
O DeepSeek V3.1 é um modelo de linguagem de inteligência artificial (IA) de última geração, desenvolvido para oferecer capacidades avançadas de geração de texto e raciocínio automatizado. Destinado especialmente a desenvolvedores e equipes de IA, este modelo destaca-se por introduzir uma arquitetura híbrida de inferência, capaz de alternar entre um modo de raciocínio (com cadeia de pensamento passo a passo) e um modo de resposta direta, tudo dentro de um único modelo. Em outras palavras, o DeepSeek V3.1 pode tanto elaborar respostas detalhadas mostrando seu processo de pensamento quanto fornecer soluções objetivas de forma imediata, conforme a necessidade da aplicação.
Na prática, o DeepSeek V3.1 serve como um poderoso assistente de IA multifuncional. Ele pode ser empregado na criação de chatbots inteligentes, assistência na programação de software, análise de dados e textos extensos, e até no suporte a agentes autônomos que utilizam ferramentas externas. Ao longo deste artigo, exploraremos em profundidade a arquitetura e capacidades técnicas do DeepSeek V3.1, suas aplicações práticas para desenvolvedores, exemplos de uso com código, como integrá-lo via API ou localmente, benefícios de adoção e melhores práticas. Por fim, discutiremos considerações de desempenho e limitações, oferecendo uma visão completa deste modelo de linguagem emergente. Vamos começar entendendo o que torna sua arquitetura única e tão relevante para a comunidade de desenvolvimento.
Arquitetura e Capacidades Técnicas
O DeepSeek V3.1 foi projetado para ser um dos modelos de linguagem mais avançados disponíveis atualmente, combinando escala, contexto ampliado e novos recursos de raciocínio. Em seu núcleo, trata-se de um Large Language Model (LLM) baseado em transformadores, com aprimoramentos significativos em comparação a gerações anteriores de modelos de IA (embora neste artigo foquemos apenas no DeepSeek V3.1 em si, sem comparações diretas).
A seguir, destacamos as principais características da arquitetura e capacidades técnicas do DeepSeek V3.1:
- Quantidade de parâmetros maciça: O modelo conta com impressionantes 671 bilhões de parâmetros no total, dos quais aproximadamente 37 bilhões de parâmetros são ativados a cada inferência. Essa configuração sugere uma arquitetura otimizada (por exemplo, com Mixture-of-Experts, especialistas condicionais ou técnicas de sparsity) que permite escalar a capacidade sem usar todos os pesos simultaneamente, tornando a inferência mais eficiente. Em termos práticos, a enorme quantidade de parâmetros habilita o DeepSeek V3.1 a capturar nuances do idioma, conhecimento factual extenso e estruturas de código complexas.
- Contexto ultra-amplo (128K tokens): Uma das capacidades técnicas mais notáveis é a janela de contexto de até 128.000 tokens. Isso equivale a centenas de páginas de texto, permitindo ao modelo processar entradas ou manter conversas de comprimento extraordinário sem perder referências. Desenvolvedores podem aproveitar esse contexto ampliado para tarefas como análise de documentos longos, carga de logs extensos, ou mesmo manter histórico de conversas muito extenso. Para atingir esse contexto, o DeepSeek V3.1 passou por um treinamento especial de extensão de contexto (long context extension), incorporando 840 bilhões de tokens adicionais em seu treinamento contínuo. Esse treinamento incremental em duas fases (primeiro para 32K tokens, depois para 128K) garantiu que o modelo aprendesse a manter desempenho mesmo com entradas longas, seguindo metodologia descrita em relatórios técnicos do projeto DeepSeek.
- Inferência híbrida (modo de raciocínio vs. direto): O DeepSeek V3.1 pode funcionar em dois modos de geração de resposta. No modo não-raciocínio (resposta direta), ele produz respostas diretamente ao usuário, de forma semelhante a outros assistentes de linguagem convencionais. Já no modo de raciocínio (thinking), o modelo é capaz de engajar em uma cadeia de pensamento interna, gerando passo a passo as deduções ou planos antes de chegar à resposta final. Essa funcionalidade é habilitada por prompts especiais no formato de chat – por exemplo, delimitando pensamentos entre tokens especiais
<think>e</think>. Com essa abordagem, o mesmo modelo pode alternar entre respostas imediatas e respostas elaboradas com passo-a-passo, bastando modificar levemente o prompt de entrada. Para o desenvolvedor, isso significa ter flexibilidade: usar o modo direto em interações que exigem rapidez, e acionar o modo de raciocínio quando precisar de soluções mais complexas ou explicativas, sem trocar de modelo. - Chamada de ferramentas e agentes integrados: Graças a um processo de pós-treinamento focado em agentes, o DeepSeek V3.1 possui habilidades avançadas para utilizar ferramentas externas e executar tarefas multi-passo de forma autônoma. Ele foi ajustado para formatar corretamente outputs de ferramenta (seguindo formatos JSON especiais, por exemplo) e encadear operações. Especificamente, o modelo suporta nativamente:
- Tool Calls (chamadas de ferramentas): No modo de resposta direta, é possível fornecer uma descrição de ferramentas disponíveis (como calculadoras, mecanismos de busca, bancos de dados) e o modelo pode retornar instruções estruturadas para usar essas ferramentas. Isso viabiliza a criação de agentes que consultam APIs ou executam ações durante a conversa.
- Code Agent: O DeepSeek V3.1 consegue atuar como um agente de código, escrevendo, executando e depurando código em etapas. Há formatos de prompt específicos ensinados ao modelo para que ele interaja com ambientes de programação e produza soluções de código de forma iterativa.
- Search Agent: Em modo de raciocínio, o modelo também pode interagir com ferramentas de busca web para obter informações atualizadas, seguindo um formato multi-turn especial de perguntas e respostas com um mecanismo de busca fornecido pelo usuário. Esse recurso de agente de busca torna o DeepSeek V3.1 apto a responder questões complexas que exijam conhecimento fora de seu treinamento, navegando em etapas como um agente autônomo.
- Treinamento otimizado e precisão numérica: Para lidar com a escala massiva de parâmetros, o modelo foi treinado utilizando formato de ponto flutuante de 8 bits (FP8) em pesos e ativações. Essa técnica, suportada por kernels personalizados (por exemplo, biblioteca DeepGEMM desenvolvida pela equipe DeepSeek), permite reduzir o consumo de memória e aumentar a velocidade de cálculo sem degradar a qualidade, graças a escala fina dos tensores FP8. Além disso, o treinamento envolveu um conjunto de dados diversificado e de larga escala, cobrindo múltiplos domínios (código, texto técnico, diálogos, etc.) e idiomas, com mais de 100 idiomas suportados pelo modelo. O DeepSeek V3.1 demonstra proficiência quase nativa em dezenas de línguas, inclusive apresentando melhorias significativas em idiomas de poucos recursos (aqueles com poucos dados disponíveis para treino). Isso o torna uma opção atraente para aplicações multilíngues e globais.
- Open-source e integração facilitada: Uma vantagem importante é que o DeepSeek V3.1 possui pesos abertos, disponíveis publicamente para uso e deploy. O modelo (tanto a versão base quanto a versão instrução/chat) foi liberado sob licença permissiva MIT, permitindo que desenvolvedores o utilizem e até adaptem livremente em seus próprios projetos. Os pesos podem ser obtidos através do Hugging Face Hub e outros repositórios (por exemplo, ModelScope), e a API do DeepSeek também segue padrões abertos. Isso significa que é possível integrar o modelo localmente ou em nuvem privada, garantindo controle sobre dados sensíveis e customizações específicas, ou consumir via serviços compatíveis com a API OpenAI de forma prática (como veremos mais adiante).
Resumidamente, a arquitetura do DeepSeek V3.1 combina escala (para abrangência de conhecimento), contexto prolongado (para manter conversas e documentos extensos), raciocínio explícito (para soluções complexas passo a passo) e ferramentas/ações (para interagir com o mundo externo). Essa união de capacidades técnicas o posiciona como uma plataforma robusta para construir aplicações de IA avançadas.
No próximo tópico, veremos como essas capacidades se traduzem em aplicações práticas para desenvolvedores no dia a dia.
Aplicações Práticas para Desenvolvedores
Com suas capacidades técnicas abrangentes, o DeepSeek V3.1 abre um leque de aplicações práticas no desenvolvimento de software e soluções de IA.
A seguir, destacamos algumas das principais formas como desenvolvedores podem aproveitar esse modelo em projetos reais:
- Geração e assistência de código: O DeepSeek V3.1 excelente em tarefas de programação e pode atuar como um poderoso assistente de codificação. Desenvolvedores podem utilizá-lo para gerar trechos de código a partir de descrições em linguagem natural, sugerir soluções para algoritmos, explicar blocos de código existentes ou mesmo ajudar na detecção de bugs. Graças ao seu treinamento especializado, o modelo apresenta desempenho elevado em benchmarks de engenharia de software e desafios de programação, fornecendo resultados de alta qualidade de forma eficiente. Isso o torna ideal para ferramentas de auto-completação de código, chatbots de suporte a programadores (estilo pair programming com IA) e automação de tarefas de desenvolvimento.
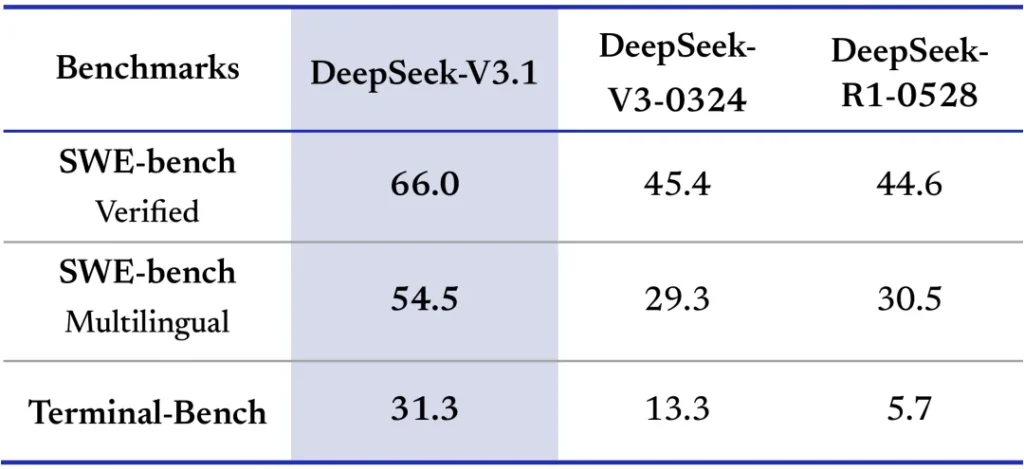
- Agentes autônomos e ferramentas de IA: O DeepSeek V3.1 foi concebido com a visão da “era dos agentes“. Seus recursos de chamada de ferramentas e modo de raciocínio o tornam especialmente indicado para construir agentes autônomos orientados a objetivos. Por exemplo, é possível criar um agente que realize tarefas de pesquisa na web, análise de dados ou execução de comandos em um terminal, guiado pelas saídas estruturadas do modelo. A pós-otimização do modelo reforçou essas habilidades de uso de ferramentas, permitindo que workflows multi-step complexos sejam resolvidos com sucesso. Desenvolvedores podem integrar o DeepSeek V3.1 em frameworks de agentes (como LangChain, Auto-GPT, etc.), onde ele atuará como o “cérebro” do agente, decidindo ações a tomar, interpretando resultados e refinando a estratégia de maneira semelhante a um humano. Isso é valioso para construir sistemas de IA agente que automatizam tarefas de suporte, atendimento, buscas complexas ou operações de software sem supervisão constante.
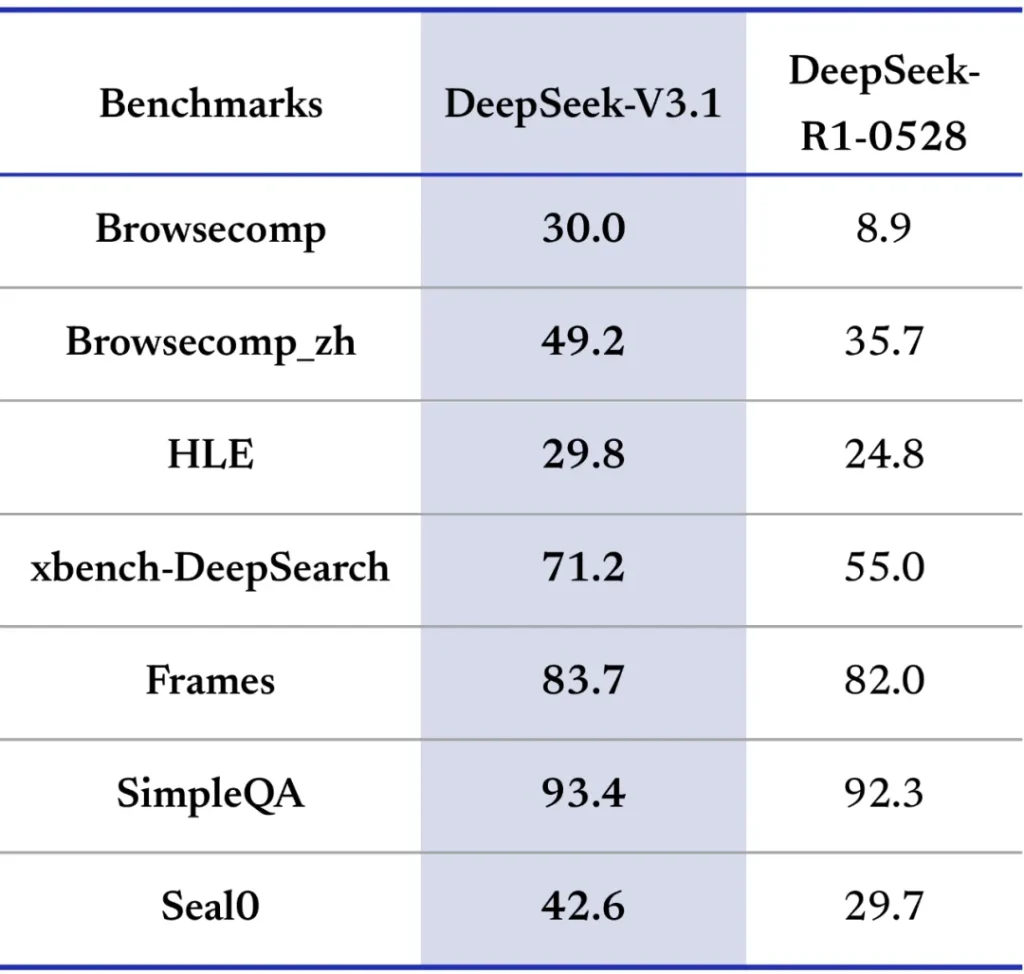
- Assistentes virtuais e aplicativos conversacionais: Por ser um modelo de linguagem geral e multilíngue, o DeepSeek V3.1 encaixa-se naturalmente em aplicações de chatbot e assistentes virtuais. Equipes de produto podem utilizá-lo para criar assistentes de atendimento ao cliente, bots de ajuda em aplicativos, ou ferramentas internas de suporte que entendem comandos em linguagem natural. Sua capacidade de manter longos contextos garante que o assistente lembre-se de interações anteriores, tornando as conversas mais coerentes em diálogos prolongados. Além disso, a competência em mais de 100 idiomas permite desenvolver soluções voltadas a públicos globais sem a necessidade de modelos separados por língua. Em ambientes empresariais, o DeepSeek V3.1 pode ser integrado a plataformas de chat corporativo, aplicativos de produtividade ou sistemas de documentação, aprimorando as interações do usuário com respostas mais precisas e contextualizadas, e até respeitando nuances culturais devido à sua ampla base de conhecimento linguístico.
- Análise de dados e textos extensos: Com a janela de 128K tokens, o modelo possibilita analisar documentos volumosos ou conjuntos de dados textuais grandes de uma só vez. Desenvolvedores podem alimentar o modelo com relatórios extensos, artigos científicos, logs de aplicações ou outros textos longos, e pedir resumos, extração de informações ou respostas a perguntas específicas sobre aquele conteúdo. Por exemplo, pode-se submeter todo um livro ou manual técnico como contexto e interagir com o modelo fazendo perguntas sobre o material. Isso abre oportunidades em ferramentas de análise de documentos, motores de pergunta-e-resposta em bases de conhecimento extensas e assistência na compreensão de textos legais, financeiros ou científicos volumosos. A capacidade de raciocínio estruturado também ajuda o modelo a “pensar” sobre os dados, fazendo conexões lógicas durante a análise.
- Pesquisa e experimentação em IA: Para pesquisadores e entusiastas, o DeepSeek V3.1 serve como uma plataforma rica para experimentar técnicas de IA. Sendo open-source, ele pode ser utilizado como ponto de partida para fine-tuning em domínios específicos, avaliação de técnicas de prompt engineering (especialmente explorando o efeito do modo de raciocínio), e estudos sobre como modelos de grande porte realizam cadeias de pensamento. Sua arquitetura diferenciada (e.g. uso de FP8, especialistas, contexto longo) oferece um campo de aprendizado para acadêmicos interessadas em sistemas de IA de ponta. Equipes podem testar o desempenho do DeepSeek V3.1 em seus próprios benchmarks internos, comparar abordagens de resolução de problemas com e sem cadeia de pensamento, e investigar questões de interpretabilidade observando as rationale geradas no modo <think>.
Em resumo, o DeepSeek V3.1 é versátil e poderoso: desde facilitar a vida de um engenheiro de software no dia a dia, até viabilizar agentes de IA complexos e pesquisas acadêmicas, suas aplicações são amplas. No próximo tópico, veremos exemplos concretos de como usar o modelo, com trechos de código em Python ilustrando integrações típicas.
Exemplos de Uso com Código
Para demonstrar na prática o uso do DeepSeek V3.1, apresentamos a seguir alguns exemplos em Python. Mostraremos tanto como consumir o modelo via API quanto como executá-lo localmente usando a biblioteca Hugging Face Transformers, já que o modelo possui pesos disponíveis abertamente.
Esses exemplos dão uma noção de como integrar o DeepSeek V3.1 em fluxos de trabalho de desenvolvedores.
Exemplo 1: Uso do DeepSeek V3.1 via API (Python)
Uma forma prática de utilizar o modelo é por meio da API oficial do DeepSeek, que é compatível com a API OpenAI. Isso significa que, se você já usou a API do OpenAI (por exemplo, com a biblioteca openai em Python), pode facilmente adaptar o código para enviar requisições ao endpoint do DeepSeek. Primeiro, é necessário obter uma chave de API do DeepSeek (no site oficial ou console). Em seguida, basta ajustar o base_url para o da API DeepSeek e especificar o modelo desejado. O DeepSeek V3.1 disponibiliza dois identificadores principais de modelo na API: geralmente deepseek-chat para o modo padrão (não-raciocínio) e deepseek-reasoner para o modo raciocínio. No exemplo abaixo, usamos o modo chat (resposta direta):
import os
import openai
# Configuração do cliente OpenAI apontando para o endpoint DeepSeek
openai.api_key = os.getenv("DEEPSEEK_API_KEY") # insira sua chave de API aqui
openai.api_base = "https://api.deepseek.com/v1" # endpoint base da API DeepSeek
# Envia uma requisição de conversa ao modelo DeepSeek V3.1 (modo chat)
response = openai.ChatCompletion.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "Você é um assistente útil."},
{"role": "user", "content": "Olá, tudo bem?"}
],
stream=False # define True para receber respostas em streaming
)
print(response['choices'][0]['message']['content'])
# Saída esperada: uma resposta educada do assistente cumprimentando o usuário.
No código acima, utilizamos a classe ChatCompletion.create da biblioteca OpenAI para enviar mensagens ao modelo. Definimos um prompt de sistema em português e uma mensagem de usuário. O modelo "deepseek-chat" retorna então a resposta do assistente, que imprimimos em seguida. Essa integração funciona de forma muito semelhante à API do ChatGPT, mas agora direcionando a consulta ao DeepSeek V3.1. Conforme necessário, poderíamos alternar para model="deepseek-reasoner" caso quiséssemos acionar o modo de raciocínio do V3.1 na resposta (útil para depurar ou obter cadeias de pensamento, se a aplicação suportar exibi-las ou usá-las internamente).
Exemplo 2: Carregando o DeepSeek V3.1 localmente com Transformers
Outra possibilidade é executar o modelo localmente (ou em um servidor controlado por você), utilizando os pesos open-source disponíveis. A vantagem dessa abordagem é ter controle total sobre a inferência, possibilidade de customização e potencial economia de custos em longo prazo, embora rodar um modelo desse porte exija hardware de alto desempenho (GPUs com memória abundante, preferencialmente). A biblioteca Hugging Face Transformers já suporta o DeepSeek V3.1, inclusive com alguns dos recursos especiais como a aplicação automática do template de chat. Abaixo, demonstramos como carregar o modelo e gerar uma resposta simples:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "deepseek-ai/DeepSeek-V3.1"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto", # usa dtype nativo suportado (FP8 não é suportado diretamente, provável uso de FP16/BF16)
device_map="auto" # carrega o modelo distribuindo em GPUs disponíveis automaticamente
)
# Preparando uma pergunta para o modelo
pergunta = "Explique brevemente o que é a Lei da Relatividade Geral."
entrada = tokenizer(pergunta, return_tensors="pt")
entrada = {k: v.to(model.device) for k,v in entrada.items()} # envia os tensores para a GPU
# Geração da resposta
saida = model.generate(**entrada, max_new_tokens=200, do_sample=True, temperature=0.7)
resposta = tokenizer.decode(saida[0], skip_special_tokens=True)
print(resposta)
# Saída (exemplo abreviado): "A Teoria da Relatividade Geral, proposta por Albert Einstein em 1915, descreve a gravidade..."
Nesse snippet, carregamos o tokenizador e modelo do repositório deepseek-ai/DeepSeek-V3.1 no Hugging Face. Em seguida, tokenizamos uma pergunta de exemplo e usamos model.generate para obter uma resposta. Note que definimos alguns parâmetros importantes: max_new_tokens limita o tamanho da resposta gerada, e temperature=0.7 adiciona alguma aleatoriedade controlada (para respostas mais criativas, poderia-se aumentar, e para respostas mais determinísticas, reduzir para perto de 0). Também usamos device_map="auto" para permitir que o Hugging Face carregue partes do modelo em múltiplas GPUs automaticamente, caso disponível – o DeepSeek V3.1 é muito grande, então essa opção ajuda a viabilizar a execução distribuindo a carga. Sem GPUs potentes, essa geração pode não ser possível ou seria extremamente lenta, então avalie o ambiente de hardware ao optar por rodar localmente.
Outra funcionalidade disponível é usar o template de chat com o Transformers, de forma que o modelo produza saídas no formato esperado (especialmente útil para aproveitar o modo de raciocínio com as tags <think>). A função tokenizer.apply_chat_template pode inserir automaticamente os tokens especiais de usuário/assistente e <think> conforme necessário, facilitando a interação em múltiplas rodadas. Consulte a documentação do modelo ou repositório para detalhes adicionais sobre templates de formatação.
Os exemplos acima ilustram que o DeepSeek V3.1 pode ser consumido de maneiras flexíveis: via um serviço web pronto, com poucas linhas de código, ou integrado ao seu próprio pipeline de ML, dando a liberdade de ajustes finos. A próxima seção discutirá justamente como integrar o modelo em aplicações, seja consumindo a API ou hospedando-o localmente, e boas práticas envolvidas nesse processo.
Instruções para Integração via API ou Localmente
Integrar o DeepSeek V3.1 em sua aplicação pode ser feito de duas formas principais: acessando o modelo pela API hospedada pelos mantenedores (ou provedores parceiros), ou hospedando os pesos open-source localmente na sua própria infraestrutura. Cada abordagem tem seus prós e contras, e a escolha depende dos recursos disponíveis e dos objetivos do seu projeto. Abaixo, fornecemos orientações para ambas as opções.
Integração via API (serviço hospedado)
A API do DeepSeek permite utilizar o modelo de maneira escalável sem se preocupar com infraestrutura de servidores de inferência. Alguns pontos para integrar via API:
- Obtenha uma chave de API: Cadastre-se na plataforma DeepSeek (ou provedor compatível) e adquira uma chave de API. Há planos gratuitos e pagos dependendo do volume de uso e da velocidade desejada. Lembre-se de manter a chave segura e não expô-la publicamente.
- Use endpoints compatíveis com OpenAI: A API do DeepSeek adota o mesmo formato da API do OpenAI. Por exemplo, as requisições de chat são feitas para endpoints como
https://api.deepseek.com/v1/chat/completionscom um payload contendomodel,messagesetc. Você pode usar bibliotecas existentes (openaiem Python, SDKs de outras linguagens) apenas configurando obase_urlparahttps://api.deepseek.com/v1e usando sua chave DeepSeek. Isso facilita a adoção, pois o código de integração é praticamente idêntico ao de modelos como GPT-3.5/GPT-4, mudando apenas o nome do modelo. - Escolha o modelo (modo) adequado: Ao fazer a chamada, especifique
model: "deepseek-chat"para interações comuns oumodel: "deepseek-reasoner"para acionar o modo de raciocínio (cadeia de pensamento). Lembre-se de que o modo de raciocínio pode ser mais lento e verboso, então utilize-o somente quando necessário. Você pode também encontrar variantes ou versões atualizadas, como a DeepSeek-V3.1-Terminus, dependendo das disponibilizações na API (essas variantes geralmente trazem ajustes de estabilidade). - Trate a resposta: A API retornará um objeto JSON contendo as escolhas de completions. Extraia o conteúdo da mensagem (
response['choices'][0]['message']['content']no exemplo Python acima) para obter o texto gerado. Se estiver usando streaming, processe os chunks conforme chegam para uma experiência de resposta em tempo real na aplicação. - Erros e limites: Atente-se a possíveis códigos de erro e limites de taxa (rate limit) da API. A documentação do DeepSeek fornece detalhes de códigos de status e como proceder em cada caso. Também monitore o uso de tokens, já que custos e limites normalmente são baseados na quantidade de tokens enviados e recebidos.
Cabe mencionar que, além da API nativa, o DeepSeek V3.1 também está disponível em alguns ecossistemas de nuvem. Por exemplo, a Amazon Web Services integrou o modelo ao serviço Amazon Bedrock, onde ele pode ser invocado como um modelo fundamental gerenciado. Isso pode ser vantajoso para quem já opera na AWS, oferecendo escalabilidade e segurança empresarial prontas (incluindo recursos como monitoramento de uso e guardrails de IA da plataforma Bedrock). Outro hub é o OpenRouter e a plataforma Together, que oferecem acesso via API a múltiplos modelos de IA, incluindo o DeepSeek V3.1, muitas vezes com opções de chave unificada e rotas de inferência otimizadas.
Em resumo, integrar via API é ideal para começar rapidamente e escalar conforme a demanda, pagando pelo uso conforme necessário.
Integração Local / Self-Hosted (open-source)
Para times que desejam autonomia total ou evitar custos por chamada, executar o DeepSeek V3.1 localmente ou em servidores privados é uma opção. No entanto, devido ao tamanho do modelo, é um caminho que requer recursos de hardware especializados.
Confira as orientações para integração self-hosted:
- Obtenha os pesos do modelo: Os pesos do DeepSeek V3.1 podem ser baixados do repositório oficial no Hugging Face. Há duas versões principais: a Base (pré-treinada, sem instruções) e a Instrução/Chat (refinada para diálogos e uso interativo). Para a maioria das aplicações, você vai querer a segunda, que geralmente está disponível no repositório
deepseek-ai/DeepSeek-V3.1(safWeights, ou arquivos.bincaso fornecidos). Certifique-se de ter espaço em disco suficiente, pois trata-se de um modelo muito grande. - Prepare o ambiente de execução: Será necessário dispor de GPUs de alta memória (ou um conjunto delas). O modelo ativo ocupa dezenas de GB de VRAM mesmo em formato de meia precisão (FP16 or BF16). Placas como NVIDIA A100, H100, ou clusters com múltiplas GPUs interconectadas são recomendadas. Alternativamente, pode-se usar quantização int8/int4 para reduzir o tamanho em troca de alguma perda de qualidade, usando bibliotecas como
bitsandbytesou runtimes especializados. Instale também a versão adequada do Transformers e possivelmente Accelerate (da Hugging Face) para manejar dispatch em múltiplas GPUs. - Carregue com eficiência: Ao carregar o modelo via código (como no exemplo anterior), utilize parâmetros como
device_map="auto"ou especifique manualmente a divisão de camadas entre GPUs. Verifique se a opção de usar pesos em formatosafetensorsestá disponível, pois é mais segura e rápida. Considere ativar offloading para CPU ou disco, se a biblioteca suportar, caso a memória das GPUs não seja suficiente para todos os pesos de uma vez. - Inferência e latência: Esteja ciente de que a latência de inferência local dependerá do seu hardware e do comprimento da entrada/saída. Com 128K de contexto possível, entradas muito grandes podem resultar em tempos de resposta mais altos. Utilize técnicas como context caching se disponíveis (o DeepSeek possui um recurso de cache de contexto em sua API, que poderia ser reproduzido localmente salvando estados de modelo para evitar recomputar até certa parte da sequência). Ajustar a configuração de batch size também impacta: para poucas requisições simultâneas, mantenha batch pequeno para não ocupar memória desnecessariamente.
- Escalabilidade e servidores de modelo: Para servir o modelo a múltiplos usuários, avalie usar servidores de inferência otimizados, como o Text Generation Inference (TGI) da Hugging Face, ou frameworks como NVIDIA Triton Inference Server. Eles facilitam o deployment, gerenciando filas, threads e até divisão de carga entre GPUs automaticamente. Também permitem habilitar endpoints REST ou gRPC para que sua aplicação converse com o modelo localmente via rede interna.
- Atualizações e versões: A comunidade DeepSeek pode lançar patches ou versões refinadas (por exemplo, a variante V3.1-Terminus mencionada nos documentos). Ao hospedar localmente, fique atento a essas atualizações que podem melhorar a qualidade ou desempenho. Atualize os pesos ou aplique fine-tuning suplementar conforme necessário, sempre testando o impacto no seu caso de uso.
Em resumo, a integração local dá controle total e potencial economia em larga escala, mas exige investimento inicial em infraestrutura e expertise em engenharia de ML para otimização. Já a integração via API terceiriza toda a complexidade, ao custo de depender de um serviço externo e incorrer em despesas baseadas em uso.

Em ambos os casos, o DeepSeek V3.1 foi pensado para ser desenvolvedor-friendly, reutilizando padrões da indústria e sendo aberto a adaptações, então escolha o caminho que melhor se alinha ao seu projeto.
Benefícios de Adoção para Equipes de Engenharia, Pesquisa ou Produtos
A incorporação do DeepSeek V3.1 pode trazer diversos benefícios para diferentes perfis de equipes dentro de uma organização de tecnologia.
A seguir, destacamos as vantagens mais notáveis para times de engenharia de software, grupos de pesquisa em IA e equipes de gerenciamento de produto que decidam adotar este modelo de linguagem:
- Aceleração do Desenvolvimento (Engenharia): Para equipes de engenharia de software, ter o DeepSeek V3.1 como assistente significa ganhar produtividade no dia a dia. Tarefas como escrever código boilerplate, gerar testes unitários, documentar funções ou converter especificações em código podem ser agilizadas com a ajuda do modelo. Ele pode atuar como um “programador adicional” na equipe, fornecendo sugestões 24/7. Além disso, sua capacidade de analisar e explicar código ajuda na revisão (code review) e na transferência de conhecimento entre desenvolvedores. O resultado é um ciclo de desenvolvimento mais rápido, com menos bloqueios em pesquisas ou depuração, permitindo que os engenheiros foquem em aspectos mais complexos enquanto o modelo cuida do trivial.
- Inovação e Experimentação (Pesquisa): Para grupos de P&D em IA, o DeepSeek V3.1 representa uma plataforma avançada de experimentação. Por ser open-source e suportar arquitetura de raciocínio, os pesquisadores podem investigar novas técnicas de prompting, interpretabilidade de cadeia de pensamento, e até adaptar o modelo para tarefas específicas via fine-tuning. A habilidade de usar diferentes idiomas e lidar com contextos longos também abre portas para pesquisa em processamento de linguagem natural multilíngue e compreensão de longos contextos (desafios como resumir livros inteiros, por exemplo). Equipes acadêmicas ou laboratórios industriais podem economizar tempo usando um modelo de última geração pronto, em vez de treinar do zero, concentrando esforços em acrescentar camadas de valor ou realizar avaliações extensivas. Em suma, o DeepSeek V3.1 permite explorar fronteiras do estado-da-arte com um recurso acessível e personalizável.
- Diferenciação de Produto (Produto/Negócio): Do ponto de vista de produto, integrar o DeepSeek V3.1 em aplicações voltadas aos usuários finais pode elevar significativamente a experiência do usuário. Funcionalidades inteligentes como atendimento virtual humanizado, preenchimento automático inteligente, busca semântica aprimorada e análise instantânea de dados podem se tornar diferenciais competitivos quando impulsionadas por um modelo tão poderoso. Equipes de produto podem testar rapidamente novas ideias aproveitando a versatilidade do modelo, validando casos de uso com usuários reais. Além disso, pelo fato de o modelo ser open-source, há mais liberdade para ajustá-lo a requisitos específicos do negócio (por exemplo, restringir certos comportamentos, injetar conhecimento proprietário da empresa, rodar em ambiente on-premises garantindo privacidade dos dados). Assim, a adoção do DeepSeek V3.1 pode reduzir time-to-market de funcionalidades de IA e oferecer um alto valor agregado percebido pelos clientes, seja em um software corporativo, em uma plataforma SaaS ou em um aplicativo consumer.
- Escalabilidade com Qualidade: Independente do tipo de equipe, um benefício transversal é a capacidade do DeepSeek V3.1 de escalar atendimento e suporte com manutenção de qualidade. Por exemplo, uma central de suporte automatizada com esse modelo pode lidar com milhares de interações em paralelo, em múltiplos idiomas, resolvendo dúvidas comuns e casos complexos com raciocínio, tudo isso 24 horas por dia. Isso libera as equipes humanas para focar em casos realmente excepcionais. A padronização das respostas e a possibilidade de auditar a cadeia de pensamento (quando usada internamente) também ajudam a manter consistência e conformidade, importante para domínios como saúde, finanças e jurídico. Logo, adotar o DeepSeek V3.1 pode tanto reduzir custos operacionais quanto melhorar métricas de satisfação do usuário final, ao mesmo tempo.
Em termos gerais, o DeepSeek V3.1 empodera times técnicos a fazer mais com menos esforço: seja escrever código melhor e mais rápido, inovar em pesquisas de IA, ou entregar produtos inteligentes que encantam os usuários. Esses benefícios, é claro, vêm juntamente com responsabilidades de gerenciamento do uso da IA – como garantias de qualidade, ética e performance, que discutiremos nas próximas seções de boas práticas e limitações.
Boas Práticas para Utilização Eficaz
Para extrair o máximo do DeepSeek V3.1 em suas aplicações, é importante seguir algumas boas práticas no uso do modelo. Abaixo compilamos dicas e considerações que podem ajudar desenvolvedores e equipes a utilizá-lo de forma eficiente, eficaz e segura:
- Escolha do modo de operação: Decida antecipadamente qual modo (raciocínio ou direto) é mais adequado para cada tarefa. Se você precisa de respostas rápidas para perguntas diretas ou conversas simples, utilize o modo não-raciocínio (respostas diretas). Para problemas complexos que envolvem múltiplas etapas de lógica, cálculos ou busca de informações, habilite o modo de raciocínio para que o modelo possa pensar em voz alta e chegar a uma conclusão mais confiável. Lembre-se de que o modo de raciocínio pode introduzir latência extra e respostas mais longas; portanto, use-o somente onde o ganho de qualidade justificar.
- Diretrizes claras no prompt (System messages): Aproveite as mensagens de papel system no formato de chat para configurar o comportamento do modelo conforme sua necessidade. Por exemplo, instrua-o sobre o estilo de resposta desejado (“responda de forma concisa em uma lista numerada”, ou “forneça explicações técnicas quando possível”). O DeepSeek V3.1 tende a seguir bem as orientações do sistema. Dar um contexto inicial claro e fixar regras no prompt ajuda a alinhar o modelo à sua aplicação e também a evitar respostas inadequadas.
- Gerenciamento de contexto extenso: Embora 128K tokens estejam disponíveis, nem sempre é eficaz usar todo esse espaço indiscriminadamente. Insira no prompt apenas informações relevantes para a tarefa atual, mantendo contexto focado. Se você tiver um histórico muito longo de conversa, considere resumir partes anteriores ou limpar interações obsoletas para economizar custo computacional e reduzir a possibilidade de contradições. Utilize técnicas de windowing (janela deslizante) ou resumos automáticos para manter o contexto manejável. E caso esteja desenvolvendo uma aplicação de leitura de documentos extensos, experimente quebrar o documento em partes e usar perguntas focadas em vez de colocar todo o texto de uma vez, se a performance estiver aquém do esperado.
- Uso de ferramentas e formatação de saída: Se for usar o recurso de chamada de ferramentas, siga rigorosamente o formato estipulado nos documentos (uso de demarcadores especiais como
<tool_calls_begin>etc.). O modelo foi treinado para reconhecer e produzir esse formato exato. Uma formatação inconsistente pode fazer com que ele não acione corretamente a ferramenta. Da mesma forma, ao utilizar o modo de raciocínio com agentes, certifique-se de capturar e tratar adequadamente as partes do pensamento (<think>...</think>) separadas da resposta final. Em uma aplicação real, geralmente o chain-of-thought não é exibido ao usuário final – em vez disso, é usado internamente para aumentar a confiabilidade da resposta. Portanto, projete o sistema de forma que essas informações de raciocínio possam ser ignoradas ou logadas para auditoria, mas não enviadas diretamente ao front-end do usuário. - Ajuste de parâmetros de geração: Experimente configurações de geração (parâmetros do
generate()ou da API) para obter o melhor resultado. O temperature controla a aleatoriedade: valores mais altos (>0.8) geram respostas criativas porém potencialmente divagantes, enquanto valores baixos (~0) tornam a saída mais determinística e direta. O max_new_tokens deve ser adequado ao tipo de resposta esperada – evite valores muito altos desnecessariamente, para não gastar recursos com respostas prolixas ou risco do modelo sair do tema. Use stop sequences se precisar que a geração termine ao encontrar certo padrão (por exemplo, encerrar no token de fim de pensamento ou antes de alguma delimitação). - Monitoramento e controle de qualidade: Mesmo modelos avançados podem produzir saídas inesperadas ou incorretas. Tenha sempre camadas de verificação nas suas aplicações. Para usos críticos, implemente checagens de factualidade (comparando respostas com fontes externas) ou delimite o domínio de resposta do modelo. Utilize filtros de conteúdo se sua aplicação for pública, para evitar geração de texto inadequado. Aproveite que o DeepSeek V3.1 permite ver a cadeia de raciocínio (no modo pensado) para auditar como a resposta foi obtida, o que pode ajudar a identificar onde algo deu errado caso haja alucinação ou viés. Lembre-se também de atualizar seu modelo ou refiná-lo se notar sistematicamente erros específicos no contexto da sua aplicação.
- Context Caching e otimizações: Se você fizer chamadas repetidas com conteúdos similares (por exemplo, várias perguntas sobre um mesmo texto longo fornecido), considere reutilizar partes do contexto já embebido. A equipe DeepSeek menciona um recurso de cache de contexto para evitar cobranças duplicadas. Ao implementar localmente, você pode manter embeddings ou estados ocultos de camadas para não recalcular do zero quando apenas pequenos trechos do input mudarem entre chamadas. Isso requer um gerenciamento mais complexo do pipeline de inferência, mas pode trazer ganhos enormes de desempenho em cenários apropriados.
Seguindo essas práticas, você tende a obter resultados mais consistentes e a utilizar os recursos computacionais de forma otimizada. O DeepSeek V3.1 é uma ferramenta poderosa, mas como qualquer tecnologia, seu valor depende de um uso inteligente e responsável por parte dos desenvolvedores.
Na próxima seção, abordaremos algumas considerações sobre desempenho e limitações conhecidas do modelo, complementando as expectativas de uso com uma visão realista.
Considerações sobre Desempenho e Limitações
Apesar de todos os avanços e capacidades impressionantes do DeepSeek V3.1, é crucial entender que nenhum modelo de IA é perfeito ou ilimitado.
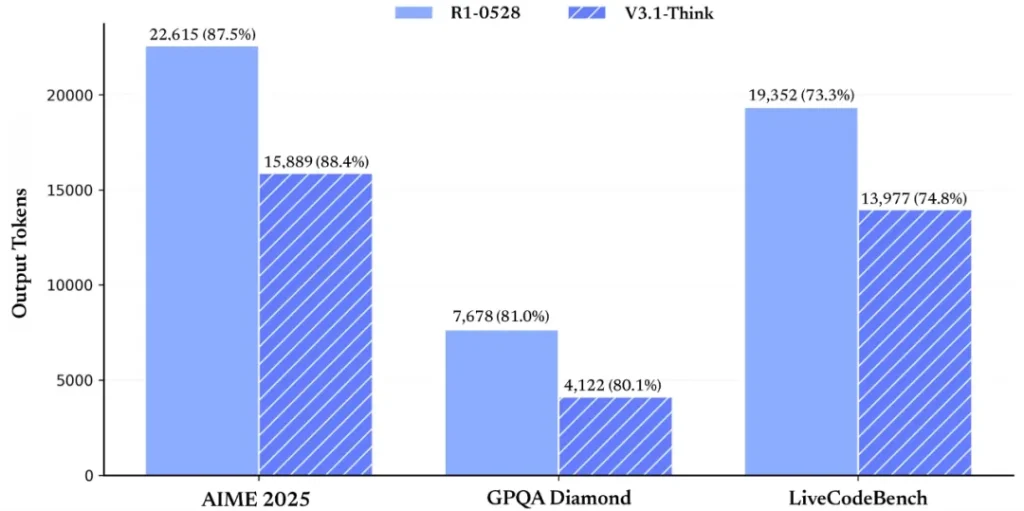
Aqui discutimos algumas considerações importantes de desempenho e limitações para se ter em mente ao trabalhar com o DeepSeek V3.1:
Requisitos Computacionais Elevados: Com 671B parâmetros totais e suporte a contexto de 128K, o DeepSeek V3.1 é inerentemente pesado em termos computacionais. Infernir com esse modelo localmente requer hardware de ponta (GPUs de última geração, muita memória e/ou infraestrutura distribuída). Mesmo via API, consultas com contextos muito longos ou uso intensivo de cadeia de pensamento vão consumir mais tempo e possivelmente acarretar maior custo. Portanto, planeje conforme a escala de uso: para aplicações móveis ou em edge, esse modelo não é adequado; nesses casos, talvez versões menores ou distillates sejam necessárias. No ambiente de servidor, monitore a latência e throughput – pode ser necessário implementar filas de requisição ou limites de tamanho de entrada para manter a responsividade da aplicação.
Tempo de Raciocínio vs. Tempo de Resposta: O modo de raciocínio, apesar de melhorar a qualidade em tarefas complexas, adiciona um overhead no tempo de resposta, pois o modelo “fala sozinho” para chegar à conclusão. Isso significa que, em cenários real-time, ativar cadeia de pensamento pode tornar a interação mais lenta do que o desejável pelo usuário final. Uma abordagem é ativar o raciocínio condicionalmente: por exemplo, se uma pergunta simples for detectada, usar resposta direta; se for uma pergunta analítica ou um pedido de planejamento, então usar raciocínio. Desenhar esse switch de forma inteligente vai ajudar a equilibrar qualidade e velocidade. Benchmarks internos mostraram ganhos grandes de eficiência de raciocínio no V3.1 comparado a versões anteriores, mas ainda assim, cada passo adicional custa alguns centésimos ou décimos de segundo multiplicados pela complexidade da tarefa.
Limites na Qualidade de Resposta: Embora o DeepSeek V3.1 apresente desempenho de ponta em diversos benchmarks (MMLU, CodeBench, etc.), ele não é infalível. Ainda podem ocorrer alucinações – isto é, o modelo inventar fatos inexistentes – especialmente se confrontado com perguntas fora do seu conhecimento ou quando induzido por contexto enganoso. Também existe a possibilidade de erros em tarefas matemáticas de múltiplas etapas ou confusões sutis em linguagens menos comuns, apesar das melhorias. O modelo foi avaliado com resultados muito fortes, por exemplo alcançando >93% em testes de conhecimento geral e resolvendo problemas de matemática avançada com alta taxa de acerto, mas sempre haverá alguma margem de erro. Assim, para aplicações críticas, mantenha um humano no circuito de supervisão ou implemente verificações automáticas complementares.
Viés e Conteúdo Inadequado: Por ser treinado em grandes corpora da internet, o DeepSeek V3.1 pode herdar vieses presentes nesses dados. Esforços de mitigação são aplicados, porém respostas potencialmente enviesadas ou tendenciosas podem ocorrer em tópicos sensíveis (raça, gênero, política, etc.). Da mesma forma, se provocado com instruções inadequadas, pode acabar gerando conteúdo ofensivo ou desaconselhável. É responsabilidade do desenvolvedor implementar filtros de moderação de conteúdo e aderir às diretrizes éticas ao usar o modelo. A vantagem de poder examinar a cadeia de raciocínio é que, internamente, dá para notar se o modelo “pensou” em algo problemático antes de responder – o que pode servir de ponto de intervenção (por exemplo, abortar a resposta se a cadeia de pensamento indicar uma direção proibida). Sempre teste o modelo com casos limites relacionados ao seu domínio de aplicação para conhecer suas falhas, e documente essas limitações para os usuários finais quando couber.
Ausência de Conhecimento Pós-treinamento: A menos que seja explicitamente atualizado, o DeepSeek V3.1 tem uma data de corte no conhecimento de treinamento (provavelmente em torno de meados de 2025, dada sua data de lançamento). Isso significa que eventos, fatos ou dados surgidos após esse período não estarão presentes no modelo. Se perguntado sobre algo muito recente, ele pode não saber ou, pior, tentar chutar uma resposta. Nesses casos, o uso do agente de busca (Search Agent) ou fornecer informações atualizadas via contexto se tornam essenciais. Para manter o modelo útil, considere rotinas de fine-tuning periódico com dados novos ou use integrações com APIs externas para complementar o conhecimento em tempo real.
Tamanho da Saída e Formatação: Com um contexto tão grande, há também o perigo de o modelo gerar respostas extremamente longas ou divagantes se não for orientado. Sempre que solicitar uma resposta, seja específico quanto à extensão ou formato esperado (“resuma em 3 parágrafos”, “liste apenas os 5 principais itens”, etc.). Isso ajudará a conter a verbosidade natural do modelo e garantir respostas mais focadas. Além disso, verifique se as marcações especiais (como as tags de pensamento ou delimitadores de ferramentas) não vazaram para o usuário final indevidamente, o que poderia confundir quem está consumindo a resposta.
Em síntese, o DeepSeek V3.1 traz capacidades extraordinárias, mas demanda um uso consciente de seus limites. Ao planejar um sistema com ele, leve em conta essas considerações para ajustar expectativas e implementar salvaguardas. Feito isso, você poderá colher os benefícios do modelo minimizando riscos de desempenho inadequado ou resultados inesperados.
Conclusão
O DeepSeek V3.1 representa um avanço significativo no campo de modelos de linguagem de IA, unindo alto desempenho, flexibilidade de raciocínio e suporte a ferramentas em uma única plataforma aberta. Neste artigo, exploramos desde a sua arquitetura inovadora – com centenas de bilhões de parâmetros e janelas de contexto nunca antes vistas – até as diversas aplicações práticas que ele viabiliza para desenvolvedores, como geração de código, agentes autônomos e análise de informação em larga escala. Também discutimos exemplos concretos de implementação, tanto via API quanto localmente, e destacamos as melhores práticas para utilizar o modelo de forma eficaz e responsável.
Em um mundo onde a IA está se tornando peça-chave de produtos e operações, adotar um modelo como o DeepSeek V3.1 pode dar às equipes uma vantagem competitiva, acelerando processos e abrindo novas oportunidades de inovação. Seja para melhorar a produtividade dos engenheiros, criar experiências de usuário mais inteligentes ou conduzir pesquisas de ponta, o DeepSeek V3.1 oferece uma base sólida e comprovada (com a comunidade já reportando sucesso em diversos benchmarks e cenários reais).
Nossa recomendação final é: experimente o DeepSeek V3.1 em seu contexto específico. Cada projeto tem necessidades únicas, e somente testando o modelo com seus próprios dados e casos de uso você poderá avaliar todo o seu potencial. Você pode começar hoje mesmo fazendo uma chamada simples na API ou baixando o modelo do Hugging Face e executando um exemplo local. A comunidade DeepSeek oferece documentação e suporte ativo (Discord, GitHub) para ajudar nas etapas iniciais.
Não fique para trás na evolução da IA generativa – considere integrar o DeepSeek V3.1 em seu stack de tecnologia e descubra como um modelo de linguagem avançado pode transformar a maneira como sua equipe desenvolve e entrega valor. Faça um teste, explore seus recursos e prepare-se para atingir novos patamares em seus projetos de IA.


