduzida no V3.2-Exp e o principal responsável por permitir o longo contexto e a eficiência do modelo. Em modelos de linguagem tradicionais, o mecanismo de atenção geralmente possui complexidade quadrática em relação ao comprimento da sequência de entrada (O(n²)), o que se torna inviável para n = 128.000 tokens. O DSA contorna esse limite aplicando atenção esparsa e seletiva, alcançando uma complexidade quase linear em relação ao tamanho do contexto. Em termos simples, o modelo não tenta olhar para todos os tokens a todo momento, mas sim foca nos trechos mais relevantes de forma hierárquica.
Como isso funciona internamente? De acordo com descrições técnicas, o DSA utiliza um módulo chamado “lightning indexer” para priorizar trechos específicos da janela de contexto que parecem mais importantes, e em seguida um sistema de “seleção fina de tokens” dentro desses trechos para determinar quais tokens realmente importam para a próxima etapa do processamento. Em conjunto, esses mecanismos permitem que o modelo ignore dados supérfluos e concentre seus recursos computacionais apenas no conteúdo de maior relevância, reduzindo drasticamente a carga de cálculo sem perder de vista informações cruciais.
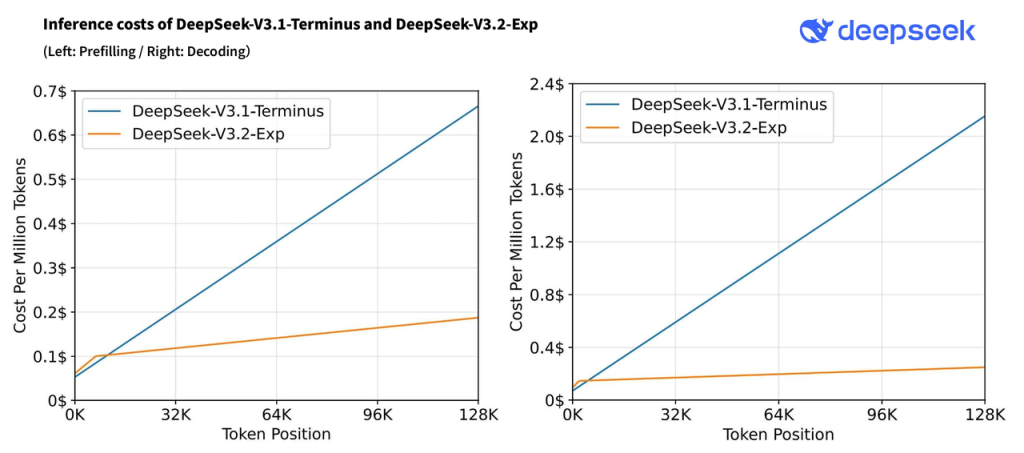
Os ganhos de eficiência são significativos: testes iniciais da DeepSeek mostraram que, graças ao DSA, o custo de uma chamada de API em cenários de contexto longo caiu pela metade ou mais. Em outras palavras, a inferência ficou ~50% mais barata em tarefas de contexto extenso, comparado a modelos anteriores de atenção densa. Isso sem degradação perceptível na qualidade das respostas, já que o V3.2-Exp manteve desempenho equivalente ao modelo predecessor nos benchmarks avaliados. O DSA consegue esse equilíbrio entregando melhor eficiência de treinamento e inferência em contexto longo, ao mesmo tempo em que mantém a qualidade de saída virtualmente idêntica à de um transformador padrão.
Em resumo, a Atenção Espassa do DeepSeek V3.2-Exp é um divisor de águas que habilita o uso prático de janelas de contexto gigantes. Para os desenvolvedores, isso significa poder escalar aplicações de NLP para trabalhar com lotes enormes de texto ou conhecimento, com custo e tempo de resposta viáveis, algo que antes demandaria infraestrutura proibitivamente cara. O DSA exemplifica uma tendência de inovação em modelos de linguagem: em vez de apenas aumentar parâmetros, busca-se tornar o processamento mais inteligente e econômico, tornando este modelo especialmente relevante em 2025.
Modelo de larga escala com Mixture-of-Experts (MoE)
Nos bastidores, o DeepSeek V3.2-Exp é um modelo de linguagem massivo em termos de parâmetros, utilizando arquitetura do tipo Mixture-of-Experts. De acordo com relatórios técnicos, ele possui na ordem de 671 a 685 bilhões de parâmetros no total, embora apenas uma fração seja ativada para qualquer token específico. Isso indica que o modelo é composto por múltiplos especialistas – redes neurais subcomponentes especializadas – e para cada consulta ele seleciona dinamicamente quais especialistas serão usados para aquele token. Por exemplo, pode haver centenas de “especialistas” e apenas alguns (digamos ~37 bilhões de parâmetros equivalentes) são efetivamente utilizados por token, conforme sugerido pelo paper do DeepSeek-V3.
Essa arquitetura de Mixture-of-Experts (MoE) permite escalar o modelo para um número colossal de parâmetros sem custear proporcionalmente cada inferência, pois nem todos os pesos são usados ao mesmo tempo. O DeepSeek V3.2-Exp preservou a arquitetura de 685B do v3.1-Terminus como base, incorporando o mecanismo esparso por cima.
Para os desenvolvedores, o que importa é que o modelo é extremamente poderoso e abrangente em conhecimento, dado seu tamanho, mas foi projetado para ser eficiente no uso dos recursos graças à combinação de MoE + atenção esparsa. Isso também implica que rodá-lo localmente requer hardware de ponta (GPUs de última geração, com suporte a tensor cores e possivelmente precisão FP8) ou o uso do serviço em nuvem da DeepSeek. Em suma, o V3.2-Exp consegue ser “enxuto” no tempo de execução apesar de seu tamanho bruto, o que é um feito de engenharia notável.
Raciocínio encadeado (Chain-of-Thought) e modos de uso
Outra funcionalidade chave do DeepSeek V3.2-Exp é o suporte nativo a raciocínio encadeado, também conhecido como Chain-of-Thought (CoT). O modelo possui dois modos de operação principais na API:
- Modo “Chat” (não pensante): corresponde ao endpoint
deepseek-chat, onde o modelo gera diretamente a resposta final para a consulta do usuário, de forma rápida e direta. Este é o modo mais similar a um chat comum, otimizado para throughput e custo menor em tarefas simples. - Modo “Raciocínio” (pensante): corresponde ao endpoint
deepseek-reasoner, onde antes de entregar a resposta final o modelo primeiro produz uma cadeia de raciocínio interna (CoT) para chegar à conclusão. Esse modo é útil para perguntas complexas ou problemas que requerem vários passos de dedução, pois o modelo literalmente “pensa em voz alta” (internamente) e só então responde. A saída da API nesse caso fornece tanto o reasoning_content (o conteúdo do raciocínio passo a passo) quanto o content final.
A vantagem do modo de raciocínio é aumentar a precisão e transparência em tarefas complexas, uma vez que podemos inspecionar o pensamento intermediário do modelo e até exibi-lo ao usuário se desejado. Por exemplo, ao perguntar um problema matemático ou lógico, o deepseek-reasoner pode retornar sua linha de pensamento detalhada (cálculos, suposições, verificação de condições) antes de dar a resposta, o que ajuda a entender como chegou naquele resultado. Esse recurso pode ser extremamente útil para aplicações educacionais, verificações de consistência ou depuração de respostas da IA.
Do ponto de vista técnico, para usar o modo pensante é necessário utilizar o modelo deepseek-reasoner via API, e adequar-se a algumas particularidades: ele suporta mensagens multi-turn normalmente, mas não é compatível com chamadas de função ou certos ajustes de temperatura. Ou seja, o foco do reasoner é puramente o raciocínio textual.
Se o desenvolvedor incluir parâmetros de ferramenta no request deste modo, a API automaticamente cairá de volta para o modelo de chat normal. Portanto, use o modo raciocínio para obter CoT e respostas acuradas, e o modo chat para interações convencionais ou quando precisar de ferramentas. Uma boa prática é reservar o reasoner para perguntas desafiadoras, enquanto consultas triviais ou de bate-papo podem ser resolvidas mais rapidamente com o chat – inclusive com menor custo de tokens (o raciocínio gera respostas mais longas, consumindo mais tokens).
Uso de ferramentas e integração com agentes (Function Calling)
O DeepSeek V3.2-Exp também se destaca por oferecer recursos para integração com ferramentas externas via chamadas de função, de forma análoga à funcionalidade Function Calling da API OpenAI. Isso significa que o modelo pode atuar como um agente que invoca funções definidas pelo desenvolvedor – por exemplo, consultar uma API de clima, executar um cálculo, acessar uma base de dados – para complementar suas respostas com ações ou informações dinâmicas.
Na prática, a API do DeepSeek permite que você descreva tools (ferramentas) em formato JSON, incluindo nome da função, parâmetros esperados e descrição. Ao receber uma pergunta do usuário que demanda usar uma dessas ferramentas, o modelo pode retornar no seu output uma chamada de função estruturada (com o nome e parâmetros preenchidos) em vez de uma resposta em linguagem natural. O controle então volta para o seu código, que deve executar a função real (por exemplo, fazer a requisição de clima) e fornecer o resultado de volta ao modelo. Em seguida, o modelo gera a resposta final para o usuário usando o resultado obtido. Esse fluxo já vem suportado nativamente: a resposta do modelo contém um campo tool_calls indicando as chamadas de ferramenta feitas, e você pode iterar conforme necessário até a conclusão do task.
Um exemplo simples: imagine que o usuário pergunte “Qual a temperatura atual em São Paulo?”. Com uma função get_weather(location) registrada, o DeepSeek V3.2-Exp pode responder primeiro com algo como get_weather({"location": "São Paulo"}) em vez de dar a temperatura diretamente. Seu sistema então detecta essa intenção, chama uma API meteorológica real passando “São Paulo”, obtém digamos 25°C e envia de volta para o modelo esse resultado (num papel de mensagem especial de ferramenta). O modelo finalmente responde ao usuário: “Em São Paulo agora está fazendo 25°C.”. Todo esse ciclo ocorre de forma suave, com o modelo decidindo quando e qual ferramenta usar de acordo com a necessidade.
Para os desenvolvedores, esse recurso abre possibilidades de criar agentes autônomos e assistentes extremamente capazes, combinando o entendimento de linguagem do modelo com ações no mundo real. Você pode conectar funções de calculadora, pesquisa na web, banco de dados, comandos de sistema, entre outros – permitindo que o modelo vá além do conhecimento estático e execute tarefas concretas. O DeepSeek V3.2-Exp suporta inclusive um modo estrito para validação rigorosa do formato JSON da função, garantindo que a saída siga o esquema definido. Isso ajuda a evitar erros de formatação nas chamadas de função.
Vale lembrar que o uso de ferramentas está disponível apenas no modo chat (não no modo reasoning, como mencionado). Porém, nada impede de construir um agente mais sofisticado externamente que combine ambos: por exemplo, usar o deepseek-chat para decisões de ferramenta e o deepseek-reasoner para reflexões estratégicas. De qualquer forma, a compatibilidade com function calling torna o V3.2-Exp altamente adequado para aplicações de agentes autônomos (autonomous agents), chatbots conectados a serviços e fluxos de trabalho de software onde a IA toma ações (como um copiloto de programação que cria arquivos, ou um assistente que reserva reuniões consultando uma agenda).
Outras funcionalidades e formatos suportados
Complementando o conjunto de recursos técnicos, o DeepSeek V3.2-Exp traz suporte a algumas funcionalidades adicionais úteis para desenvolvedores:
- Geração de respostas estruturadas (JSON Output): O modelo pode ser instruído a retornar a saída em formato JSON conforme um esquema desejado, útil para quando você precisa extrair informações de forma estruturada (por exemplo, extrair campos específicos de um texto). A documentação indica suporte a output JSON diretamente em ambos os modos de operação.
- Completação de conversas e preenchimento de código (Chat Prefix e FIM): O V3.2-Exp oferece modos beta para completar conversas a partir de um prefixo (Chat Prefix Completion) e completar trechos de código ausentes no meio de um arquivo (Fill-In-the-Middle, FIM). Essas capacidades são úteis em cenários como assistentes de código, onde o modelo pode preencher automaticamente a continuação de um diálogo de suporte ou inserir código dentro de um contexto dado.
- Compatibilidade com API OpenAI: Um detalhe importante é que a API do DeepSeek foi projetada para ser altamente compatível com o formato da API OpenAI. Isso significa que você pode usar bibliotecas clientes do OpenAI (como o SDK Python
openai) apenas ajustando obase_urle aapi_keypara a da DeepSeek. Até mesmo os campos de mensagem (role,content) e parâmetros comotemperature,max_tokensfuncionam de forma análoga. Dessa forma, migrar um projeto que use ChatGPT/GPT-4 para usar DeepSeek V3.2-Exp é relativamente simples, o que é um ponto a favor para adoção.
Em suma, nas características técnicas o DeepSeek V3.2-Exp se destaca pelo contexto gigantesco de 128K tokens, eficiência via atenção esparsa, um modelo de enorme capacidade (centenas de bilhões de parâmetros) otimizado por MoE, modos de raciocínio vs chat, e integração com ferramentas e formatos estruturados. Essa combinação faz dele uma plataforma flexível e poderosa para diversas aplicações de NLP modernas.
Casos de Uso Práticos
Com tantas capacidades, o DeepSeek V3.2-Exp habilita diversos casos de uso práticos que antes seriam difíceis ou impossíveis de realizar com modelos menores ou menos eficientes. Abaixo listamos alguns exemplos relevantes para desenvolvedores e profissionais de tecnologia:
- Análise de documentos extensos e sumarização: Graças à janela de 128K tokens, é possível fornecer ao modelo documentos longuíssimos – como relatórios corporativos, teses, contratos jurídicos ou até livros inteiros – e obter análises ou resumos coerentes. O DeepSeek V3.2-Exp consegue ler toda a informação de uma vez e extrair os pontos-chave, responder perguntas detalhadas sobre o conteúdo ou gerar um resumo executivo preciso, sem que seja necessário dividir manualmente o texto. Isso é valioso em contextos como pesquisa acadêmica, compliance legal ou revisão de documentos técnicos volumosos.
- Assistentes de programação com contexto completo: Desenvolvedores podem usar o V3.2-Exp como um “copiloto” de código que carrega o contexto de um projeto inteiro ou vários arquivos de código simultaneamente. Imagine poder fornecer ao modelo todo o repositório de um projeto (até 100 mil tokens de código) e perguntar sobre como determinadas funções interagem, pedir geração de código novo consistente com o estilo do projeto, ou localizar bugs baseando-se em múltiplos arquivos. Com 128K de janela, o modelo pode conter em memória toda a base relevante para dar respostas ou sugestões de código mais acuradas. Além disso, usando Fill-in-the-Middle, pode preencher partes faltantes em um trecho de código dentro de um arquivo.
- Chatbots e assistentes com memória longa: Para aplicações de atendimento ao cliente ou assistentes virtuais, ter uma memória longa é crucial. O DeepSeek V3.2-Exp permite manter históricos de conversas extremamente longos sem perder o contexto das interações anteriores. Isso significa que um chatbot pode lembrar de detalhes discutidos há dezenas de interações atrás, proporcionando uma experiência de conversa muito mais consistente e personalizada para o usuário. Em suporte técnico, por exemplo, o modelo poderia acompanhar toda a jornada do cliente em uma única sessão e evitar perguntas repetitivas, referenciando corretamente informações fornecidas anteriormente.
- Agentes autônomos e virtual assistants: Com a capacidade de raciocinar e usar ferramentas, o modelo serve como cérebro de agentes autônomos (AutoGPT-like). Por exemplo, se você construir um agente de pesquisa, ele pode elaborar um plano internamente (usando raciocínio CoT) e em seguida chamar ferramentas de busca web, calculadoras ou APIs diversas para reunir dados, refinando seu plano em múltiplas iterações. Casos de uso como assistentes pessoais digitais, agentes de pesquisa científica, bots de automação de tarefas (devops, marketing) etc., se beneficiam de um modelo que pode não só conversar, mas agir. O V3.2-Exp torna viável manter um grande contexto de objetivos, sub-tarefas concluídas e conhecimento adquirido pelo agente durante sua operação, algo essencial para agentes que funcionam ao longo de horas ou dias.
- Sistema de perguntas e respostas sobre base de conhecimento: Muitas empresas possuem grandes bases de conhecimento, FAQs, wikis internas ou coleções de documentos. Com o DeepSeek V3.2-Exp, pode-se carregar uma quantidade massiva dessas informações diretamente no prompt e então realizar Q&A sobre elas. Diferente de precisar implementar uma pipeline de recuperação de documentos e múltiplas chamadas ao modelo, aqui você pode literalmente inserir dezenas de páginas de referência num só prompt e perguntar “Com base no manual X e na política Y, o que devo fazer em caso de Z?”. O modelo consegue fazer o papel de um especialista que leu todo o material de apoio e responde à pergunta com citações ou referências ao conteúdo, se necessário. Esse caso de uso abrange desde atendimento ao cliente (respostas baseadas na documentação do produto) até suporte interno de TI ou RH (políticas internas, manuais técnicos etc.).
- Geração de textos longos e coerentes: Se a tarefa é gerar um documento longo – um artigo extenso, um capítulo de livro, um relatório completo – a grande janela de contexto do DeepSeek V3.2-Exp permite que o próprio modelo tenha visibilidade do texto que já produziu e mantenha coerência do começo ao fim. Você pode, por exemplo, iterativamente construir um documento de 50 páginas, sempre retornando o conteúdo já escrito junto com novas instruções, sem que o modelo “esqueça” o que foi escrito nos capítulos iniciais. Isso é especialmente útil para redação assistida, onde o usuário junto com a IA produzem um texto grande mantendo consistência de estilo e conteúdo. Da mesma forma, para geração de histórias ou roteiros, o modelo pode gerir muitos detalhes de enredo espalhados ao longo do texto.
- Aplicações de Retrieval-Augmented Generation (RAG): O V3.2-Exp torna mais barato e eficiente implementar RAG, em que o modelo recebe documentos relevantes concatenados ao prompt para gerar respostas informadas. Devido ao DSA, mesmo inserindo muitas fontes de dados como contexto, o custo e tempo de inferência se mantêm gerenciáveis, cerca de linear no tamanho total. Assim, soluções de busca semântica + LLM para domínios específicos (jurídico, saúde, finanças) podem escalar para conjuntos maiores de documentos por consulta, antes inimagináveis. Desenvolvedores podem usar essa vantagem para criar chatbots que leem centenas de páginas de resultados de busca ou artigos e respondem ao usuário com síntese precisa, sem extrapolar o orçamento de inferência.
Em resumo, o DeepSeek V3.2-Exp habilita novas aplicações ou melhora drasticamente outras já conhecidas nas áreas de Processamento de Linguagem Natural. A possibilidade de trabalhar com textos longos, realizar múltiplos passos de raciocínio e interagir com ferramentas faz dele um game changer para aplicações que exigem compreensão profunda e ações complexas. Os exemplos acima são apenas ilustrativos – a criatividade dos desenvolvedores certamente encontrará ainda mais usos inovadores para esse modelo.
Exemplos de Uso (com Trechos de Código)
Para ilustrar como interagir com o DeepSeek V3.2-Exp, vamos apresentar alguns exemplos de uso práticos, incluindo chamadas de API e integração local. Os exemplos estarão em Python, usando tanto a API REST (via requisição HTTP) quanto a biblioteca compatível com OpenAI, já que o DeepSeek suporta esse formato.
1. Consulta básica via API (OpenAI SDK)
Conforme mencionado, podemos usar o SDK do OpenAI em Python para consumir a API da DeepSeek apenas ajustando a base URL e o modelo. Suponha que você já tenha obtido sua chave de API do DeepSeek (DEEPSEEK_API_KEY). O exemplo abaixo demonstra uma chamada simples ao modelo em modo chat:
import openai
# Configurar chave e endpoint da DeepSeek (compatível com OpenAI SDK)
openai.api_key = "SUA_API_KEY_AQUI"
openai.api_base = "https://api.deepseek.com/v1" # usar v1 para compatibilidade OpenAI
# Mensagens de exemplo: sistema define contexto, usuário faz uma pergunta
mensagens = [
{"role": "system", "content": "Você é um assistente útil e especialista em geografia."},
{"role": "user", "content": "Qual é a montanha mais alta do Brasil?"}
]
# Chamada à API DeepSeek usando modelo de chat (não pensante)
resposta = openai.ChatCompletion.create(
model="deepseek-chat",
messages=mensagens,
temperature=0.7, # pode ajustar parâmetros normalmente
max_tokens=512 # limitar tamanho da resposta
)
print(resposta.choices[0].message.content)
No exemplo acima, enviamos uma instrução de sistema definindo o papel do modelo e uma pergunta simples do usuário. Utilizamos o modelo "deepseek-chat", que corresponde ao DeepSeek V3.2-Exp em modo padrão de bate-papo. A resposta retornada (resposta.choices[0].message.content) conterá o texto respondido pelo modelo. Note que configuramos api_base para api.deepseek.com/v1 e usamos nossa API key da DeepSeek – isso é suficiente para direcionar o SDK do OpenAI a usar o endpoint do DeepSeek. Por trás dos panos, a compatibilidade é tamanha que até mesmo classes e métodos do OpenAI SDK funcionam (como ChatCompletion.create).
2. Habilitando raciocínio (Chain-of-Thought) na resposta
Agora, suponha que queremos usar o modo de raciocínio encadeado para ver o passo a passo do modelo ao responder uma pergunta desafiadora. Podemos fazer quase a mesma chamada acima, trocando o modelo para "deepseek-reasoner":
resposta = openai.ChatCompletion.create(
model="deepseek-reasoner",
messages=[{"role": "user", "content": "Se 9.11 e 9.8, qual é maior?"}]
)
# A resposta do reasoner contém dois campos: reasoning_content e content
resposta_cadeia = resposta.choices[0].message.reasoning_content
resposta_final = resposta.choices[0].message.content
print("Cadeia de raciocínio:\n", resposta_cadeia)
print("Resposta final:\n", resposta_final)
Nesse exemplo, enviamos uma questão numérica para comparar 9.11 e 9.8. O modelo reasoner primeiro geraria uma cadeia de raciocínio (por exemplo, “9.11 é um valor numérico maior do que 9.8, logo 9.11 > 9.8.”) e depois daria a resposta final (“9.11 é maior.”). No objeto resposta, acessamos message.reasoning_content para obter a cadeia de pensamento e message.content para a resposta final. Assim, podemos logar ou apresentar ambos se quisermos. Vale lembrar que no modo reasoner não devemos inserir o campo reasoning_content de volta na próxima pergunta – a API não espera recebê-lo como entrada e retornará erro se o encontrar no contexto. Portanto, ao implementar diálogos multi-turn, devemos filtrar esse campo ao construir a lista de mensagens do próximo turno (mantendo apenas o content respondido).
3. Chamadas de função (Function Calling) – integração com ferramenta
Para demonstrar o uso de ferramentas, vamos usar o exemplo da consulta do clima abordado anteriormente. Precisamos definir a função no parâmetro tools da requisição e então seguir o loop de execução:
from openai import OpenAI
# Definir a função disponíveis para o modelo (get_weather)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Obter a temperatura atual de uma cidade específica.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "Cidade e país ou estado, por exemplo: São Paulo, BR"
}
},
"required": ["location"]
}
}
}
]
client = OpenAI(api_key="SUA_API_KEY", base_url="https://api.deepseek.com")
mensagens = [{"role": "user", "content": "Como está o tempo agora em São Paulo, Brasil?"}]
# Envia a mensagem com definição da ferramenta
resposta_inicial = client.chat.completions.create(
model="deepseek-chat",
messages=mensagens,
tools=tools
)
print("Modelo respondeu (chamada de ferramenta):", resposta_inicial.message.tool_calls[0])
# Supondo que extraiu-se o 'location' e consultou-se uma API de clima, obtendo por ex. "25°C"
resultado_funcao = "25°C"
# Adiciona a resposta da ferramenta como nova mensagem de role "tool"
tool_call_id = resposta_inicial.message.tool_calls[0].id
mensagens.append(resposta_inicial.message) # resposta do modelo (função chamada)
mensagens.append({"role": "tool", "tool_call_id": tool_call_id, "content": resultado_funcao})
# Chama novamente o modelo com o resultado da ferramenta
resposta_final = client.chat.completions.create(
model="deepseek-chat",
messages=mensagens,
tools=tools
)
print("Resposta final do modelo:", resposta_final.message.content)
No código acima, definimos uma ferramenta get_weather que espera um parâmetro “location”. Quando perguntamos sobre o clima em São Paulo, o modelo entende que precisa usar essa ferramenta e retorna uma chamada get_weather({"location": "São Paulo, Brasil"}) em resposta_inicial.message.tool_calls[0]. Em seguida, simulamos a execução real da função (que deveria consultar um serviço meteorológico) e fornecemos de volta a resposta da ferramenta (“25°C”) ao modelo, marcando-a com role: "tool" e referenciando o tool_call_id original. Por fim, na segunda chamada, o modelo reconhece que recebeu o resultado da função e produz uma resposta em língua natural, por exemplo: “A temperatura em São Paulo, Brasil, é de aproximadamente 25°C agora.”.
Esse fluxo manual exemplifica como integrar ferramentas. Em um cenário real, você coordenaria esse loop (talvez com funções auxiliares) de modo que a cada iteração verifique se o modelo solicitou alguma ferramenta (message.tool_calls não vazio) e trate adequadamente antes de prosseguir. Observe que configuramos tools em ambas as chamadas para informar ao modelo quais funções estão disponíveis. O modelo DeepSeek V3.2-Exp cuida de manter o formato correto e, no modo estrito, até valida se o JSON retornado se ajusta ao esquema definido – o que traz robustez à integração.
4. Executando o modelo localmente (exemplo com Hugging Face Transformers)
Por ser um modelo de código aberto (open-weight), também é possível baixar os pesos do DeepSeek V3.2-Exp e executá-lo localmente ou on-premises, desde que você tenha hardware compatível. Os pesos estão disponíveis sob licença MIT no Hugging Face, embora rodar este modelo seja não trivial devido ao seu porte (centenas de bilhões de parâmetros).
Uma forma recomendada de uso local é via integração com frameworks especializados, como o vLLM, que oferece suporte ao V3.2-Exp desde o dia do lançamento. O vLLM é otimizado para servir modelos grandes com eficiências de memória e velocidade, sendo ideal para aproveitar a atenção esparsa. Outra opção é usar containers prontos fornecidos (havia imagens Docker preparadas, por exemplo, via projeto SGLang). A seguir, damos um exemplo simplificado usando a biblioteca Transformers da Hugging Face, apenas para ilustrar:
from transformers import AutoTokenizer, AutoModelForCausalLM
# Carregar tokenizer e modelo (atenção: o modelo completo é enorme)
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-V3.2-Exp")
model = AutoModelForCausalLM.from_pretrained(
"deepseek-ai/DeepSeek-V3.2-Exp",
device_map="auto", # mapeamento automático para GPUs disponíveis
torch_dtype="auto" # utiliza dtype suportado (possivelmente FP8/BF16)
)
prompt = "Usuário: Explique o conceito de aprendizado por reforço. \nAssistente:"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
output_ids = model.generate(input_ids, max_length=500)
resposta = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(resposta)
Esse código hipotético carrega o modelo do repositório deepseek-ai/DeepSeek-V3.2-Exp no Hugging Face. Aviso: na prática, esse modelo completo com 685B parâmetros não caberá em uma única GPU comum – seria necessário múltiplas GPUs de alta memória (por exemplo, A100/H100) ou usar quantização avançada (o Hugging Face indica suportar pesos em BF16, FP8 etc., conforme disponibilidade de hardware). Portanto, o snippet acima serve apenas como conceitual. Para uso real, prefira ferramentas como o vLLM ou a API da DeepSeek, a menos que você disponha de infraestrutura apropriada. A DeepSeek inclusive disponibilizou kernels otimizados em código aberto (via projetos TileLang, DeepGEMM, FlashMLA) para quem quiser customizar a inferência do modelo – algo de interesse para pesquisadores trabalhando em otimização de hardware e low-level.
Como Integrar o Modelo via API ou Localmente
Integrar o DeepSeek V3.2-Exp em seus projetos é relativamente simples graças à abordagem compatível com padrões adotada pela DeepSeek. Aqui recapitulamos as principais formas de integração e o que você precisa para cada uma:
- Via API Cloud da DeepSeek: Essa é a maneira mais prática para começar. Basta se registrar na plataforma DeepSeek e obter uma API Key. As chamadas são feitas para
https://api.deepseek.com(com caminho/chat/completionspara interações estilo chat) usando o modelo desejado. Você pode usar qualquer cliente compatível com OpenAI API – por exemplo, a bibliotecaopenaiem Python, bibliotecas em Node.js, Postman, etc. – e apenas direcionar as requisições ao endpoint da DeepSeek. Os modelos disponíveis sãodeepseek-chatedeepseek-reasoner, conforme vimos. A autenticação é via headerAuthorization: Bearer <API_KEY>. Uma vez configurado, o uso é idêntico ao da API do ChatGPT, incluindo suporte a streaming de tokens se desejado (passandostream=true). Essa integração via API cloud tem a vantagem de não precisar gerenciar infraestrutura nem baixar modelos, e você se beneficia imediatamente das atualizações ou melhorias que a DeepSeek fizer. - Via execução local (auto-hospedado): Se você tem requisitos de privacidade, necessidade de operar offline ou quer evitar custos de API em produção, pode optar por rodar o modelo localmente ou em servidores sob seu controle. Para isso, você vai baixar os pesos do modelo do Hugging Face (atenção: são muitas dezenas de GB de dados) e carregá-los usando frameworks adequados. Como mencionado, frameworks como vLLM facilitam a vida ao lidar com memória virtual e paginação de atenção para longos contextos. A DeepSeek liberou inclusive configurações e scripts de conversão de pesos em seu repositório GitHub, o que indica que a comunidade já conseguiu fazer deploys do V3.2-Exp em clusters com sucesso desde o lançamento. Integrar localmente requer conhecimento em PyTorch, CUDA e possivelmente MoE, mas é perfeitamente possível se você tiver acesso a, por exemplo, GPUs A100 de 80GB em quantidade suficiente (ou as novas H100 que suportam FP8 para maximizar eficiência). Uma vez rodando local, você pode expor seu próprio endpoint ou usar a interface de chat interativa provida no repo (há scripts de geração interativa mencionados).
- Via plataformas e terceiros: Dado o interesse da comunidade, já existem provedores e integrações que suportam o DeepSeek V3.2-Exp. Por exemplo, a plataforma OpenRouter incluiu esse modelo em seu catálogo, permitindo uso via chave unificada. Serviços como Hugging Face Spaces apresentam demos do modelo funcionando (apesar de limitados pelo hardware disponível). Além disso, bibliotecas de agentes e LangChain-style estão adicionando suporte – afinal, a sintaxe de chamar o DeepSeek via SDK OpenAI facilita plugá-lo onde antes se usava GPT-4, por exemplo. Fique atento a recursos comunitários, como plugins e conectores, que podem acelerar a adoção.
Em termos de licenciamento e custo: o modelo é MIT (open source), logo não há restrições de uso do software em si. Se você usar a API da DeepSeek, os custos são baseados em tokens consumidos, conforme tabela (no lançamento, entrada ~ $0.28 por 1M tokens, saída $0.42 por 1M tokens, com possibilidade de cache de contexto reduzindo custo). Isso é significativamente mais barato que modelos equivalentes tradicionais, graças à eficiência do DSA que permitiu cortar preços pela metade ou mais. Para equipes de produto, essa economia pode ser decisiva ao escolher um modelo de linguagem para integrar em larga escala.
Resumindo: para integrar o DeepSeek V3.2-Exp, você pode usar diretamente a API (rápido e prático) ou hospedar você mesmo (mais trabalho, porém sem dependências externas). A escolha depende dos seus requisitos de projeto. Em ambos os casos, o modelo está acessível e pensado para ser amigável a desenvolvedores, aproveitando padrões já difundidos.

Benefícios para Equipes de Engenharia e Produto
A adoção do DeepSeek V3.2-Exp pode trazer diversos benefícios concretos para times de engenharia de software, cientistas de dados e gerentes de produto que planejam funcionalidades baseadas em IA. Destacamos alguns ganhos e diferenciais ao utilizar esse modelo:
Inovação de produto com dados complexos: Com a capacidade de processar contextos massivos, produtos que antes estavam limitados a inputs pequenos agora podem ser ampliados. Por exemplo, uma ferramenta de análise de contratos pode aceitar documentos inteiros de uma vez; um app de notas inteligente pode carregar todas as notas do usuário para responder perguntas de forma contextualizada; um assistente de programação pode levar em conta toda a base de código. Isso permite criar funcionalidades mais robustas e ricas, oferecendo soluções diferenciadas aos usuários finais.
Redução de custos de operação: A eficiência do DeepSeek V3.2-Exp significa que menos recursos computacionais são gastos por tarefa, especialmente em usos de contexto extenso. Para uma equipe de produto, isso pode se traduzir diretamente em economia financeira ao escalar um serviço de IA. Com preços de token substancialmente menores que alternativas comparáveis, é possível processar volumes maiores de informação com o mesmo orçamento. Além disso, a existência de um modo de raciocínio que melhora a qualidade sem intervenção humana pode reduzir custos de fallback ou revisão humana em tarefas complexas.
Transparência e depuração com CoT: Do ponto de vista de engenharia de prompting, poder habilitar a saída de cadeia de raciocínio (CoT) é extremamente útil. Isso permite às equipes depurar como o modelo está pensando em casos de erro, ajustando instruções se necessário. Também ajuda a explicar decisões da IA para stakeholders não técnicos ou para usuários finais (no caso de produtos em que a confiabilidade é crítica). Essa transparência pode acelerar o ciclo de desenvolvimento, já que engenheiros conseguem diagnosticar problemas de respostas insatisfatórias olhando o reasoning_content e entendendo onde o modelo pode ter se desviado.
Flexibilidade de implantação (cloud ou self-hosted): Diferentes organizações têm diferentes restrições – algumas preferem serviços em nuvem pela facilidade, outras precisam que os dados não saiam de seus servidores (por compliance). O DeepSeek V3.2-Exp atende ambos: está disponível como serviço gerenciado e também open source para implantação interna. Essa flexibilidade significa que a equipe pode começar experimentando na nuvem e, se necessário, migrar para on-premises sem mudar de tecnologia base, ou vice-versa. Não há risco de vendor lock-in, já que o modelo é aberto e utilizável fora do ambiente da DeepSeek.
Aprimoramento contínuo sem esforço adicional: Sendo um modelo experimental de vanguarda, é provável que a DeepSeek lance melhorias, ajustes e novos modelos futuramente. Ao adotar o V3.2-Exp agora, sua equipe se posiciona na frente da curva tecnológica, podendo absorver melhorias incrementais facilmente. Por exemplo, se no futuro sair um DeepSeek V3.3 com mais avanços, a migração tende a ser simples (dado o compromisso de compatibilidade). Além disso, a comunidade em torno do modelo (que já é ativa, vide fóruns e repositórios) pode contribuir com fixes, fine-tunings especializados, etc., dos quais sua equipe pode se beneficiar.
Desbloquear casos de uso antes impraticáveis: Talvez o maior benefício seja estratégico – poder fazer o que antes não era possível. Muitas ideias de produto ficam engavetadas por limitações técnicas. Com 128K de contexto e ferramental avançado, conceitos como “um consultor virtual que absorve todo o website do cliente e sugere melhorias” ou “um analista que lê todo o log de eventos e encontra correlações” se tornam realizáveis. Isso pode levar a propostas de produto inovadoras que diferenciam sua empresa no mercado. Equipes de engenharia podem prototipar rapidamente essas ideias usando o V3.2-Exp e avaliar o impacto.
Em suma, o DeepSeek V3.2-Exp é mais do que um modelo potente – é um habilitador de soluções. Para as equipes de engenharia, ele traz reduções de custo e novas ferramentas para desenvolvimento. Para as equipes de produto, amplia os horizontes do que pode ser oferecido aos usuários. E tudo isso com a tranquilidade de se apoiar em uma tecnologia aberta e com forte enfoque em eficiência e qualidade.
Melhores Práticas de Uso
Ao trabalhar com o DeepSeek V3.2-Exp, é importante seguir algumas melhores práticas para tirar o máximo proveito do modelo e evitar problemas. Aqui estão recomendações úteis:
Estruture bem o prompt em contextos longos: Embora você possa jogar 100 mil tokens de uma vez no modelo, nem sempre deve. Forneça uma estrutura clara no prompt, por exemplo utilizando um sistema de divisões por assunto ou seções resumidas. Isso ajuda o mecanismo DSA a identificar onde estão as partes relevantes. Inclua instruções no início (mensagem de sistema) contextualizando o que o modelo deve fazer com aquele conteúdo extenso – por exemplo: “Resumo dos documentos a seguir e responda às perguntas conforme solicitado.”.
Use o modo adequado para cada tarefa: Lembre-se de escolher entre deepseek-chat e deepseek-reasoner conforme a necessidade. Para questões diretas e simples ou conversas informais, use o chat (que será mais rápido e econômico). Para problemas complexos, cálculo, lógica ou quando a precisão máxima é importante, use o reasoner para que o modelo faça o CoT. Isso melhora as chances de acerto e permite auditar o raciocínio. Tenha em mente que o modo reasoner consome mais tokens (pois a cadeia de pensamento vem incluída), então use-o de forma intencional onde agrega valor.
Ferramentas: defina bem e teste: Ao expor funções para o modelo usar, descreva-as de forma precisa e restritiva o suficiente para evitar confusão. Utilize o campo description para guiar o modelo sobre quando usar a função. Por exemplo: “Função que deve ser usada somente se o usuário pedir informações meteorológicas.”. Teste cenários variados para garantir que o modelo não tente chamar funções indevidamente ou com parâmetros incorretos. Se usar o modo estrito, valide o esquema JSON para ter certeza de que está correto e é suportado (o exemplo adiciona "additionalProperties": false para maior rigor, caso desejado). Além disso, imponha limites e timeouts nas funções reais – lembre-se que o modelo pode pedir ações externas de forma autônoma, então garanta que sua implementação do lado da ferramenta tenha salvaguardas (por exemplo, evitar chamadas infinitas, não permitir comandos perigosos etc.).
Cuidado com o tamanho da saída: A DeepSeek limita por padrão a saída a 4K tokens (no modo chat) e 32K (no reasoner) por requisição, com máximos de 8K e 64K respectivamente. Ou seja, mesmo que o modelo possa processar 128K de input, ele não vai gerar 100K de resposta de uma vez (o que faz sentido). Portanto, se você precisar de uma resposta muito longa (como capítulos de um livro), planeje uma estratégia de iteração, gerando parte por parte. Use o parâmetro max_tokens para controlar isso e evitar respostas cortadas. Quando o output for próximo do limite, o modelo pode interromper no meio – se isso ocorrer, você pode enviar um prompt indicando para continuar de onde parou (por ex: “Continue a partir da frase interrompida acima…”).
Gerencie o custo com inteligência: Apesar de mais barato que alternativas, 128K tokens ainda representam uma quantidade considerável, então use essa capacidade com parcimônia. Aproveite caching de contexto quando disponível – a DeepSeek menciona cache de contexto que pode reduzir drasticamente o custo de partes repetidas do prompt. Por exemplo, se você sempre mandar a mesma base de conhecimento junto com perguntas diferentes, veja a possibilidade de usar a funcionalidade de cache para não pagar pelos mesmos tokens todo turno. Outra dica é resumir internamente ou hierarquizar: em vez de mandar todo o conteúdo detalhado, talvez mandar um sumário inicial e aprofundar com detalhes sob demanda. O DSA ajuda nisso, mas sua lógica de negócio também pode.
Monitorar e filtrar saídas sensíveis: Como qualquer modelo de linguagem grande, o DeepSeek V3.2-Exp pode produzir conteúdo inadequado ou alucinações. Embora não haja indicações de problemas específicos, siga as práticas de segurança: aplique filtros de palavrões, hate speech, dados pessoais, etc., conforme o contexto de sua aplicação. Se estiver usando em produção, considere implementar uma camada de moderação (seja usando modelos especializados ou regras manuais) após a resposta do modelo, antes de exibi-la aos usuários. Além disso, se o modelo for usado para tomar ações (via ferramentas), valide as ações – por exemplo, se ele retornou uma chamada de função perigosa ou não permitida, bloqueie e ajuste o prompt para evitar isso.
Fique atento às atualizações e feedback: Por ser um modelo experimental, esteja preparado para possíveis ajustes de comportamento em atualizações. A DeepSeek parece receptiva a feedback da comunidade, então se você encontrar alguma inconsistência ou bug, reporte nos canais oficiais (Discord, GitHub, etc.). A vantagem de ser open source é que, se necessário, você mesmo pode ajustar um fine-tune ou alterar detalhes para adequar melhor ao seu caso. Participe da comunidade, pois outros desenvolvedores podem compartilhar prompts eficazes, workarounds ou melhorias que incrementem suas melhores práticas ao usar o V3.2-Exp.
Seguindo essas diretrizes, você deverá conseguir extrair o melhor desempenho do DeepSeek V3.2-Exp, garantindo respostas de qualidade, controlando custos e mantendo a segurança e confiabilidade da sua aplicação.
Considerações sobre Desempenho, Limites e Precauções
Apesar de suas qualidades, o DeepSeek V3.2-Exp, assim como qualquer tecnologia, possui limitações e requer precauções em seu uso:
Desempenho e latência: O modelo é enorme, o que implica que a inferência mesmo com otimizações ainda pode ser relativamente lenta se comparada a modelos menores. Em solicitações de 128K tokens, espere latências significativamente maiores (possivelmente vários segundos ou até minutos) dependendo da infraestrutura. A atenção esparsa ameniza o crescimento da carga com o tamanho do contexto, mas não faz milagres – a complexidade passa a ser aproximadamente linear O(k·L) em vez de O(L²), porém se L for 100k, ainda é uma operação custosa. Para cenários de tempo real ou aplicações interativas, considere se realmente precisa do contexto máximo ou se pode trabalhar com janelas mais curtas por questão de responsividade.
Consumo de memória: Quem for hospedar o modelo localmente deve estar ciente do enorme consumo de memória RAM/VRAM. Com 685B parâmetros em BF16, estamos falando de centenas de gigabytes de memória necessárias. Mesmo com MoE ativando parcialmente, os pesos residem em memória. Técnicas de offloading (para CPU ou disco) ajudam, mas podem degradar performance. Em resumo, esse modelo não é para ser executado em uma máquina comum – planeje uso em servidores robustos ou plataformas cloud especializadas. Felizmente, se usar a API, esse detalhe fica abstraído, mas atente ao fato de que contextos gigantes implicam também transferir muitos dados pela rede (envio do prompt), o que pode ser um gargalo.
Limites conhecidos: Por ser experimental, o V3.2-Exp pode ter alguns bugs ou limitações. A própria DeepSeek alertou que não se trata de um modelo production-ready final ainda. Isso significa que ele pode ocasionalmente falhar em seguir perfeitamente alguma instrução ou ter pequenas réguas de performance a calibrar. Em nossos exemplos, vimos que o modo reasoner não suporta certas funcionalidades (ex.: não dá para usar ferramentas nele diretamente). Também é possível que existam tarefas onde o modelo não tenha sido extensivamente testado. Portanto, faça validações em casos de uso críticos antes de confiar cegamente. Se sua aplicação requer alta exatidão (p.ex. diagnósticos médicos, decisões financeiras), considere manter um humano no circuito ou usar múltiplas fontes de verificação até que o modelo prove consistência.
Alucinações e veracidade: Assim como outros LLMs, o DeepSeek V3.2-Exp pode produzir alucinações, ou seja, afirmar coisas que não são verdadeiras como se fossem fatos. O contexto enorme pode reduzir isso quando a informação correta está presente no prompt (pois ele pode localizá-la), mas não elimina o risco. Além disso, se a resposta exigir conhecimento atualizado após o treinamento ou detalhes muito específicos, ele pode acabar inventando se não tiver acesso a uma ferramenta externa. Trate as saídas do modelo com senso crítico – para uso informativo, sempre confirme os dados se possível. Considere habilitar checagem da cadeia de raciocínio (no modo reasoner) para ver se algum passo parece ilógico. Em cenários de chatbots, se o usuário pedir informações factuais críticas (medicamentos, leis, etc.), pode ser sensato programar o agente para citar fontes ou indicar incerteza ao invés de responder confiantemente sem base.
Ética e moderação: Embora não seja o foco técnico, nunca é demais ressaltar: utilize o modelo de forma ética e em conformidade com as políticas de uso de IA. O DeepSeek V3.2-Exp deve evitar geração de conteúdos violentos, de ódio, ilegais, etc., mas cabe a você supervisionar. Para desenvolvedores, isso significa implementar filtros ou usar prompts de sistema que desencorajem esses tópicos. A DeepSeek provavelmente possui suas políticas, especialmente para uso via API, então certifique-se de segui-las e de que seu produto final também ofereça proteções ao usuário.
Limites de contexto e segredos: Um detalhe operacional – apesar de suportar 128K tokens, tente não inserir dados sensíveis ou proprietários desnecessariamente no prompt, principalmente se usando o serviço cloud. Grandes janelas de contexto podem incentivar despejar, por exemplo, todo o banco de dados ou todos os documentos internos. Mas considere questões de segurança: esses dados trafegam para um servidor externo (a não ser que você hospede local), e também podem influenciar a saída de forma inesperada. É melhor usar a capacidade vasta para aquilo que realmente importa à tarefa e com consentimento e cuidado sobre o conteúdo incluído.
Em conclusão desta parte, o DeepSeek V3.2-Exp é uma ferramenta poderosa, mas deve ser usada com responsabilidade e compreensão de suas características.
Com o devido planejamento de desempenho e salvaguardas, ele pode ser integrado de forma segura e eficiente em aplicações profissionais.
A chave é aproveitar suas forças (contexto, raciocínio, ferramentas) enquanto mitiga-se as fraquezas (custo de recursos, possíveis alucinações).
Dito isso, a cada iteração e feedback da comunidade, esses limites tendem a diminuir, dado o ritmo acelerado de melhoria nos modelos de linguagem.
Conclusão
O DeepSeek V3.2-Exp representa um avanço empolgante no campo de modelos de linguagem, ao combinar contexto estendido de 128K tokens, mecanismos de raciocínio estruturado e integração transparente com ferramentas. Ao longo deste artigo, exploramos sua proposta e características técnicas, ilustramos casos de uso práticos e exemplos de implementação em código, discutimos como integrá-lo tanto via API quanto localmente, e elencamos benefícios, boas práticas e cuidados necessários. Do ponto de vista de desenvolvedores e profissionais de tecnologia, fica claro que este modelo oferece um leque de possibilidades para construir aplicações mais poderosas e inteligentes, indo desde chatbots com memória expandida até agentes autônomos capazes de navegar por tarefas complexas.
A natureza experimental do V3.2-Exp não deve ser vista como um ponto negativo, mas sim um convite à inovação. DeepSeek explicitamente posiciona esta versão como um step intermediário rumo a arquiteturas de próxima geração, o que significa que quem começar a experimentar agora estará ajudando a moldar o futuro desses sistemas. A plataforma aberta e a disposição em reduzir custos democratizam o acesso a um modelo de ponta que, de outra forma, estaria disponível apenas para grandes corporações.
Fica aqui o convite à experimentação: se você é desenvolvedor, tente incorporar o DeepSeek V3.2-Exp em um projeto piloto. Teste sua capacidade com aquele conjunto de dados volumoso que você tinha disponível. Avalie seu desempenho frente aos desafios específicos do seu domínio. Muito possivelmente, você se surpreenderá positivamente com o que ele pode fazer. E ao mesmo tempo, contribua com feedback – a comunidade e a equipe DeepSeek podem evoluir o modelo ainda mais com casos de uso do mundo real.
Em suma, o DeepSeek V3.2-Exp sinaliza um caminho para modelos de linguagem mais contextuais, eficientes e funcionalmente ricos. As equipes de engenharia e produto que souberem aproveitar essa onda terão em mãos uma ferramenta diferenciada para criar experiências de IA de alto nível. Agora é a hora de explorar, prototipar e inovar com esse modelo. Mãos à obra – e boas experimentações com o DeepSeek V3.2-Exp.


