
O DeepSeek V2 é um modelo de linguagem de IA de código aberto (open-source) que representa a nova geração de sistemas de linguagem avançados. Desenvolvido pela equipe DeepSeek AI em 2024, seu objetivo foi criar um modelo potente porém eficiente, capaz de alcançar desempenho de ponta com custo de treinamento reduzido e inferência otimizada.
Para isso, o DeepSeek V2 adota uma inovadora arquitetura do tipo Mixture-of-Experts (MoE) e melhorias no mecanismo de atenção, permitindo treinar um modelo de 236 bilhões de parâmetros de forma econômica e utilizá-lo de modo eficiente em produção.
Entre os diferenciais do DeepSeek V2 estão: uma escala massiva de parâmetros (236B no total, mas apenas ~21B ativos por token gerado) aliada a uma janela de contexto estendida de 128.000 tokens. Isso significa que o modelo pode processar entradas ou conversas extremamente longas sem perder de vista informações importantes.
Além disso, o DeepSeek V2 foi pré-treinado em um amplo corpus de dados (cerca de 8,1 trilhões de tokens) provenientes de fontes diversas, incluindo múltiplos idiomas e repositórios de código. Posteriormente, passou por afinação supervisionada e aprendizado por reforço (RLHF) para aprimorar sua capacidade de seguir instruções complexas e fornecer respostas úteis em linguagem natural, tornando-o adequado para aplicações conversacionais e assistentes virtuais.
Em resumo, o DeepSeek V2 se destaca como um modelo de IA avançado para desenvolvedores, combinando raciocínio sofisticado, geração de código precisa e até suporte multimodal em um só pacote. Nas próximas seções, exploraremos em detalhe as principais capacidades desse modelo, sua arquitetura interna, casos de uso recomendados e orientações de como integrá-lo em projetos, seja via API na nuvem ou executando localmente.
Também discutiremos boas práticas de adoção, desempenho obtido e limitações atuais, para que você possa avaliar como aproveitar o DeepSeek V2 em cenários práticos de desenvolvimento.
Capacidades Principais do DeepSeek V2
O DeepSeek V2 incorpora diversas capacidades técnicas de destaque que o tornam uma ferramenta poderosa para desenvolvedores. Abaixo resumimos suas principais características e funcionalidades:
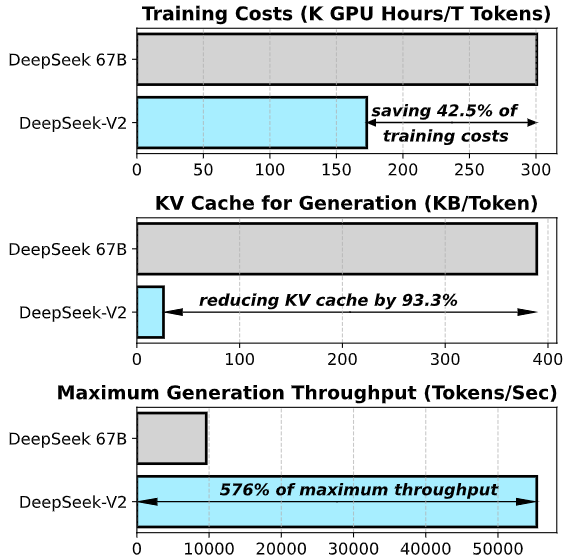
- Arquitetura Mixture-of-Experts (MoE) Eficiente: O modelo é construído com uma arquitetura Mixture-of-Experts, composta por múltiplas sub-redes especializadas (“experts”) em diferentes tipos de conteúdo ou habilidades. Graças a um mecanismo de roteamento de tokens, apenas um subconjunto desses experts é ativado para cada token de entrada, tornando o cálculo esparso e reduzindo drasticamente a carga computacional em comparação com um modelo denso tradicional. Assim, embora o modelo tenha 236B parâmetros no total, apenas ~21B são utilizados por passo, o que diminui o uso de memória e acelera a inferência sem sacrificar a qualidade. Essa arquitetura permitiu treinar um modelo maior que seu antecessor (DeepSeek 67B) com 42% menos custo de treinamento, 93% menos uso de cache de atenção (KV cache) e throughput de geração até 5,7× superior.
- Suporte a Instruções Complexas e Diálogos: Com a fase de Supervised Fine-Tuning (SFT) em dados de instruções e conversas, seguida por ajuste fino com Reforço por Feedback Humano (método RLHF), o DeepSeek V2 foi alinhado para seguir instruções de forma fiel e manter diálogos coerentes em múltiplas etapas. Sua versão de chat fine-tunada demonstra alto grau de compreensão de linguagem natural e commonsense, sendo capaz de interpretar perguntas elaboradas, realizar cadeias de raciocínio para resolver problemas passo a passo e produzir explicações detalhadas quando solicitado. Isso torna o modelo ideal para construir assistentes virtuais, bots de suporte técnico ou qualquer aplicação onde seja necessário compreender e responder a consultas complexas de usuários.
- Geração e Execução de Código: Uma das áreas onde o DeepSeek V2 mais se destaca é na compreensão e geração de código fonte. Treinado em uma grande quantidade de código de diferentes linguagens (incluindo repositórios GitHub, documentação de APIs e problemas de programação), ele consegue escrever código funcional, depurar trechos e até sugerir melhorias ou refatorações automaticamente. Em benchmarks de programação, como o HumanEval, a versão DeepSeek-V2-Chat obteve taxas de sucesso Pass@1 comparáveis a modelos de ponta, demonstrando habilidade de acertar soluções de primeira. Os desenvolvedores podem usar o modelo para gerar funções sob demanda (por exemplo, “implmentar um algoritmo de ordenação”), completar código incompleto ou explicar o que um trecho de código faz em linguagem natural. Embora o modelo não “execute” código internamente, ele é capaz de raciocinar sobre problemas de programação e produzir código executável, sendo um aliado valioso na automatização de tarefas de desenvolvimento.
- Habilidades Multimodais (Extensíveis): Embora o DeepSeek V2 em si seja um modelo focado em texto, sua arquitetura foi projetada tendo em mente extensões multimodais. A equipe lançou, por exemplo, a série DeepSeek-VL2 baseada no V2, que incorpora processamento de visão e linguagem. Graças a isso, o ecossistema DeepSeek permite, por exemplo, que uma imagem seja fornecida a um módulo visual (encoder) e o DeepSeek V2 processe informações textuais associadas a ela, habilitando casos de uso como responder perguntas sobre imagens, extrair texto de documentos escaneados (OCR) ou analisar diagramas técnicos. Em outras palavras, o design modular do DeepSeek V2 abre caminho para IA multimodal integrada – já há demonstrações do modelo descrevendo imagens e até gerando código a partir de capturas de tela de interfaces. Vale ressaltar que a versão base textual do DeepSeek V2 não recebe entradas visuais diretamente (essas capacidades requerem o modelo complementar de visão, DeepSeek-VL2). No entanto, o fato de a família DeepSeek já abranger visão e texto indica um movimento rumo a soluções unificadas, o que é promissor para desenvolvedores que futuramente queiram combinar análise de conteúdo visual e geração de respostas textuais em seus aplicativos.
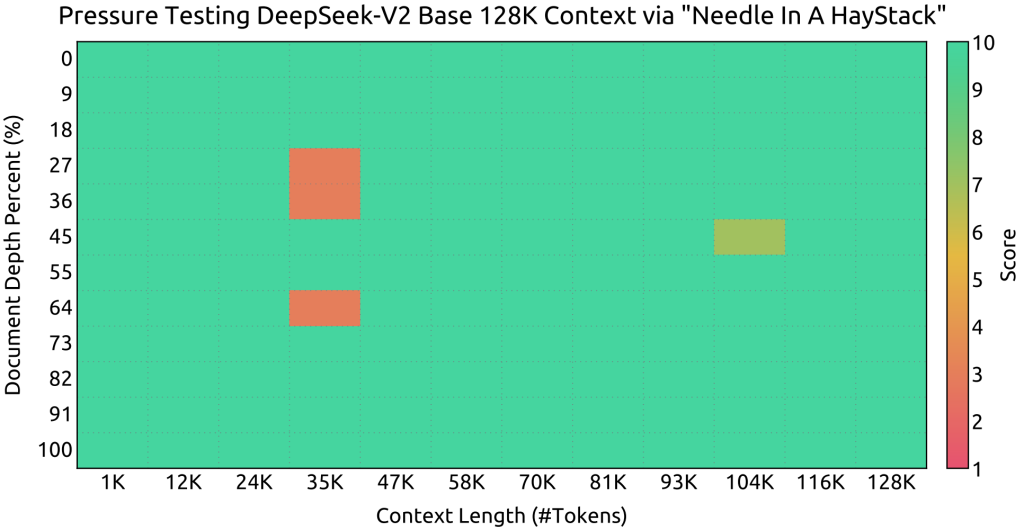
- Janela de Contexto Estendida (128K tokens): Diferentemente da maioria dos modelos que suportam algo em torno de 2K a 16K tokens, o DeepSeek V2 oferece uma janela de contexto incrivelmente ampla de até 128.000 tokens. Isso equivale a aproximadamente 100 mil palavras ou centenas de páginas de texto em uma única consulta. Com esse alcance, o modelo pode digerir documentos muito extensos, código-fonte de projetos inteiros ou longas conversas históricas de chat sem perder a referência. Para viabilizar esse contexto massivo, o DeepSeek V2 emprega otimizações de atenção especializadas – em particular a técnica Multi-Head Latent Attention (MLA), que compressa as matrizes de chave-valor da atenção em um espaço latente de baixa dimensão, reduzindo radicalmente o custo de memória do cache de atenção. Essa inovação elimina o gargalo tradicional de atender sequências muito longas, permitindo que o modelo mantenha desempenho sólido mesmo quando lida com dezenas de milhares de tokens de histórico. Em testes do tipo “Needle In A Haystack”, o DeepSeek V2 mostrou capacidade de recuperar informações corretas mesmo quando elas estavam a 100 mil tokens de distância no contexto, comprovando a eficácia do design de longo contexto. Para desenvolvedores, isso significa poder fornecer ao modelo, de uma só vez, por exemplo, toda a documentação de uma API e fazer perguntas detalhadas sobre ela, ou analisar logs extensos e extrair insights – tudo dentro de uma única chamada ao modelo.
Arquitetura e Funcionamento do Modelo
A arquitetura interna do DeepSeek V2 combina avanços de última geração para alcançar seu equilíbrio entre tamanho, desempenho e eficiência. Em sua base, ele é um modelo Transformer, porém com modificações significativas tanto nas camadas de atenção quanto nas de feed-forward, conforme descrito a seguir:
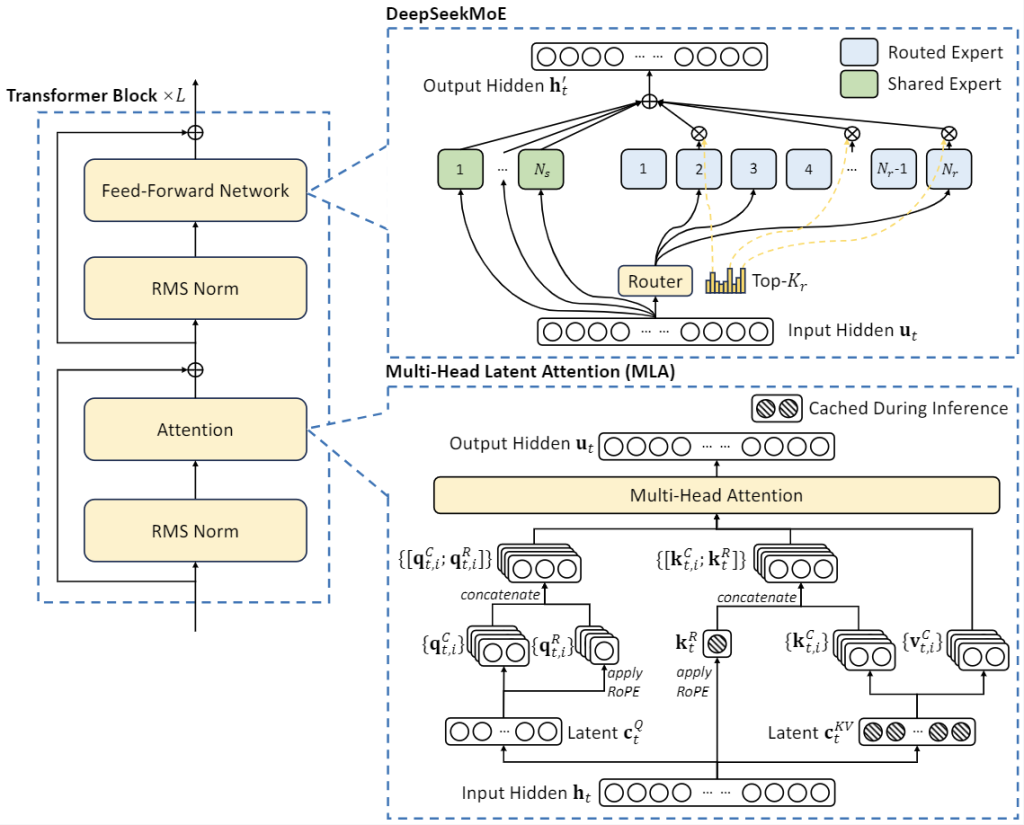
Mixture-of-Experts (DeepSeekMoE): Nas camadas de feed-forward, o DeepSeek V2 incorpora o mecanismo DeepSeekMoE, uma implementação de Mixture-of-Experts de alto desempenho. Em vez de ter um único conjunto de neurônios aprendendo todos os padrões, cada camada MoE possui vários “experts” (sub-redes especializadas) e um componente roteador que decide quais dois ou três experts são mais relevantes para cada token de entrada. Assim, se uma parte do texto envolve, por exemplo, linguagem de programação, o roteador direciona esse trecho para experts especializados em código; se outro trecho é narrativo, podem ser acionados experts focados em linguagem literária, e assim por diante. Esse design permite que o modelo aprenda especializações internas sem explodir em custo computacional, pois somente uma fração dos parâmetros é usada por vez. Além disso, o DeepSeek V2 inclui alguns experts de “conhecimento comum” compartilhados para evitar redundância e garantir que informações gerais estejam acessíveis a qualquer roteamento. Uma inovação importante foi limitar o roteamento de experts por dispositivo durante a inferência, garantindo que cada token não dispare comunicação entre muitas GPUs – isso melhora a escalabilidade em hardware distribuído. Em termos simples, a arquitetura MoE do DeepSeek V2 entrega a precisão de um modelo gigante denso, porém com custo de inferência de um modelo muito menor, graças ao uso inteligente e balanceado dos experts.
Atenção Latente Multi-Cabeças (MLA): Na parte de atenção, o DeepSeek V2 introduz o mecanismo de Multi-Head Latent Attention (MLA) para resolver um dos principais gargalos de modelos de contexto longo: o cache de atenção. Normalmente, a cada token gerado, modelos Transformer armazenam vetores “chave” e “valor” para cada uma das cabeças de atenção, e esse conjunto cresce proporcionalmente ao comprimento do contexto – consumindo enorme memória para contextos extensos. O MLA aborda isso comprimindo as chaves e valores em representações latentes de baixa dimensão, usando decomposição de baixa-rank e outras técnicas matemáticas. Em vez de manter uma cópia grande de cada token passado, o modelo mantém uma forma condensada que preserva a essência necessária para atenção, porém ocupando apenas uma fração da memória original. Na prática, o MLA elimina o inchaço do cache KV durante a inferência, viabilizando atenção eficiente mesmo em janelas de 128k tokens. Essa atenção modificada vem acompanhada de um esquema de embeddings posicionais rotatórios decoupled RoPE, ajustado para escalabilidade, garantindo que o modelo possa estender sua atenção a sequências enormes sem degradar a performance. O resultado é que o DeepSeek V2 consegue manter foco e precisão em entradas extremamente longas onde modelos convencionais simplesmente não conseguiriam lidar devido a limitações de memória ou tempo.
Treinamento em Grande Escala: O DeepSeek V2 foi pré-treinado em uma corpus massivo e diverso de 8,1T tokens, englobando vários domínios: textos da web (filtrados para qualidade), livros, artigos, fóruns, bem como um volume significativo de código-fonte em dezenas de linguagens de programação. Houve um cuidado especial em incluir conteúdo bilíngue de alta qualidade em inglês e chinês, chegando a enfatizar proporcionalmente mais dados em chinês para torná-lo altamente proficiente nesses dois idiomas principais. Essa base multilíngue e multi-domínio provê ao modelo conhecimentos gerais amplos e também noções de lógica e matemática, necessárias para responder perguntas técnicas e resolver desafios algorítmicos. Após o pretreinamento, a equipe realizou fine-tuning supervisionado com prompts instrucionais e diálogos, seguido de refinamento por aprendizagem por reforço (usando técnicas estilo PPO/GPT-4 OpenAI) para alinhamento com preferências humanas, criando versões DeepSeek-V2-Chat especializadas em conversação útil e segura. Esse processo de treinamento em estágios garantiu que o modelo não só tivesse conhecimento, mas também soubesse aplicá-lo de forma alinhada às expectativas do usuário em diferentes cenários.
Tamanhos e Variantes do Modelo: Embora o foco deste artigo seja o DeepSeek V2 principal (236B), vale notar que a família DeepSeek evoluiu para atender diferentes necessidades. Existe, por exemplo, o DeepSeek-Coder V2, uma variante especializada em programação que foi obtida ao continuar treinando um checkpoint intermediário do V2 em mais 6 trilhões de tokens de código e matemática. O resultado é um modelo ainda mais proficiente em questões de código, ampliando o suporte de ~80 linguagens de programação para 338 linguagens (praticamente qualquer linguagem que um desenvolvedor possa usar). Há também o DeepSeek-V2 Chat (nas versões SFT e RL), que é o modelo orientado a diálogo/instrução já pronto para usar em assistentes conversacionais, e um DeepSeek-V2.5 lançado posteriormente combinando os pontos fortes do modelo de chat com o de código. Todas essas variantes compartilham a arquitetura base do V2, diferenciando-se pelos dados de ajuste fino e foco de uso. Para adoção prática, é importante escolher a variante que melhor se adequa ao seu caso de uso – por exemplo, usar o DeepSeek-V2-Chat RL para um chatbot geral, ou o DeepSeek-Coder para uma ferramenta de desenvolvimento focada em código. Em qualquer caso, a base tecnológica permanece a mesma, oferecendo janelas de 128K tokens, alta qualidade de geração e possibilidade de operação local (dado o hardware necessário).
Em suma, o DeepSeek V2 representa um conjunto impressionante de escolhas arquiteturais inovadoras – MoE para escala eficiente, MLA para atenção otimizada e treinamento massivo multi-domínio – que o posicionam como um dos modelos abertos mais avançados disponíveis. Não à toa, mesmo ativando apenas 21B parâmetros por vez, ele alcança desempenho de elite entre os modelos open-source atuais, rivalizando ou superando modelos muito maiores em benchmarks padronizados de conhecimento e raciocínio.
Casos de Uso Recomendados para Desenvolvedores
Graças à sua combinação de habilidades (raciocínio em linguagem natural, entendimento de código, longo contexto, etc.), o DeepSeek V2 desbloqueia inúmeras aplicações no desenvolvimento de software e além. A seguir, destacamos alguns casos de uso recomendados onde desenvolvedores podem tirar proveito das capacidades deste modelo:
- Agentes Autônomos e Assistentes Inteligentes: Com sua aptidão em entender instruções complexas, manter contexto extenso e até realizar etapas de raciocínio, o DeepSeek V2 é uma base ideal para agentes de IA autônomos. Por exemplo, pode-se integrá-lo como o “cérebro” de um agente que recebe objetivos de alto nível e executa tarefas subjacentes (buscando informações, chamando APIs, gerando código) para alcançar esses objetivos. Em um cenário de DevOps, um agente com DeepSeek V2 poderia analisar logs volumosos em busca de anomalias e, em seguida, recomendar ações corretivas – tudo dentro de um único processo contínuo, graças à janela de 128K tokens que comporta logs completos. De forma semelhante, assistentes virtuais de TI ou bots de suporte técnico podem usar o modelo para solucionar problemas: o usuário descreve sintomas detalhados, o modelo faz perguntas de esclarecimento e sugere soluções passo a passo. A capacidade do DeepSeek V2 de manter conversas longas e contexto técnico permite que esses agentes funcionem sem perder informações importantes conforme a interação se aprofunda.
- Geração de Código e Par Programação IA: Um uso imediato e valioso do DeepSeek V2 é como auxiliar de programação. Desenvolvedores podem integrá-lo em seus IDEs (por exemplo, via plugins no VS Code, JetBrains, etc.) para obter completação de código inteligente, sugestões de implementação e explicações de trechos em tempo real. Imagine digitar a assinatura de uma função e o modelo sugerir automaticamente o corpo completo dela, ou marcar um bloco de código legado e pedir ao modelo uma explicação em português sobre o que ele faz. Isso é viável com o DeepSeek V2, inclusive rodando localmente dentro do ambiente de desenvolvimento – o que significa que o código fonte confidencial da sua empresa não precisa ser enviado a nenhum serviço externo para receber sugestões de IA. Como o modelo tem conhecimento de inúmeras bibliotecas e padrões de projeto, ele pode agilizar tarefas comuns: gerar código boilerplate, escrever testes unitários para uma função existente, ou até traduzir código (ex: transformar um script Python em JavaScript) mantendo a funcionalidade. Em modo conversacional (usando a variante Chat), o desenvolvedor pode dialogar com o “bot programador”, pedindo orientações (“Como implementar OAuth2 no Spring Boot?”) ou ajuda para debugar um erro – colando o stack trace e recebendo possíveis causas e correções sugeridas. Esse par programador virtual acelera o desenvolvimento e reduz a carga cognitiva, permitindo que humanos se concentrem na lógica de alto nível enquanto o modelo cuida dos detalhes sintáticos e repetitivos.
- Análise de Texto Longo e Documentação: A habilidade única de lidar com entradas de até 128K tokens torna o DeepSeek V2 perfeito para análise de textos longos e volumosos. Em vez de dividir manualmente um documento grande em partes, um desenvolvedor pode fornecer, por exemplo, todo o conteúdo de um whitepaper técnico, ou a documentação completa de uma biblioteca, em uma única solicitação ao modelo. A partir daí, pode-se fazer perguntas pontuais sobre o material (como “Qual é a recomendação de uso para a função X descrita na página 50?”) e o modelo encontrará e resumirá a resposta considerando o documento inteiro em contexto. Outra aplicação é resumir logs extensos ou relatórios de diversos pages: o DeepSeek V2 consegue ler o equivalente a livros inteiros e extrair insights, sumarizações ou destaca itens específicos quando solicitado, algo impraticável para modelos com contexto limitado. Para equipes de produto, isso significa poder gerar resumos executivos de especificações longas automaticamente, ou vasculhar transcrições de reuniões à procura de decisões importantes. E no campo educacional, é possível alimentar o modelo com capítulos inteiros de um livro didático e fazer perguntas de estudo, recebendo respostas contextualizadas como se um tutor tivesse lido o material completo. Em suma, onde houver grandes quantidades de texto a compreender ou comparar, o DeepSeek V2 oferece uma vantagem significativa ao eliminar a necessidade de fragmentação e possibilitar análises holísticas de documentos longos.
- Sistemas de Recomendação e Análise de Dados: Embora os sistemas de recomendação tradicionais envolvam modelos especializados, o DeepSeek V2 pode atuar como uma ferramenta de apoio na análise de dados textuais e geração de recomendações baseadas em conteúdo. Por exemplo, imagine ter um grande conjunto de avaliações de usuários sobre um produto/serviço: o modelo pode processar todas essas avaliações (novamente aproveitando o longo contexto) e identificar temas frequentes, sentimentos predominantes e até sugerir ações para melhorar o produto com base nos feedbacks. Um desenvolvedor pode perguntar: “Quais recursos os usuários mais pedem nas avaliações?” e o modelo sintetizará as solicitações comuns. Além disso, graças ao seu treinamento em código e algoritmos, o DeepSeek V2 pode gerar esboços de lógica de recomendação – como pseudo-código ou SQL – a partir de descrições em linguagem natural do que se deseja. Por exemplo, um engenheiro poderia descrever em texto: “Quero recomendar itens similares considerando características A, B, C” e o modelo propor um algoritmo ou pipeline em pseudocódigo para implementar isso. Em empresas com muitos dados textuais (descrições de produtos, perfis de clientes, históricos de navegação), o modelo pode ser integrado para analisar essas informações não estruturadas e produzir insights ou sugestões que alimentem um sistema de recomendação maior. Assim, embora não seja um recommender system por si só, o DeepSeek V2 pode complementar tais sistemas oferecendo inteligência textual, seja extraindo conhecimento dos dados ou ajudando a prototipar componentes baseados em texto.
- Outros Cenários Avançados: A versatilidade do DeepSeek V2 abre espaço para muitos outros usos criativos. Ele pode, por exemplo, servir como núcleo de um agente de documentação automatizado – vasculhando comentários de código e arquivos README em um repositório e gerando uma documentação unificada e atualizada do projeto. Também pode auxiliar na migração de código legado: dado um código-fonte antigo e instruções de migração, gerar diffs ou sugestões para adaptar o código para um novo framework ou versão de linguagem (ex: converter código Python 2 para Python 3). Empresas podem integrá-lo em pipelines CI/CD para, antes de um merge de código, analisar automaticamente o diff em busca de possíveis bugs ou más práticas, sinalizando problemas ao desenvolvedor. Em ambientes fechados, é possível rodar o modelo quantizado para obter inferência de baixa latência offline, criando ferramentas internas que não dependem de chamadas externas e funcionam mesmo sem conexão. Em resumo, sempre que houver uma tarefa complexa envolvendo compreensão de linguagem natural, síntese de informação ou geração de código/texto sob medida, o DeepSeek V2 pode ser considerado como um componente inteligente para automatizar ou potencializar a solução.
Demonstrações e Exemplos de Uso
Para ilustrar como interagir com o DeepSeek V2 na prática, vamos mostrar alguns exemplos de uso tanto via programação (biblioteca Transformers do Hugging Face) quanto via API. Esses trechos de código demonstram como desenvolvedores podem integrar o modelo em suas aplicações:
Exemplo 1: Uso via Hugging Face Transformers (Localmente)
O modelo DeepSeek V2 (e suas variantes) está disponível no Hugging Face Hub, permitindo carregá-lo em poucas linhas de código Python. No exemplo abaixo, mostramos como carregar o modelo de chat ajustado (DeepSeek-V2-Chat) e gerar uma resposta a partir de um prompt simples. Note: Devido ao tamanho do modelo, é necessário hardware de ponta (GPUs de alta memória) ou usar quantização para executá-lo localmente.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "deepseek-ai/DeepSeek-V2-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="sequential", # distribuição sequencial entre GPUs
torch_dtype=torch.bfloat16
)
# Exemplo de prompt (em português)
prompt = "Explique o algoritmo de QuickSort e forneça um exemplo de código em Python:"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=150, do_sample=False)
resposta = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(resposta)
No código acima, utilizamos device_map="sequential" para distribuir automaticamente os pesos do modelo entre várias GPUs sequencialmente (uma necessidade para modelos dessa escala). Também definimos torch_dtype=torch.bfloat16 para economizar memória usando half-precision (bfloat16). O prompt fornecido pede uma explicação do algoritmo QuickSort com exemplo em Python – o modelo, então, gerará uma resposta em português com a explicação e possivelmente um trecho de código Python ilustrativo. Esse exemplo demonstra a integração básica; em aplicações reais, você pode iterar com o modelo em modo chat (mantendo um histórico de mensagens) ou ajustar parâmetros de geração (como temperatura, top_p, etc.) conforme o caso.
Exemplo 2: Uso via API Cloud (DeepSeek Platform)
Para quem não dispõe do hardware necessário ou prefere uma solução gerenciada, o DeepSeek V2 também pode ser acessado através de uma API na nuvem fornecida pela plataforma DeepSeek. Essa API é compatível com o padrão da OpenAI, o que significa que você pode utilizá-la de forma semelhante à API do ChatGPT. Por exemplo, via HTTP com JSON:
POST https://api.deepseek.com/v1/chat/completions
Headers: {
"Authorization": "Bearer SEU_TOKEN_DE_API",
"Content-Type": "application/json"
}
Body:
{
"model": "deepseek-v2-chat",
"messages": [
{"role": "system", "content": "Você é um assistente de programação útil."},
{"role": "user", "content": "Escreva uma função que calcule o fatorial de um número inteiro."}
]
}
A resposta da API virá em formato JSON, contendo a mensagem do assistente gerada pelo DeepSeek V2. A vantagem da API é que não é preciso se preocupar com infraestrutura ou otimizações de execução – basta chamar e receber o resultado. A DeepSeek AI oferece um certo volume de tokens gratuito no cadastro e depois um modelo de cobrança pay-as-you-go, geralmente com custo por token inferior a soluções equivalentes. Isso possibilita testar e usar o modelo em escala de produção sem investir em GPUs locais. Lembre-se apenas de incluir seu token de API e de seguir as políticas de uso da plataforma.
Os dois métodos acima mostram que há flexibilidade na utilização do DeepSeek V2: você pode incorporá-lo diretamente em aplicações locais para maior controle e privacidade, ou optar pela comodidade da API em nuvem para começar rapidamente e escalar conforme necessário.
Disponibilidade e Formas de Acesso (API vs Local)
Resumindo as opções de uso do DeepSeek V2, temos dois caminhos principais para os desenvolvedores:
- API em Nuvem: A DeepSeek AI disponibiliza o modelo através de uma plataforma online com API compatível com o protocolo da OpenAI. Ao se registrar, os usuários ganham acesso a uma chave de API e um volume de testes gratuito (milhões de tokens grátis), podendo depois continuar no modelo pago conforme uso. A API suporta tanto completions de texto quanto conversas estilo chat, dependendo do endpoint escolhido, e permite selecionar entre a versão base ou de chat do modelo. Essa opção é ideal para quem quer começar imediatamente a usar o DeepSeek V2 em um projeto (por exemplo, integrar a uma aplicação web ou bot) sem ter que baixar modelos pesados ou gerenciar servidores. A desvantagem é que envolve latência de rede e dependência do serviço externo, mas em contrapartida a equipe da plataforma cuida das otimizações de desempenho e atualizações do modelo.
- Execução Local / Self-Hosted: Por ser um projeto open-source, o DeepSeek V2 tem seus pesos e código disponíveis publicamente (sob licenças permissivas como MIT e uma licença de modelo que permite uso comercial). Isso significa que desenvolvedores podem baixar o modelo e executá-lo em seus próprios servidores ou máquinas, garantindo controle total sobre os dados e possivelmente menor custo a longo prazo. No entanto, é preciso atentar para os requisitos de hardware: a execução em precisão BF16 dos 236B parâmetros demanda em torno de 8 GPUs de 80GB cada (ou equivalente) para rodar com desempenho adequado. Configurações menores podem usar técnicas como quantização (4-bit, 8-bit) para reduzir memória, à custa de alguma perda de qualidade. Há também soluções de inferência otimizadas, como usar o framework vLLM com suporte específico para o DeepSeek V2 – o qual permite manejar a enorme janela de contexto de forma mais eficiente. A própria equipe recomenda utilizar o vLLM para melhor throughput em contexto longo, tendo liberado um patch para compatibilidade. Portanto, rodar localmente é viável principalmente para organizações ou indivíduos com acesso a GPUs de ponta (A100, H100, etc.) ou que façam deploy em núvem privada com tais recursos. Uma vez configurado, o modelo local pode ser integrado em pipelines internos, oferecendo respostas rápidas (baixa latência) e garantindo privacidade, já que os dados não saem do ambiente controlado pelo desenvolvedor.
Em muitos cenários corporativos, uma abordagem híbrida pode ser utilizada: por exemplo, começar consumindo a API em nuvem para prototipagem e, conforme a aplicação cresce, migrar para uma solução self-hosted do DeepSeek V2 para reduzir custos por volume de chamadas. A comunidade em torno do modelo também costuma disponibilizar tutorials, scripts e fóruns de suporte (no Discord do projeto, GitHub, etc.), o que facilita a adoção tanto via API quanto local. Em suma, o acesso aberto ao DeepSeek V2 garante que você possa escolhê-lo como base de IA generativa no seu projeto da forma que melhor se adequar às suas necessidades e recursos.
Boas Práticas de Adoção do DeepSeek V2
Ao integrar o DeepSeek V2 em suas aplicações, vale seguir algumas boas práticas para obter os melhores resultados e evitar problemas comuns:
- Escolha da Variante Adequada: Como mencionado, o DeepSeek V2 possui variantes especializadas (base, chat SFT, chat RL, coder, etc.). Identifique qual versão se alinha ao seu caso de uso. Por exemplo, para um chatbot que conversa com usuários, prefira a variante Chat RL (alinhada e politicamente filtrada para interações humanas); para uma ferramenta interna de desenvolvimento focada em código, considere usar a variante DeepSeek-Coder V2, que oferece habilidades aprimoradas em programação com suporte a centenas de linguagens. Usar o modelo certo aumentará a qualidade das respostas no domínio desejado.
- Gerenciamento de Contexto Extenso: Embora o modelo suporte 128K tokens, isso não significa que sempre devemos fornecer entradas tão grandes. Lembre-se de que entradas muito extensas podem aumentar o tempo de inferência e, dependendo da infraestrutura, até esgotar memória. Use o contexto longo quando realmente necessário – por exemplo, ao passar todo um documento – mas caso só partes sejam relevantes, você pode extrair ou resumir previamente conteúdo irrelevante. Ferramentas de retrieval (busca de trechos) podem ser combinadas: você busca os parágrafos mais pertinentes de um texto grande e alimenta apenas esses ao modelo, para eficiência. Se optar por usar o contexto máximo, considere as soluções otimizadas (como vLLM) para lidar com latências e memórias, ou seja paciente com tempos de resposta maiores. Teste o desempenho com diferentes comprimentos de entrada para encontrar um equilíbrio aceitável.
- Estruturação de Prompts e Instruções: Por ser um modelo de instrução, o DeepSeek V2 tende a se sair melhor quando os prompts são claros e bem estruturados. Especifique exatamente o que deseja, forneça contexto suficiente (lembrando que você tem espaço de sobra no prompt) e, se a tarefa for complexa, divida-a em etapas ou peça um passo a passo. Por exemplo, em vez de “Analise meu código”, um prompt mais efetivo seria: “Você é um assistente de programação. O código a seguir apresenta um bug de NullPointerException. Explique a causa provável e sugira uma correção. Código: <CODE>…</CODE>”. Também é útil usar mensagens de sistema para definir o comportamento desejado (como no exemplo da API definindo o papel do assistente). Prompts de sistema podem orientar o tom (formal, conciso, etc.) e limites (por exemplo, “Se não souber a resposta, responda que vai pesquisar mais.”). Aproveite que o modelo foi treinado com RLHF – ele normalmente seguirá instruções literais como “responda em formato de lista” ou “forneça apenas o código-fonte sem explicações adicionais”.
- Verificação e Pós-Processamento das Respostas: Assim como qualquer modelo de linguagem, o DeepSeek V2 pode ocasionalmente produzir informações imprecisas ou “alucinações” – isto é, afirmações incorretas apresentadas de forma confiante. No contexto de código, embora ele possa gerar trechos executáveis, é importante testar e revisar esse código antes de utilizá-lo em produção, já que podem ocorrer erros sutis ou casos não tratados. Portanto, encare as sugestões do modelo como um rascunho inicial que ainda requer validação humana. Se a resposta envolver fatos ou dados, procure confirmá-los (o modelo não possui uma base de dados em tempo real; seu conhecimento é até o fim do conjunto de treinamento). Em cenários críticos, uma prática é pedir ao modelo referências ou justificativas para suas respostas, forçando-o a revelar a linha de raciocínio – isso ajuda a identificar possíveis equívocos. Integrar verificações adicionais ou regras de negócio após a saída do modelo também é recomendável para evitar agir com base em conteúdo possivelmente incorreto.
- Considerações de Segurança e Privacidade: O DeepSeek V2 Chat, tendo passado por alinhamento, geralmente se recusa a produzir conteúdo abusivo ou inseguro, mas ainda assim é importante implementar controles no lado da aplicação. Estabeleça filtros para não enviar ao modelo dados sensíveis desnecessários. Se executar localmente, lembre-se que embora os dados não saiam do seu ambiente, eles ainda passam pelo modelo, que poderia, em tese, aprender com entradas repetidas durante uma sessão (embora não persista isso). Em ambientes multi-usuário, delimite contextos por usuário para não haver vazamento de informações entre conversas. Adicionalmente, fique atento ao chamado “alignment tax“: modelos alinhados podem evitar responder certas perguntas ou adotar um tom excessivamente conservador em alguns casos. Se isso afetar seu caso de uso, uma alternativa é usar a versão base (não alinhada) e implementar seus próprios filtros customizados. Em todos os casos, monitore as respostas nos primeiros testes e ajuste os prompts ou configurações de geração (p.ex. temperatura menor para respostas mais factuais) conforme necessário para adequar o comportamento do modelo às necessidades da sua aplicação.
- Infraestrutura e Escalabilidade: Ao adotar o DeepSeek V2, planeje a infraestrutura considerando a demanda. Se for usá-lo intensivamente localmente, avalie uma solução de cluster com GPUs suficientes ou instâncias de nuvem dedicadas. Para ambientes de produção, conte com auto-scaling se usar API (por parte do provedor) ou implemente filas de requisições se self-hosted, para gerenciar picos de carga. Uma boa prática é pré-carregar o modelo na memória e mantê-lo residente para evitar tempos de inicialização a cada uso. No caso de uso local, esteja ciente de que a carga de VRAM/RAM é muito alta (centenas de GB em 16 bits), então ajuste as expectativas de quantas instâncias paralelas pode rodar. Em muitas situações, versões quantizadas ou mesmo fine-tunings menores podem atender bem – por exemplo, se você precisa apenas de recursos de código, rodar o DeepSeek-Coder 16B é muito mais leve que o V2 completo. Aproveite a comunidade: verifique no Hugging Face ou repositórios se há checkpoints otimizados (como int8, int4) ou implementações específicas que reduzam requisitos, pois o ecossistema do modelo evolui rapidamente com contribuições.
Seguindo essas práticas, você poderá integrar o DeepSeek V2 de forma eficiente, obtendo respostas de alta qualidade enquanto mitiga riscos. A chave é entender os pontos fortes e limites do modelo – usando-o como uma ferramenta poderosa, mas sempre com supervisão e contexto apropriado.
Desempenho e Limitações
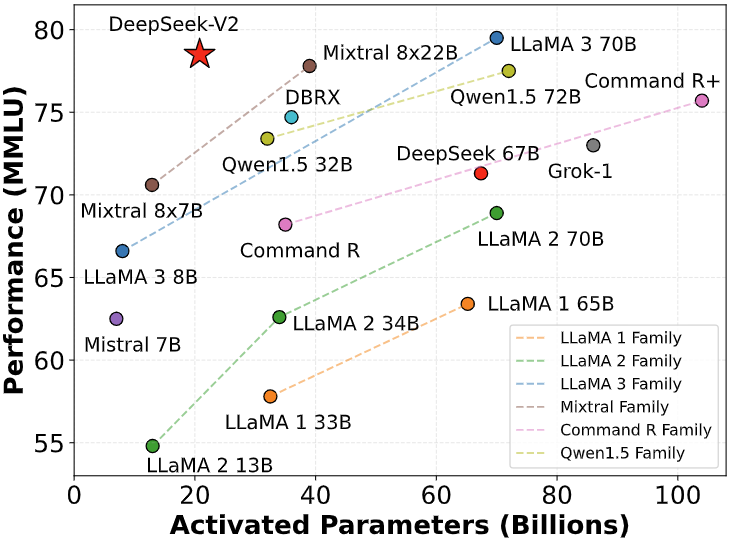
O DeepSeek V2 atingiu resultados impressionantes em diversos benchmarks, posicionando-se como um dos modelos abertos de melhor desempenho atualmente. Por exemplo, em testes de conhecimento e raciocínio como o MMLU, ele obteve acurácia equivalente ao estado da arte, ombreando com modelos fechados muito maiores. Em avaliações de código, como o HumanEval, a versão de chat RL superou modelos open-source anteriores, ficando próxima de sistemas como GPT-4 em capacidade de resolver desafios de programação.
Notavelmente, mesmo em linguagem chinesa, o DeepSeek V2 alcançou pontuações líderes (graças ao enfoque bilíngue no treinamento), superando facilmente outros modelos em tarefas do C-Eval e CMMLU. Esses resultados comprovam que a abordagem Mixture-of-Experts, aliada a treinamento massivo, pode produzir um modelo open-source de nível top-tier que compete com os melhores disponíveis.
Entretanto, como qualquer tecnologia, o DeepSeek V2 possui limitações e considerações de desempenho que devem ser levadas em conta:
Requisitos Computacionais Elevados: A principal barreira é o tamanho – com centenas de bilhões de parâmetros, executar o DeepSeek V2 demanda hardware de ponta. Mesmo com sua eficiência MoE, carregá-lo em memória é custoso: tipicamente requer múltiplas GPUs de alta memória ou instâncias especializadas. Isso significa que para muitos desenvolvedores individuais ou pequenas empresas, usar a versão completa localmente é inviável sem acesso a infra robusta. Alternativas incluem usar a API cloud ou explorar downstreams menores (como a variante Coder 16B ou futuras edições comprimidas). Em suma, há um trade-off claro entre o desempenho do modelo e o custo/complexidade de hospedá-lo.
Latência em Contextos Muito Longos: Embora suporte 128K tokens, processar contextos enormes inevitavelmente traz latência maior. A inferência em sequência tão longa pode levar vários segundos ou minutos dependendo do hardware e da quantidade de texto gerada. Para aplicativos interativos em tempo real, talvez não seja prático utilizar o contexto máximo. Nesses casos, técnicas de otimização (como as abordadas nas seções anteriores) ou limitar o contexto efetivo a algo mais manejável (p.ex. 8K ou 16K) pode ser necessário para garantir tempos de resposta aceitáveis.
Possíveis Alucinações e Erros Lógicos: Apesar de sua força em raciocínio, o modelo não é infalível. Ele pode produzir saídas incorretas, especialmente se confrontado com perguntas fora de sua base de conhecimento ou pedidos muito além dos dados que viu até 2024. Deve-se lembrar que modelos de linguagem não “entendem” no sentido humano, eles predizem saídas prováveis. Assim, podem argumentar de forma convincente mesmo estando errados em fatos ou cometer deslizes lógicos sutis. Isso requer que o usuário continue fazendo validação das respostas em usos críticos e trate o modelo como um assistente, não uma autoridade absoluta.
Domínios e Idiomas Menos Representados: O DeepSeek V2 foi pesado em inglês, chinês e linguagens de programação nos seus dados de treinamento. Se você tentar aplicá-lo em um idioma muito diferente (por ex., húngaro, sueco) ou em jargões altamente especializados que não apareçam no corpus, a performance pode cair. No contexto do português brasileiro – embora o modelo certamente tenha tido exposição ao português, ele pode não ser tão polido quanto em inglês. Isso pode se manifestar em respostas com gramática estranha ou vocabulário inconsistente em português. Ainda assim, testes informais mostram que ele consegue conversar em português fluentemente na maioria dos tópicos, apenas podendo cometer erros ocasionais ou traduzir alguns termos literalmente do inglês. Se sua aplicação for focada em um domínio específico (jurídico, médico, etc.), talvez seja benéfico fazer um fine-tuning adicional com dados naquele domínio para especializar o modelo e melhorar acurácia nos detalhes.
Multimodalidade Limitada na Base: Conforme explicado, a capacidade multimodal não está presente diretamente no modelo base (texto puro). Então, a menos que você integre o DeepSeek V2 com encoders especializados (como os do DeepSeek-VL2), não é possível enviar imagens ou áudio diretamente. Essa não chega a ser uma limitação do DeepSeek V2 em si, pois é algo comum a quase todos LLMs, mas vale ressaltar: se seu projeto exige análise direta de imagens ou voz, será preciso combinar o V2 com outras redes ou usar variantes multimodais específicas.
Comportamento Alinhado (ou Filtro Demais): A versão chat RL foi treinada para ser útil e inofensiva, o que em geral é bom. Porém, em alguns casos, esse alinhamento pode fazê-la evitar responder certos pedidos (por achar que violam políticas) ou dar respostas mais genéricas/hedgeadas. Desenvolvedores que precisem de saídas mais brutas ou não filtradas podem preferir usar a versão base (não alinhada) e implementar seus próprios controles. Além disso, o alinhamento pode introduzir uma leve perda de criatividade ou ousadia nas respostas (o chamado “imposto do alinhamento”). É um compromisso a se ter em mente: modelos altamente alinhados podem ser menos flexíveis em certos contextos, enquanto modelos não alinhados podem exigir monitoramento maior para evitar uso indevido.
Em síntese, o DeepSeek V2 oferece desempenho de ponta, mas cobra seu preço em recursos e requer uso consciente. Para muitos projetos, os benefícios – um modelo state-of-the-art aberto, com enorme contexto e forte capacidade de código – superarão as dificuldades, especialmente conforme hardware de IA se torna mais acessível. Todavia, é fundamental projetar a arquitetura da solução levando em conta essas limitações, para evitar surpresas e garantir que o uso do modelo seja sustentável e apropriado.
Conclusão
O DeepSeek V2 marca um passo significativo na evolução dos modelos de linguagem de código aberto. Ao unir escala massiva, arquitetura inovadora (MoE + MLA) e refinamento orientado a desenvolvedores, ele se estabelece como uma ferramenta valiosa para criação de aplicações de IA – desde assistentes de programação que entendem projetos inteiros, até sistemas de análise de documentos extensos e agentes autônomos capazes de planejar e executar tarefas complexas.
Tudo isso estando acessível fora dos muros de grandes corporações, possibilitando que a comunidade experimente, adapte e melhore o modelo continuamente.
Para desenvolvedores e equipes técnicas, explorar o DeepSeek V2 na prática é uma oportunidade de estar na fronteira da IA generativa. Recomendamos testar seus recursos: faça perguntas desafiadoras, peça explicações de código, alimente-o com algum documento longo e veja como ele se sai.
Aos poucos, você poderá identificar pontos fortes únicos – talvez descubra que ele resume aquele conjunto de logs de erro melhor do que qualquer outra solução, ou que escreve trechos de código em Go com surpreendente precisão. Considere integrar suas capacidades a ferramentas internas, aumentando a produtividade da sua equipe e liberando tempo para focar em criatividade e resolução de problemas de alto nível.
Claro, adotar um modelo tão avançado requer planejamento (como visto nas seções de boas práticas e limitações). Mas o investimento de tempo pode trazer um retorno significativo em inovação. Com o DeepSeek V2, você tem em mãos um modelo de última geração, aberto e em constante aprimoramento pela comunidade – um convite para experimentação e colaboração.
A própria existência de variantes como DeepSeek-Coder e DeepSeek-VL2 mostra que o ecossistema está evoluindo rápido. Portanto, manter-se atualizado e engajado (participando do Discord do projeto, contribuindo com feedback ou código) pode render benefícios tanto para você quanto para a comunidade de IA open-source.
Em conclusão, o DeepSeek V2 é um modelo transformador para desenvolvedores, combinando o que há de mais moderno em desempenho e recursos. Esperamos que este artigo técnico tenha fornecido uma visão abrangente de seu funcionamento e potencial.
Incentivamos você a explorar o DeepSeek V2 na prática, seja criando um protótipo com a API em poucas horas ou arquitetando uma solução self-hosted robusta. As possibilidades vão desde tarefas cotidianas automatizadas até projetos ambiciosos de AI que antes pareciam fora de alcance – agora viáveis graças a modelos como o DeepSeek V2. Boa experimentação e bom desenvolvimento.


