
O DeepSeek R1 é um modelo de linguagem de primeira geração voltado principalmente ao raciocínio avançado e foi lançado em 20 de janeiro de 2025 pela DeepSeek.
Trata-se de uma inteligência artificial do tipo LLM (Large Language Model) de código aberto, distribuída sob licença MIT, cuja proposta principal é democratizar o acesso a capacidades de raciocínio antes restritas a modelos proprietários de ponta.
Diferentemente de muitos modelos que apenas predizem texto com base em padrões, o DeepSeek R1 foca em entender e resolver problemas passo a passo, destacando-se em inferência lógica, resolução de problemas matemáticos complexos e reflexão sobre suas respostas.
Em outras palavras, ele foi projetado para “pensar” de forma estruturada, o que melhora a precisão, a confiabilidade e a transparência em aplicações de IA que exigem tomada de decisão ou explicações detalhadas.
Como um modelo abertamente disponibilizado, o DeepSeek R1 chamou atenção imediata da comunidade de desenvolvedores.
Logo após seu lançamento, tornou-se um dos modelos mais baixados e populares no Hugging Face, provando o enorme interesse por soluções abertas com alto desempenho.
Seu diferencial está em oferecer desempenho de nível industrial em tarefas de raciocínio, matemática e código, mas sem as barreiras de acesso típicas de soluções fechadas, sejam elas custo elevado, limitações de uso ou falta de transparência.
A seguir, exploraremos em detalhes a arquitetura e capacidades técnicas do DeepSeek R1, suas aplicações práticas para desenvolvedores, exemplos de uso em código, formas de integração, benefícios e também as melhores práticas para obter resultados ideais com este modelo inovador.
Arquitetura Técnica e Capacidades do Modelo
Parâmetros e Arquitetura Mixture-of-Experts (MoE)

Tecnicamente, o DeepSeek R1 impressiona por seu porte: ele implementa uma arquitetura do tipo Mixture of Experts (MoE), combinando múltiplas redes especializadas (experts) em um só modelo. No total, o modelo possui 671 bilhões de parâmetros, porém apenas cerca de 37 bilhões de parâmetros são ativados a cada forward pass (inferência) graças ao mecanismo MoE. Isso significa que, embora haja um número massivo de parâmetros disponíveis, o modelo encaminha cada consulta apenas aos especialistas relevantes, em vez de usar todos os parâmetros de uma vez. O resultado é um modelo altamente escalável, capaz de aproveitar especialistas diferentes para domínios distintos, mas de forma eficiente – reduzindo o custo computacional e de memória em comparação a um modelo denso tradicional do mesmo tamanho. Em outras palavras, o DeepSeek R1 atinge um equilíbrio entre tamanho e eficiência: ele tem a capacidade expressiva de um modelo gigantesco, sem exigir proporcionalmente mais recursos em cada uso.
Esse design é construído sobre a base do modelo DeepSeek V3, que serviu como ponto de partida multiespecializado para o R1. Uma característica técnica crucial é a sua janela de contexto extremamente longa, de até 128 mil tokens. Para desenvolvedores, isso significa que o DeepSeek R1 pode considerar entradas muito extensas – por exemplo, vários documentos, códigos-fonte completos ou grandes conjuntos de dados textuais – dentro de uma única interação, mantendo coerência e raciocínio sobre toda essa informação. Esse contexto longo (128k) supera em ordens de grandeza os contextos típicos de outros modelos e viabiliza casos de uso como análise de logs extensos, revisão de código base inteiro ou sumários de relatórios volumosos, tudo em uma única resposta da IA.
Raciocínio e Aprendizado por Reforço
O carro-chefe do DeepSeek R1 é sua capacidade de raciocinar de forma encadeada (chain-of-thought). Durante seu desenvolvimento, a DeepSeek adotou uma estratégia inédita: o modelo precursor DeepSeek-R1-Zero foi treinado apenas com Aprendizado por Reforço (RL) em larga escala, sem ajuste fino supervisionado inicial, levando o modelo a desenvolver comportamentos de raciocínio de forma autônoma. Esse processo revelou que a IA aprendeu a “pensar” passo a passo, verificar suas próprias respostas e até corrigir erros, tudo emergindo a partir das recompensas de RL que incentivavam soluções corretas. No entanto, o R1-Zero sofria com alguns problemas como repetições e respostas pouco legíveis. Para resolver isso, o DeepSeek R1 completo incorporou etapas adicionais de treinamento supervisionado e novos ciclos de RL. Em um pipeline de quatro estágios, a equipe primeiro realizou um “cold start” com milhares de exemplos de cadeia de raciocínio (SFT de raciocínio), depois um RL voltado a critérios de correção/formatação, seguido de um novo ajuste fino supervisionado (com dados gerados e refinados pelo modelo anterior) e por fim outro RL para alinhamento geral com preferências humanas e garantia de segurança. Essa combinação de SFT + RL, com RL antes e depois do SFT, provou-se muito eficaz em fomentar habilidades avançadas de raciocínio no modelo.
Como resultado, o DeepSeek R1 apresenta comportamentos de “meta-cognição”, algo como pensar sobre o próprio pensamento. Por exemplo, ele é capaz de elaborar soluções passo a passo, revisitando etapas intermediárias para checar coerência, e até detectar possíveis equívocos em seu raciocínio. Há relatos de que o modelo às vezes demonstra um “momento eureka”, chegando a dar um passo atrás, identificar uma falha lógica e autocorrigir sua resposta durante a geração. Esse nível de reflexão interna é um diferencial importante para aplicações que exigem alta exatidão, pois o modelo não se apressa em uma resposta final – ele realmente “pensa” no problema, de forma similar a como um humano experiente dividiria um problema complexo em subproblemas e verificaria cada parte.
Capacidade de Geração e Execução de Código
Outra área de destaque do DeepSeek R1 são suas habilidades em tarefas de programação. Graças ao foco em raciocínio e aos dados de treino envolvendo desafios de código, o modelo supera esforços open-source anteriores na geração e depuração de código.
Por exemplo, em avaliações de desafios algorítmicos do estilo Codeforces, ele atingiu uma classificação aproximada de Elo 2029, indicando performance de nível avançado em competições de programação. Para desenvolvedores, isso se traduz em um assistente capaz de escrever trechos de código complexos, explicar algoritmos, encontrar bugs lógicos e propor correções com alto acerto.
Além da geração de código em si, o DeepSeek R1 pode ser integrado em fluxos de trabalho de execução de código e ferramentas. A API do modelo suporta um recurso chamado Function Calling, similar à funcionalidade presente em algumas APIs de IA comerciais, que permite ao modelo invocar funções definidas pelo desenvolvedor. Na prática, o modelo pode receber uma lista de ferramentas ou funções externas (por exemplo, uma função Python de consultar banco de dados ou verificar o clima) e então escolher chamar essas funções quando necessário. Isso significa que é possível construir agentes inteligentes com o DeepSeek R1 que, além de conversar, executam ações – por exemplo, executar um trecho de código Python, buscar uma informação via API externa ou interagir com um sistema operacional, tudo guiado pela inteligência do modelo. Vale notar que o modelo em si não “executa código” diretamente, mas ele é capaz de gerar chamadas de função estruturadas em JSON conforme o esquema definido pelo desenvolvedor, permitindo integração segura e controlada com qualquer serviço ou código externo. Essa capacidade expande enormemente o leque de aplicações: com DeepSeek R1, pode-se criar desde bots de atendimento que consultam bases de dados em tempo real, até assistentes de programação que compilam e executam trechos de código para testar soluções.
Contexto Longo e Memória Estendida
Como mencionado, o DeepSeek R1 suporta contexto de até 128k tokens, o que é ordens de grandeza maior do que a maioria dos modelos de linguagem comuns. Para se ter ideia, 128k tokens equivalem a aproximadamente 100 mil palavras, ou centenas de páginas de texto. Essa janela de contexto longa permite que o modelo mantenha memória de conversas prolongadas ou processe documentos extensos integralmente. Desenvolvedores podem aproveitar isso para analisar grandes volumes de dados textuais de uma só vez – por exemplo, alimentar o modelo com logs completos de um servidor para que ele identifique padrões de erro, ou fornecer todo o código-fonte de um projeto e pedir um relatório de possíveis vulnerabilidades. Com um contexto tão amplo, reduz-se a necessidade de resumir ou dividir entradas, já que o modelo consegue lidar com muita informação concomitantemente.
É importante destacar que trabalhar com um contexto gigante requer cuidado: nem sempre fornecer 100k tokens de entrada é vantajoso, pois isso pode aumentar o tempo de processamento e custo. No entanto, para casos em que toda a informação distribuída é relevante para a tarefa, o DeepSeek R1 oferece uma solução sem paralelos. Essa capacidade também abre caminho para conversas multi-turn realmente longas, em que o modelo lembra de detalhes mencionados dezenas de interações atrás, tornando-o ideal para assistentes conversacionais técnicos que acompanham contexto complexo (como histórico de comandos de um usuário ou dados de sessão).
Aplicações Práticas em Engenharia de Software e Mais
O DeepSeek R1, com seu raciocínio poderoso e flexível, se presta a diversos cenários no dia a dia de desenvolvedores e empresas de tecnologia. A seguir, listamos algumas das aplicações práticas de maior impacto:
- Engenharia de Software: O modelo pode atuar como um assistente de programação capaz de gerar código sob demanda, sugerir melhorias e identificar bugs. Desenvolvedores podem utilizá-lo para autocompletar funções, refatorar trechos de código, documentar APIs, ou mesmo realizar code review automatizado, onde o modelo explica trechos complexos e aponta possíveis problemas lógicos. Graças ao seu forte raciocínio, o DeepSeek R1 consegue analisar requisitos e quebrar problemas de programação em etapas, auxiliando no desenvolvimento de algoritmos. Por exemplo, pode-se descrever em linguagem natural o comportamento desejado de uma função, e o modelo devolve um esboço de implementação em Python, junto com explicações passo a passo do raciocínio por trás do código gerado.
- Automação de Tarefas e DevOps: Em tarefas repetitivas ou de configuração de sistemas, o DeepSeek R1 pode agilizar o trabalho. Ele pode gerar scripts de automação (em Bash, PowerShell, etc.), arquivos de configuração (Dockerfiles, YAML de CI/CD) ou até infraestrutura como código. Com a funcionalidade de chamar funções externas, é possível integrá-lo a pipelines de DevOps: imagine um bot que lê mensagens de erro de deploy e automaticamente aciona comandos para correção. Sua habilidade de entender instruções complexas o torna apto a orquestrar fluxos de trabalho, agindo como um coordenador inteligente que interpreta comandos de alto nível e executa as etapas necessárias via integrações (por exemplo, interagindo com APIs de cloud).
- Análise de Dados e Ciência de Dados: O DeepSeek R1 consegue auxiliar na análise exploratória de dados, interpretação de resultados estatísticos e geração de visualizações. Um cientista de dados pode fornecer descrições de um dataset e pedir ao modelo que escreva código em Python para limpeza e análise, ou até realizar perguntas em linguagem natural sobre os dados. Por ter forte fundamento matemático, o modelo é capaz de resolver problemas quantitativos, sugerir modelos de Machine Learning adequados e explicar métricas de performance. Além disso, com contexto longo, ele pode digerir relatórios inteiros ou documentação técnica de projetos de dados, resumindo insights ou destacando tendências encontradas. Em empresas, pode atuar como um analista virtual, respondendo questões do tipo “qual região teve o maior crescimento de vendas no último trimestre?” a partir de planilhas fornecidas no prompt, mostrando o raciocínio e cálculos por trás da resposta.
- Agentes Inteligentes e Sistemas Autônomos: Graças à combinação de raciocínio estruturado e capacidade de executar funções, o DeepSeek R1 é ideal para criar agentes de IA autônomos. Esses agentes podem perceber o ambiente, planejar ações e executá-las em sequência, tudo orientado pela inteligência do modelo. Por exemplo, no domínio de suporte ao cliente, um agente pode consultar bancos de dados internos, aplicar lógica de negócio (via funções) e formular respostas personalizadas aos usuários, mantendo contexto de toda a conversa. Em robótica ou IoT, o modelo pode receber dados de sensores, analisar a situação (ex.: detectar anomalias) e tomar decisões em tempo real, controlando dispositivos através de funções. A habilidade de real-time decision-making mencionada na proposta do DeepSeek R1 reflete-se aqui: desenvolvedores podem confiar no modelo para tomar decisões autônomas informadas, pois ele consegue avaliar implicações lógicas de cada ação antes de executá-la. Isso possibilita agentes mais seguros e eficientes, já que o modelo “pensa duas vezes” antes de agir.
- Outras Aplicações Diversas: As possibilidades se estendem muito além. Na educação, o DeepSeek R1 pode atuar como tutor virtual, resolvendo problemas passo a passo e explicando conceitos para estudantes (por exemplo, demonstrando a resolução de uma equação complexa). Em pesquisa científica, pode ajudar a resumir artigos extensos, verificar coerência em demonstrações lógicas ou até sugerir hipóteses baseadas em dados fornecidos. Em conteúdo e criação, embora o foco seja raciocínio, ele também consegue gerar textos estruturados – por exemplo, produzir relatórios técnicos, resumos executivos ou responder perguntas em linguagem natural com alta acurácia factual. Em resumo, qualquer tarefa que se beneficie de análise lógica aprofundada, manipulação de código ou interpretação de grande contexto pode encontrar no DeepSeek R1 uma ferramenta valiosa.
Exemplos de Uso com Código
Para ilustrar como desenvolvedores podem interagir com o DeepSeek R1, vejamos alguns exemplos de uso práticos tanto via API REST quanto localmente em Python.
Exemplo 1: Chamada via API (REST) – O DeepSeek R1 disponibiliza uma API compatível com o formato da API do OpenAI, o que facilita sua adoção em sistemas existentes. Após obter uma API key, você pode fazer chamadas HTTP para a API do DeepSeek. Por exemplo, usando cURL:
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer SEU_DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-reasoner",
"messages": [
{"role": "system", "content": "Você é um assistente de programação útil."},
{"role": "user", "content": "Explique o código a seguir e sugira melhorias:\n\n<trecho de código aqui>"}
]
}'
No exemplo acima, definimos o modelo como "deepseek-reasoner", que corresponde ao modo de raciocínio do DeepSeek R1 na API. Passamos uma mensagem de sistema (opcional) definindo o papel da IA e uma mensagem de usuário com o pedido – no caso, explicação e melhoria de um trecho de código. A resposta da API será um JSON contendo a mensagem gerada pelo modelo (entre outros metadados), que podemos extrair para obter o conteúdo textual da resposta.
Exemplo 2: Uso com SDK Python – Podemos alcançar o mesmo resultado usando a biblioteca Python do OpenAI (aproveitando a compatibilidade do endpoint). No snippet abaixo, utilizamos o SDK para enviar uma conversa e receber a resposta do modelo:
import os
import openai
# Configurar chave de API e endpoint do DeepSeek
openai.api_key = os.getenv("DEEPSEEK_API_KEY")
openai.api_base = "https://api.deepseek.com/v1" # Base URL compatível
resposta = openai.ChatCompletion.create(
model="deepseek-reasoner",
messages=[
{"role": "system", "content": "Você é um assistente de programação útil."},
{"role": "user", "content": "Explique o código a seguir e sugira melhorias:\n\n<trecho de código aqui>"}
]
)
print(resposta.choices[0].message.content)
Note que no código acima usamos api_base apontando para o endpoint do DeepSeek, mas mantemos as chamadas através do objeto openai.ChatCompletion – assim, qualquer aplicação que já utilize a API do OpenAI pode ser adaptada para o DeepSeek R1 com alterações mínimas. A resposta impressa conterá a explicação detalhada do código e as sugestões de melhoria, demonstrando na prática a utilidade do modelo para revisão de código.
Exemplo 3: Uso Local com Modelo Distill – Por ser open-source, também é possível rodar o DeepSeek R1 localmente, especialmente usando as versões distill (modelos menores derivados do R1). Suponha que queiramos usar a variante de 7 bilhões de parâmetros (destilada a partir do DeepSeek R1) localmente via Hugging Face Transformers. O código seria algo como:
from transformers import AutoModelForCausalLM, AutoTokenizer
modelo = "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"
tokenizer = AutoTokenizer.from_pretrained(modelo, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(modelo, device_map="auto", torch_dtype="auto")
prompt = "Pergunta: Qual a diferença entre uma fila e uma pilha em Ciência da Computação?\nResposta:"
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
output_ids = model.generate(input_ids, max_new_tokens=200, temperature=0.7)
resposta = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(resposta)
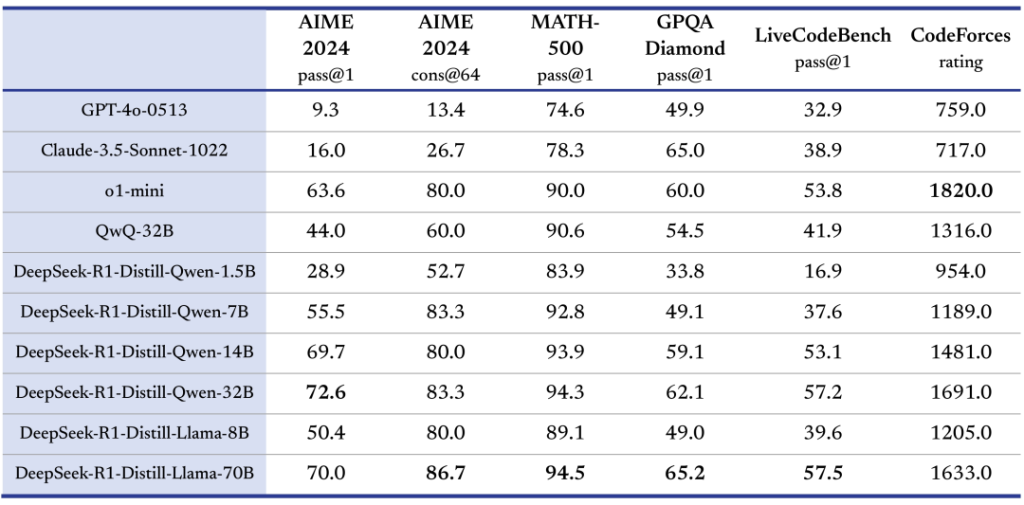
Nesse exemplo, carregamos o modelo DeepSeek-R1-Distill-Qwen-7B (uma versão de ~7B de parâmetros compatível com Transformers) e pedimos que responda a uma pergunta técnica. As versões destiladas usam arquiteturas base populares (como Qwen ou Llama) e podem ser executadas em hardware mais modesto – por exemplo, um modelo de 7B pode rodar em uma GPU de 16 GB VRAM sem problemas. Já a versão completa de 671B (DeepSeek R1 original) exige infraestrutura altamente especializada (múltiplas GPUs e software de inferência específico, como vLLM), portanto a maioria dos desenvolvedores optará por consumir o modelo via API ou usar os distilled models localmente.
Como Integrar o Modelo via API ou Localmente
A integração do DeepSeek R1 em projetos é bastante flexível, atendendo tanto quem prefere uma solução na nuvem via API quanto aqueles que buscam rodar o modelo localmente ou em ambiente próprio.
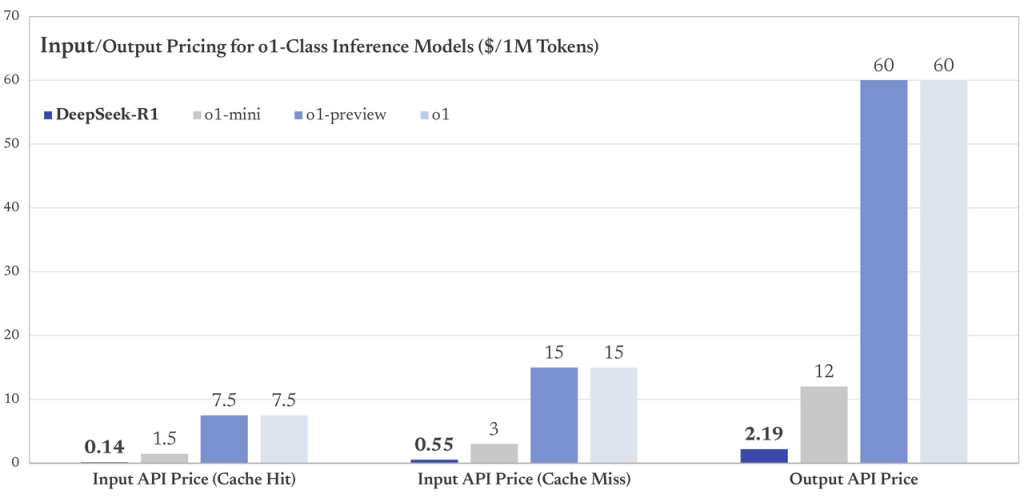
Integração via API: A DeepSeek oferece uma API de uso imediato, que torna a adoção do R1 muito simples. Como mostrado nos exemplos, a API foi concebida para ser compatível com o padrão OpenAI, ou seja, endpoints e formatos de chamada muito semelhantes. Basta solicitar uma chave de API no site da DeepSeek e então apontar suas requisições para o endpoint deles (https://api.deepseek.com/v1), usando o nome do modelo desejado (deepseek-reasoner para a versão com raciocínio completo, ou deepseek-chat para um modo conversacional mais rápido). Você pode utilizar clientes HTTP comuns, bibliotecas de SDK (Python, Node, etc.) ou até ferramentas como cURL. A API suporta recursos avançados como streaming de respostas (envio token a token), além de parâmetros ajustáveis (temperatura, número de respostas, etc.). Também conta com funcionalidades como Function Calling (permitindo a interação com ferramentas externas conforme descrito) e Context Caching (cache de contexto para acelerar requisições repetidas). Em termos de custos, a DeepSeek pratica um modelo de cobrança por tokens processados. Conforme informações do lançamento, os preços giram em torno de US$2.19 por 1 milhão de tokens de saída e US$0.55 por 1 milhão de tokens de entrada (sem cache), com descontos significativos quando há cache hit. Esses valores indicam que o uso via API do DeepSeek R1 tende a ser bem mais econômico do que APIs de modelos fechados equivalentes, permitindo que startups e equipes menores usufruam de IA de alto nível com investimento acessível.

Integração Local/On-Premises: Por ser open-source e ter seus pesos disponíveis, o DeepSeek R1 e suas variantes podem ser auto-hospedados. A própria equipe disponibilizou modelos destilados de vários tamanhos (1.5B, 7B, 8B, 14B, 32B, 70B) baseados em arquiteturas consagradas (Qwen 2.5 e Llama 3). Esses modelos menores conservam boa parte das capacidades de raciocínio do R1, porém com requisição de hardware muito menor – viabilizando rodar localmente em GPUs de classe consumidor ou servidores médios. A integração local pode ser feita via frameworks de ML populares: as variantes destiladas são compatíveis com a biblioteca Transformers da Hugging Face, permitindo uso direto com pipelines ou AutoModel (como mostrado no exemplo acima). Para implantar em produção, projetos como vLLM ou text-generation-inference podem ser usados para servir o modelo com eficiência, inclusive em modo distribuído.
Já o modelo completo DeepSeek R1 (671B MoE) demanda maior preparação. Ele requer suporte a modelos MoE – atualmente, a equipe recomenda usar o repositório DeepSeek-V3 (disponível no GitHub) com implementações personalizadas para carregar o modelo. Apesar da complexidade, a vantagem de rodar localmente é ter controle total sobre o modelo e os dados: nenhuma informação sensível precisa sair dos seus servidores, e é possível fazer ajustes finos adicionais se necessário. Também é uma forma de eliminar limites de uso ou rate limits impostos por terceiros. Para muitas organizações, essa autonomia justifica o investimento em infraestrutura.
Resumidamente, se você quer começar rápido, use a API (que em minutos estará respondendo suas requisições). Se você tem necessidades específicas de privacidade, customização ou volume, considere baixar uma versão adequada do modelo e integrá-lo ao seu próprio stack de ML. Vale mencionar que a comunidade em torno do DeepSeek R1 é ativa – há integração com plataformas de inferência como Fireworks AI para quem busca hospedagem gerenciada, além de fóruns (Discord, GitHub) onde desenvolvedores compartilham dicas de deployment.
Benefícios de Adoção para Desenvolvedores e Equipes Técnicas
A adoção do DeepSeek R1 pode trazer diversos benefícios concretos para equipes de desenvolvimento e projetos de IA:
- Custo-Benefício e Acesso Democrático: Sendo open-source e com opção de auto-hospedagem, o DeepSeek R1 elimina custos de licenciamento que modelos fechados costumam ter. Mesmo ao usar a API oficial, o custo por token é significativamente mais baixo do que alternativas de mercado de desempenho similar. Estimativas indicam que operar o R1 pode custar apenas uma fração (20-30%, ou até menos) do que se gastaria usando certos modelos proprietários equivalentes. Isso democratiza o acesso a IA avançada – startups, pesquisadores independentes e times com orçamento limitado podem trabalhar com um modelo de alto nível sem que o custo seja proibitivo.
- Liberdade para Customização: Com acesso completo aos pesos do modelo e código, desenvolvedores têm total liberdade para modificar ou estender o DeepSeek R1 conforme suas necessidades. É possível refiná-lo com dados específicos do seu domínio (realizar fine-tuning adicional), ou até usar técnicas de prompt tuning e adapters para especializá-lo em tarefas muito particulares. A licença MIT permite inclusive uso comercial irrestrito, criação de derivados e integração em produtos fechados. Diferente de serviços SaaS de IA, aqui o controle está nas mãos da equipe técnica – o que abre espaço para inovações e adaptações que seriam impossíveis em plataformas proprietárias.
- Transparência e Confiabilidade: Por ser um projeto aberto, toda a arquitetura e treinamento do DeepSeek R1 foram documentados em relatório técnico e artigo científico disponibilizados publicamente. Isso significa que podemos inspecionar como ele foi treinado, quais dados de exemplo foram usados, quais técnicas de RL e SFT foram aplicadas, etc. Tal transparência ajuda desenvolvedores a confiar mais no modelo, pois diminui o risco de comportamentos inesperados ou vieses ocultos – qualquer um pode auditar e reportar problemas. Além disso, em caso de necessidade de compliance (por exemplo, entender por que o modelo tomou certa decisão em um sistema crítico), ter um modelo aberto facilita explicações e ajustes. Essa confiança é crucial ao aplicar IA em ambientes empresariais e produtos para usuários finais.
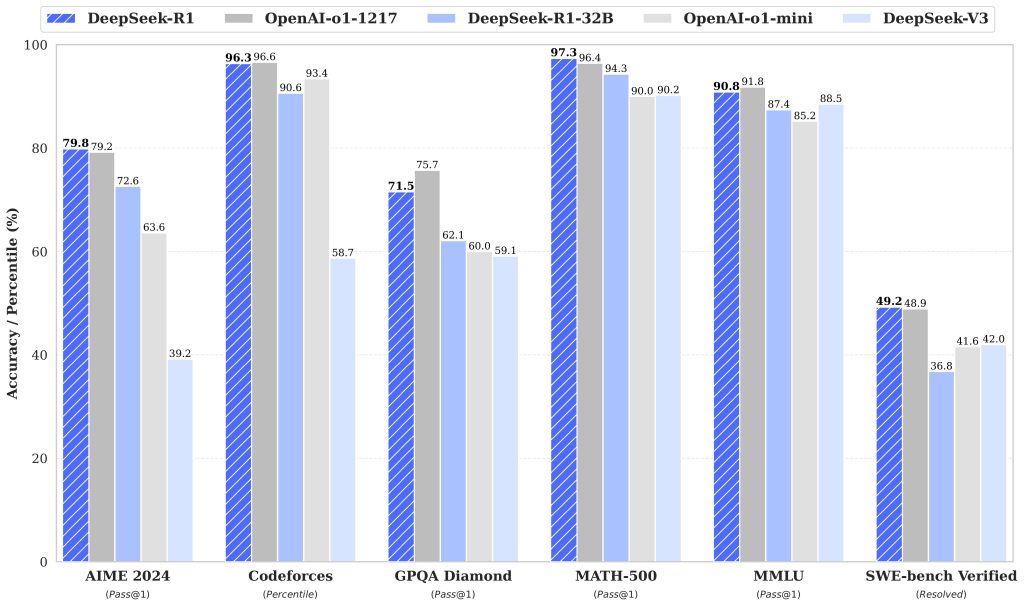
- Desempenho de Ponta em Tarefas Complexas: O DeepSeek R1 provê state-of-the-art em várias métricas de raciocínio, código e matemática. Desenvolvedores notarão que, em tarefas que exigem lógica complexa ou múltiplas etapas de dedução, o modelo se sai excepcionalmente bem – muitas vezes encontrando soluções criativas e corretas onde modelos genéricos podem falhar ou alucinar. Por exemplo, problemas de programação competitiva, quebra-cabeças matemáticos, ou análise de casos de uso detalhados podem ser resolvidos com alta taxa de sucesso pelo R1. Isso pode aumentar a produtividade das equipes: a IA consegue lidar com partes espinhosas de um problema, permitindo que os humanos foquem em supervisão e ajustes finos em vez de fazer tudo do zero.
- Escalabilidade e Especialização Gradual: Graças à arquitetura MoE, existe a possibilidade de expandir ou especializar o modelo sem re-treinar tudo do zero. Novos experts poderiam ser treinados para domínios específicos e adicionados ao conjunto, ou experts existentes podem ser aprimorados individualmente. Para equipes técnicas que planejam longo prazo, isso quer dizer que o DeepSeek R1 pode evoluir junto com o produto: vocês podem alimentar o modelo com conhecimentos do seu nicho, e ao mesmo tempo aproveitar os experts genéricos para o restante. Essa modularidade e escalabilidade embutida protegem o investimento – diferente de modelos fixos, um MoE bem projetado pode se adaptar a crescentes demandas ou novos casos de uso com mais facilidade.
- Comunidade e Colaboração: Como um projeto open-source de destaque (com milhares de estrelas no GitHub e grande volume de downloads), o DeepSeek R1 possui uma comunidade global de usuários e colaboradores. Isso significa suporte coletivo na resolução de problemas, melhorias contínuas sendo incorporadas e um ecossistema de ferramentas ao redor. Para uma equipe técnica, aderir a um modelo suportado por comunidade evita ficar isolado: é provável que outra pessoa já tenha implementado aquela função que você precisa ou passado pelo mesmo desafio de deploy. Há também o benefício de reputação e contratação – trabalhar com tecnologias abertas de ponta como o R1 pode atrair talentos interessados em IA de última geração.
Melhores Práticas de Uso, Precauções e Limites
Assim como qualquer modelo de IA avançado, o DeepSeek R1 requer certas boas práticas para ser usado de forma eficaz e responsável. A seguir estão algumas recomendações e cuidados ao interagir com este modelo:
1. Dê Preferência a Prompts que Estimulem o Raciocínio: Para tirar máximo proveito da capacidade de cadeia de raciocínio do R1, é recomendado formulá-lo comandos que incentivem passos estruturados. Por exemplo, em problemas matemáticos ou lógicos, inclua instruções do tipo “por favor, detalhe o raciocínio passo a passo antes de dar a resposta final”. O próprio guia do modelo sugere instruções explícitas, como “Por favor, pense passo a passo” para garantir que ele não pule direto para a conclusão. Essas instruções ativam o modo “pensante” do modelo, levando a respostas mais confiáveis e explicativas. Evite perguntas extremamente abertas sem contexto; quanto mais complexo o pedido, mais interessante fornecer algum contexto inicial ou quebrar em subtarefas para o modelo.
2. Ajuste a Temperatura e Parâmetros de Geração: O DeepSeek R1 tende a produzir respostas longas e detalhadas devido ao seu treinamento. Para manter coerência, a equipe recomenda usar temperatura em torno de 0.5 a 0.7. Temperaturas muito altas podem tornar a saída criativa demais (e possivelmente fora do foco), enquanto temperaturas muito baixas podem deixá-lo repetitivo. No geral, um valor médio (0.6 é citado como ideal) previne tanto devaneios quanto repetições intermináveis. Além disso, se a tarefa permitir, limite o comprimento máximo da resposta gerada para evitar saídas excessivamente verbosas. Lembre-se que, embora o modelo suporte 128k tokens de contexto, gerar uma resposta de dezenas de milhares de tokens raramente será desejável. Portanto, use limites razoáveis de tokens de saída conforme a aplicação.
3. Formatação e Sistema de Prompt: Diferente de alguns modelos, o DeepSeek R1 não requer um prompt de sistema elaborado – ele foi concebido para seguir as instruções do usuário de forma direta. Em muitos casos, iniciar com um papel (ex.: “Você é um assistente útil”) é suficiente ou nem necessário. Colocar toda a orientação na mensagem do usuário pode funcionar melhor, principalmente se você quer forçar um certo estilo de resposta. Por exemplo, ao pedir soluções matemáticas, pode-se incluir no prompt: “Responda com o raciocínio detalhado e coloque a resposta final em destaque (por exemplo, dentro de ### Resposta: ...).” Instruções claras levam a saídas formatadas de modo mais útil. A DeepSeek observou que o modelo, às vezes, sob certos formatos de pergunta, poderia tentar ocultar a cadeia de pensamento (usando tags internas <think>). Para evitar isso, é benéfico deixar claro que se espera um passo a passo na resposta, garantindo transparência no processo de solução.
4. Avaliação e Verificação de Respostas: Apesar de sua alta capacidade, o DeepSeek R1 não está livre de cometer erros ou “alucinar” fatos equivocados – especialmente em consultas muito específicas fora do domínio de conhecimento ou que envolvem dados atualizados após seu treinamento. Portanto, para usos críticos, adote a prática de verificar a exatidão das respostas. Em cenários matemáticos ou de lógica, uma dica é pedir que o modelo forneça a resposta e, em seguida, uma verificação independente. O R1 tem habilidade de autoverificação, então você pode explicitamente solicitar: “Dê a resposta e depois verifique se ela está correta.” Em programação, sempre teste o código gerado antes de confiar completamente. Em contextos onde a verdade factual é importante (por exemplo, respostas sobre legislação, medicina, etc.), use fontes confiáveis para conferir se a saída do modelo confere com a realidade. Lembre-se: o modelo tem conhecimento extenso até seu cutoff de treinamento, mas não tem acesso em tempo real à internet (a menos que você integre via ferramenta externa), então dados muito recentes podem não estar inclusos.
5. Considerações de Linguagem e Cultura: O DeepSeek R1 foi otimizado principalmente para inglês e chinês, que eram os idiomas mais presentes durante seu desenvolvimento. Isso significa que, ao usá-lo em português ou outros idiomas, é recomendável ter paciência e talvez dar exemplos no próprio idioma para guiá-lo. Em português brasileiro, o modelo consegue responder bem na maior parte do tempo, porém ocasionalmente pode escorregar para inglês em trechos da resposta ou apresentar uma estrutura de frase não totalmente natural. Para mitigar isso, inclua no prompt algo como “Responda em português claro e fluente.” Caso perceba palavras fora do contexto linguístico (por exemplo, misturando idiomas), não hesite em reforçar a instrução de idioma. Com o tempo e possivelmente com fine-tuning adicional pela comunidade, a tendência é que o suporte a múltiplos idiomas seja aprimorado, mas no estado atual pode haver pequenas inconsistências linguísticas dependendo da complexidade do texto solicitado.
6. Limites Computacionais e de Infraestrutura: Tenha em mente as limitações práticas: rodar a versão completa do DeepSeek R1 exige recursos significativos (GPUs de alto desempenho, memória abundante, etc.). Se você utiliza a API, isso não é preocupação, mas se optar por self-hosting, planeje conforme o tamanho do modelo escolhido. As versões destiladas maiores (32B, 70B) ainda requerem GPUs de 40GB+ ou múltiplas GPUs menores em paralelo. Certifique-se de usar bibliotecas otimizadas (como DeepSpeed, FlashAttention, quantização int8/4) para viabilizar a inferência. E sempre monitore latência: o R1, por raciocinar mais profundamente, pode levar segundos a mais para responder em comparação com modelos mais simples. Isso é normal – ele está literalmente “pensando” mais. Contudo, para uma boa UX, avalie usar streaming de tokens para que o usuário veja a resposta sendo produzida gradualmente em vez de esperar tudo pronto.
7. Ética e Uso Responsável: Por fim, mas não menos importante, use o DeepSeek R1 de maneira responsável. Embora não haja restrições de licença, qualquer modelo de linguagem pode gerar conteúdo indesejado se solicitado – desde código malicioso até desinformação. Coloque salvaguardas no seu aplicativo: filtragem de entradas inadequadas, revisão humana em saídas sensíveis e comunicação clara aos usuários de que é uma IA gerando as respostas (evitando confiança cega). O R1 foi alinhado para ser útil e inofensivo em geral, mas a responsabilidade pelo uso correto é de quem o implementa. Em cenários onde a decisão da IA possa causar impacto significativo (saúde, financeiro, legal), mantenha um humano no circuito. Com boa engenharia de prompts e monitoramento, o DeepSeek R1 pode ser uma ferramenta poderosa e segura a serviço dos desenvolvedores.
Conclusão
Em conclusão, o DeepSeek R1 se apresenta como um divisor de águas no panorama de modelos de linguagem para desenvolvedores. Ele combina o desempenho de IA de ponta – equiparável aos melhores sistemas proprietários – com a acessibilidade do open-source, oferecendo o melhor de dois mundos.
Sua arquitetura inovadora centrada em raciocínio, com enormes recursos paramétricos gerenciados de forma eficiente, abre novas possibilidades para resolução de problemas complexos de forma automatizada e confiável.
Ao mesmo tempo, seu licenciamento permissivo e a forte ênfase na comunidade significam que essa tecnologia está nas mãos de todos, não apenas de grandes corporações.
Se você é desenvolvedor ou líder técnico, vale a pena explorar o DeepSeek R1 em seus projetos.
Seja integrando via API para turbinar uma aplicação com respostas inteligentes, seja rodando localmente uma versão afinada para o seu domínio, o modelo pode agregar valor imediato em produtividade e inovação.
Considere iniciar com pequenos experimentos: talvez um bot de suporte interno que resolve dúvidas de programação usando o R1, ou uma rotina de CI/CD que utiliza o modelo para revisar automaticamente cada pull request buscando potenciais bugs.
As oportunidades são vastas, e sair na frente em adoção dessa classe de modelo pode trazer vantagem competitiva significativa.
O DeepSeek R1 marca o começo de uma nova era de IA de raciocínio aberta. À medida que mais desenvolvedores adotam e contribuem, podemos esperar melhorias contínuas e ainda mais soluções criativas impulsionadas por esse modelo.
Portanto, esta é uma chamada à ação: experimente o DeepSeek R1 você mesmo – acesse o repositório, teste a API, rode exemplos de código. Descubra em primeira mão como um modelo de linguagem avançado pode transformar a forma como desenvolvemos software, automatizamos processos e extraímos conhecimento dos dados.
A jornada para agentes e assistentes verdadeiramente inteligentes está apenas começando, e o DeepSeek R1 é uma das ferramentas que podem levá-lo ao próximo nível.


