
DeepSeek V3.2 é um modelo de linguagem de grande porte (LLM) focado em raciocínio avançado e uso de agentes, desenvolvido como parte do ecossistema DeepSeek. Em essência, trata-se de um sucessor da série DeepSeek V3, projetado para oferecer alta eficiência computacional aliada a capacidade de raciocínio superior e performance “agentic” – isto é, apto a interagir com ferramentas e executar tarefas de forma autônoma.
O modelo foi desenvolvido com desenvolvedores e aplicações técnicas em mente, servindo como uma peça central para produtos que exigem compreensão de linguagem natural, geração de código e resolução de problemas complexos. Diferente de chatbots genéricos, o DeepSeek V3.2 foca em ser uma ferramenta profissional: integra-se a sistemas, APIs e pipelines de software, visando auxiliar equipes de engenharia e startups tecnológicas na construção de soluções inteligentes.
O papel do DeepSeek V3.2 dentro do ecossistema DeepSeek é o de modelo principal “generalista”, porém com ênfase em raciocínio. Ele convive com outras variantes especializadas (como o DeepSeek R1 voltado a raciocínio matemático, ou edições Speciale de alta performance), mas o V3.2 equilibra uso cotidiano e capacidade avançada.
Seu público-alvo abrange desenvolvedores de software, times de produto que desejam incorporar IA em suas aplicações, e sistemas internos que precisam de compreensão e geração de linguagem em nível elevado.
Os objetivos principais ao lançar a versão 3.2 incluíram aprimorar a precisão das respostas, aumentar a eficiência para uso em produção, permitir maior controle sobre o comportamento do modelo e consolidar sua estabilidade operacional. Em suma, o DeepSeek V3.2 foi concebido para ser um “motor” de IA confiável e robusto, adequado tanto para experimentação em P&D quanto para implantação em produtos de larga escala.
Evolução técnica do DeepSeek V3.2
A versão 3.2 representa um passo de maturidade significativo em relação às iterações anteriores da família DeepSeek. Lançada oficialmente em dezembro de 2025, ela sucede a versão experimental V3.2-Exp e consolida suas inovações de forma estável. Historicamente, a linha V3 marcou a unificação de capacidades de instrução geral e raciocínio em um único modelo híbrido, enquanto versões como a R1 focaram exclusivamente em raciocínio lógico e matemático.
A atualização para 3.2 traz melhorias tangíveis em vários aspectos: estabilidade do modelo (com treinamento refinado para evitar respostas incoerentes), precisão maior em tarefas desafiadoras, melhor previsibilidade/controle sobre as saídas e ganhos de eficiência tanto no treino quanto na inferência.
Especificamente, o DeepSeek V3.2 incorporou um novo mecanismo de atenção esparsa (DSA) que reduz drasticamente a complexidade computacional sem degradar o desempenho, principalmente em entradas de contexto longo. Essa inovação endereçou um obstáculo das versões anteriores: o custo quadrático da atenção convencional.
Com o DSA, a eficiência de processamento aumentou, tornando viável lidar com sequências muito mais extensas de texto de forma rápida – um ponto crítico para uso em produção onde latência e custo importam. Além disso, o time investiu em um framework escalável de aprendizado por reforço durante o pós-treinamento, alavancando técnicas avançadas para aprimorar o modelo sem precisar alterá-lo arquiteturalmente.
Esse processo de pós-treinamento, que envolve técnicas avançadas de ajuste e estratégias de otimização orientadas ao raciocínio, contribuiu para melhorias graduais na capacidade do modelo em lidar com tarefas complexas de lógica, matemática e programação. Avaliações públicas e benchmarks técnicos indicam que o DeepSeek V3.2 apresenta um nível de desempenho competitivo em diferentes cenários de uso, especialmente quando aplicado a tarefas analíticas e de desenvolvimento. Além disso, o modelo demonstra uma abordagem flexível de disponibilização, permitindo diferentes formas de adoção e experimentação, o que o torna relevante tanto para pesquisa quanto para aplicações práticas.
Outro foco da versão 3.2 foi a confiabilidade e controle necessários para uso em produção. Enquanto modelos experimentais priorizam alcançar métricas elevadas em benchmarks, o V3.2 foi projetado pensando em estabilidade em ambiente real: suas respostas foram calibradas para serem mais consistentes e formatadas, há mecanismos para evitar mudanças de idioma ou estilo inesperadas, e o modelo suporta modos distintos (com ou sem “pensamento” explícito) conforme a necessidade da aplicação.
A equipe adotou melhorias no algoritmo de reinforcement learning (GRPO, uma variação do PPO) para torná-lo mais estável e eficiente, incorporando ideias recentes da literatura. Com isso, o treinamento por reforço do V3.2 ganhou robustez, reduzindo a variabilidade indesejada nas respostas e evitando sobreajustes, fatores que contribuem para uma experiência mais previsível em uso contínuo. Em resumo, o DeepSeek V3.2 representa a maturidade do modelo DeepSeek: ele refina as inovações testadas no V3.1 e V3.2-Exp, entrega melhorias palpáveis em qualidade e desempenho, e se apresenta pronto para uso em produção, seja via API na nuvem ou integração em soluções customizadas.
Arquitetura e fundamentos do modelo
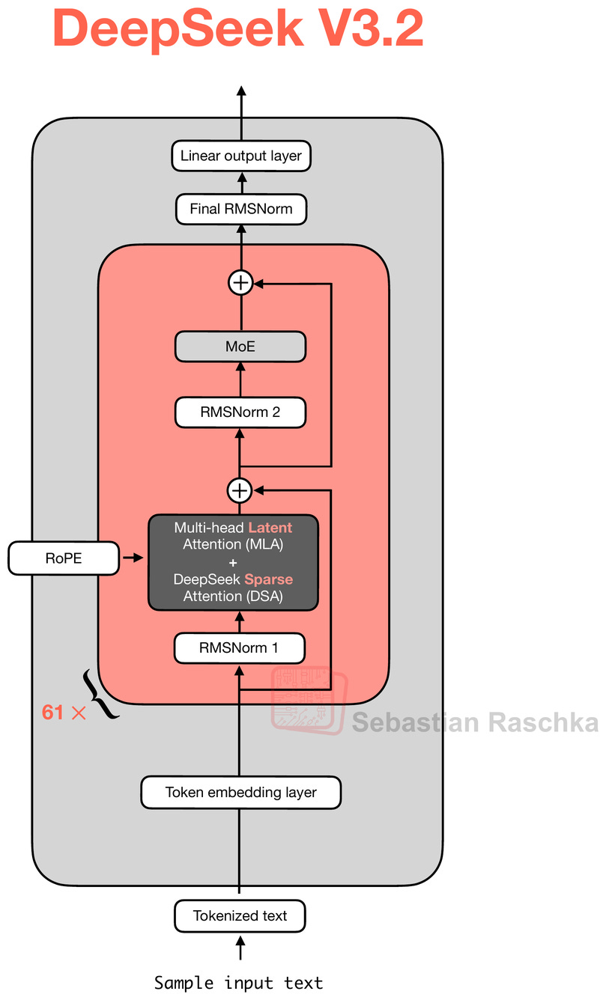
A arquitetura do DeepSeek V3.2 baseia-se no núcleo Transformer, porém com modificações e extensões projetadas para otimizar memória e desempenho. Um dos pilares é o uso de Mixture-of-Experts (MoE) – ou mistura de especialistas – dentro de cada bloco de rede. Isso significa que, em vez de um único feed-forward network por camada, o modelo possui múltiplos sub-modelos (“especialistas”) treinados, e um mecanismo de roteamento aprende a ativar dinamicamente os mais relevantes para cada token de entrada.
Esse recurso aumenta enormemente a quantidade de parâmetros efetivos (cada especialista aprendendo diferentes aspectos), sem linearmente elevar o custo de inferência, pois somente um subconjunto de especialistas é ativado por vez. Paralelamente, o DeepSeek V3.2 emprega a técnica de Multi-Head Latent Attention (MLA), introduzida no DeepSeek V2, que compressa os tensores de chave/valor da atenção em um espaço de dimensão reduzida antes de armazená-los no cache de contexto. Em termos práticos, o MLA atua como uma forma de economizar memória: ao comprimir as representações internas de atenção, o modelo consegue manter um histórico longo de conversação ou documentos sem explodir os requisitos de memória, já que as chaves/valores são salvas em forma comprimida e reexpandida apenas quando necessário durante a inferência.
A grande novidade arquitetural do V3.2 é o DeepSeek Sparse Attention (DSA). Trata-se de um mecanismo de atenção esparsa de grãos finos, composto por dois componentes principais: um indexador rápido (lightning indexer) e um seletor de tokens relevantes. A ideia central do DSA é permitir que cada token de consulta (durante a atenção) considere apenas uma fração dos tokens anteriores, em vez de todos, sem perder de vista os elementos importantes do contexto. O indexador calcula, para cada token atual, pontuações de similaridade em relação a tokens passados – utilizando representações latentes comprimidas via MLA – para estimar quão relevante cada token anterior é para a predição atual.
Em seguida, o seletor de tokens escolhe os Top-K tokens mais relevantes (por exemplo, os 2.048 tokens com maiores pontuações) e gera uma máscara de atenção esparsa que permite ao token atual “enxergar” apenas esses tokens selecionados. Dessa forma, a atenção deixa de ser quadrática em relação ao comprimento da sequência e passa a ser aproximadamente linear no número de tokens considerados relevantes (K). A figura acima ilustra esse fluxo: em vez de usar uma janela fixa ou toda a sequência passada, o DSA aprende um padrão ótimo de quais posições passadas atender, mascarando as demais.
Importante destacar que o padrão não é aleatório – o modelo aprende quais tipos de informação manter ou descartar – mas o resultado é que cada token “presta atenção” apenas ao subconjunto de contexto útil, reduzindo drasticamente a carga computacional. Em consequência, o DeepSeek V3.2 consegue lidar com contextos extremamente longos (na ordem de dezenas de milhares de tokens ou mais) de forma eficiente, sendo especificamente otimizado para cenários de contexto longo.
Do ponto de vista de fundamentos de treinamento e otimização, o DeepSeek V3.2 seguiu uma trajetória peculiar. Ele se baseou inicialmente em um modelo pré-treinado poderoso (DeepSeek V3.1-Terminus) e então passou por fases intensivas de treinamento adicional, tanto supervisionado quanto por reforço, para incorporar suas novas capacidades.
Uma dessas fases envolveu aprendizado por reforço com recompensas verificáveis (RLVR) – uma técnica já explorada no – DeepSeek R1 ombinada com novos métodos de self-verification (autoverificação) e self-refinement (auto-refinamento) inspirados por pesquisas recentes. Em resumo, o modelo foi treinado não apenas para prever a próxima palavra, mas para elaborar cadeias de raciocínio e conferir a correção de suas respostas usando critérios automatizados.
Por exemplo, em domínios como matemática e programação, ele recebeu feedback de “verificadores” (scripts ou modelos auxiliares) que conferiam se a resposta estava correta ou se um código compilava corretamente. Já para tarefas gerais onde não há uma verificação programática direta, o treinamento incluiu um modelo de recompensa gerativo – essencialmente outro LLM que avalia a qualidade da resposta do DeepSeek V3.2 de acordo com rubricas pré-definidas.
Essa mescla de estratégias elevou a compreensão semântica e capacidade de raciocínio do modelo, pois ele aprendeu a seguir instruções complexas e a justificar internamente suas respostas antes de apresentá-las. Assim, o DeepSeek V3.2 demonstra forte habilidade de compreensão contextual (inclusive em contextos muito extensos) e raciocínio de múltiplas etapas, fruto tanto de sua arquitetura otimizada quanto do rigor de seu treinamento de alinhamento.
Principais capacidades para desenvolvedores
O DeepSeek V3.2 foi concebido para oferecer um conjunto de capacidades particularmente úteis a desenvolvedores e equipes técnicas em diversos cenários. A seguir, destacamos as principais:
Geração de código
O modelo se destaca na síntese e compreensão de código fonte, atuando efetivamente como um assistente de programação. Treinado com um volume substancial de dados de programação e com reforço em tarefas de código (por exemplo, verificando se um trecho de código está correto), o DeepSeek V3.2 pode sugerir implementações, completar funções, identificar bugs e até gerar trechos inteiros de código em diversas linguagens a partir de descrições em linguagem natural.
Em benchmarks de programação competitiva e desafios de código, o V3.2 atingiu nível de desempenho muito alto, comparável a especialistas humanos, graças à combinação de raciocínio lógico e conhecimento de sintaxe. Para o desenvolvedor, isso significa que a ferramenta pode ser usada como um “par” de programação virtual, auxiliando na escrita de código ou explicando trechos complexos de forma confiável.
Compreensão de instruções complexas
Diferentemente de modelos que apenas seguem comandos simples, o DeepSeek V3.2 foi treinado em instruções compostas e cenários complexos, incluindo aqueles envolvendo múltiplas etapas, ambiguidade ou necessidade de planejamento. A equipe da DeepSeek gerou mais de 85 mil prompts complexos cobrindo 1.800+ diferentes ambientes de tarefas justamente para ensinar o modelo a lidar com instruções intricadas em contexto de uso de ferramentas. Como resultado, ele apresenta forte capacidade de decompor problemas: consegue entender perguntas do tipo “Primeiro faça X, depois obtenha Y e então determine Z”, planejando uma sequência de passos internamente.
Essa aptidão é particularmente útil para desenvolvedores ao criar agentes automáticos ou fluxos de trabalho: o modelo entende a intenção do usuário mesmo em pedidos longos ou multifásicos e produz respostas estruturadas passo a passo, se necessário. Por exemplo, pode-se perguntar: “Analise este conjunto de requisitos, gere um plano de implementação e escreva a função correspondente”, e o DeepSeek V3.2 irá internamente racionalizar cada sub-tarefa, entregando um resultado coerente que segue todas as partes da instrução.
Resolução de problemas técnicos e lógicos
O DeepSeek V3.2 foi desenvolvido com foco em tarefas que envolvem raciocínio estruturado, lógica e análise matemática. De acordo com descrições técnicas públicas, o modelo é capaz de lidar com problemas que exigem múltiplas etapas de inferência, produzir explicações intermediárias e organizar soluções de forma progressiva. Em avaliações e experimentos técnicos amplamente utilizados na área de inteligência artificial, esse tipo de abordagem é aplicado para analisar desempenho em cenários complexos, como resolução de problemas matemáticos e desafios de programação. Esses resultados indicam que o modelo pode ser utilizado em contextos que demandam análise cuidadosa e raciocínio passo a passo, sem que isso represente uma garantia de desempenho específico em competições ou aplicações formais.
Para desenvolvedores, isso se traduz em uma ferramenta capaz de enfrentar desafios como debugging de algoritmos, análise de complexidade, verificação de provas lógicas ou dedução de resultados a partir de dados. Por exemplo, ele pode auxiliar na identificação da causa raiz de um erro examinando descrições e raciocinando sobre logs (algo que abordaremos adiante), ou mesmo ajudar na solução de quebra-cabeças lógicos e problemas de engenharia. A habilidade de “pensar” em voz alta (quando ativada em modo de pensamento) permite que o modelo exponha seu processo de resolução, o que dá transparência e ajuda o desenvolvedor a entender a linha de raciocínio seguida.
Processamento de texto longo
Uma das capacidades mais práticas do DeepSeek V3.2 é lidar com entradas de texto muito longas de forma eficiente e contextual. Graças ao mecanismo de atenção esparsa DSA e otimizações de memória como o MLA, o modelo pode aceitar e processar documentos extensos, logs volumosos ou múltiplos arquivos concatenados sem perder de vista detalhes importantes. Isso é extremamente valioso para casos em que o contexto relevante não cabe em janelas curtas – por exemplo, analisar um log de sistema de milhares de linhas para encontrar anomalias, ou resumir um extenso documento técnico.
O modelo foi explicitamente otimizado para cenários de contexto longo, conseguindo identificar e lembrar pontos cruciais mesmo em entradas massivas. Para um desenvolvedor, isso significa poder alimentar o modelo com toda a documentação de uma API e perguntar algo específico, ou submeter todos os registros de erro de um dia inteiro e obter uma análise dos principais problemas, tudo em uma única interação. O DeepSeek V3.2 mantém a coerência no acompanhamento de tópicos ao longo do texto longo e consegue referenciar informações distantes no contexto quando elabora a resposta.
Uso em pipelines automatizados e agentes
Por ter sido “treinado para agentes”, o DeepSeek V3.2 é especialmente adequado a fazer parte de pipelines automatizados de software. Ele consegue não só responder, mas tomar ações estruturadas quando integrado a um loop agente-ferramenta. Por exemplo, em um pipeline de suporte, o modelo pode receber uma consulta técnica, “pensar” sobre ela gerando um plano, realizar chamadas de ferramenta (como pesquisas em base de dados ou execução de código de teste) e então retornar a resposta final embasada. Essa capacidade de integrar pensamento e execução o destaca: o modelo suporta dois modos – com “pensamento” (onde ele explicita passos e possivelmente aciona ferramentas) e sem pensamento (respostas diretas) – podendo alternar conforme o cenário.
Em automação de pipelines DevOps, por exemplo, o DeepSeek V3.2 poderia receber um alerta de monitoramento, consultar logs (como uma ferramenta), diagnosticar o problema e reportar ações, tudo guiado por sua lógica interna treinada. Desenvolvedores podem aproveitar essa versatilidade para construir assistentes automatizados que executam tarefas complexas de forma autônoma, usando o LLM como cérebro do sistema. Notadamente, o DeepSeek V3.2 foi o primeiro modelo da plataforma a integrar o raciocínio diretamente ao uso de ferramentas, o que amplia consideravelmente os tipos de tarefas que podem ser automatizadas com segurança e eficácia.
Casos de uso técnicos voltados a desenvolvedores
Considerando as capacidades acima, podemos imaginar diversos casos de uso do DeepSeek V3.2 em contexto de desenvolvimento de software e operações técnicas:
Assistente de programação e code review
Equipes de desenvolvimento podem incorporar o V3.2 como um assistente nos IDEs ou plataformas de versionamento. Por exemplo, ao escrever código, o desenvolvedor pode pedir: “Gerar a função de validação de CPF em Python” e o modelo produzirá o código correspondente, possivelmente explicando a solução.
Em revisão de código, pode resumir pull requests, sugerir melhorias ou identificar bugs potenciais. Devido ao seu forte entendimento de contexto e requisitos, o modelo pode analisar não apenas um trecho isolado, mas um projeto inteiro (dado que suporta grandes contextos) para, por exemplo, gerar documentação de API ou detectar chamadas de função inconsistentes. Isso acelera o ciclo de desenvolvimento, atuando como um pair programmer virtual e incansável.
Análise de logs e erros de sistema
Em operações (DevOps/SRE), o DeepSeek V3.2 pode ser aplicado para diagnosticar problemas a partir de grandes volumes de logs. Imagine alimentar o modelo com o log de erro de uma aplicação distribuída ocorrida durante a madrugada; com sua capacidade de contexto longo e raciocínio, ele pode destacar os eventos críticos e inferir a possível causa raiz (por exemplo, detectando que antes de um crash de serviço houve uma sequência específica de eventos incomuns).
Desenvolvedores podem fazer perguntas do tipo: “Encontre padrões de falha nestes logs e sugira o componente possivelmente defeituoso”. O V3.2, ao ler milhares de linhas, conseguirá correlacionar mensagens e apontar insights que manuais demorariam horas para encontrar. Além disso, pode formatar um relatório resumindo o incidente. Esse caso de uso demonstra a vantagem do modelo processar texto massivo: tarefas de análise de logs, traces de execução ou dumps de memória que antes eram extremamente trabalhosas tornam-se automatizáveis com o auxílio da IA.
Geração de documentação técnica
A criação de documentação de software muitas vezes é negligenciada por falta de tempo. Com o DeepSeek V3.2, times podem automatizar parte desse processo. Por exemplo, pode-se fornecer ao modelo um arquivo-fonte ou especificação técnica e pedir: “Explique em linguagem natural o que este módulo faz e como usá-lo”. Devido ao treinamento em diversas instruções e sua compreensão semântica, o modelo consegue gerar documentações claras e coerentes, traduzindo código ou configurações complexas em texto explicativo para outros desenvolvedores.
Ele também pode gerar changelogs, notas de versão ou até tutoriais a partir de exemplos de uso no código. Tudo isso com a vantagem de poder incluir grandes contextos – ou seja, você pode dar ao modelo uma visão ampla do sistema (vários arquivos, configurações, etc.) e ele produzir documentação consistente que abrange todos os componentes mencionados. Claro, a documentação gerada deve ser validada por um humano, mas o ganho de produtividade é substancial.
Sistemas internos de suporte técnico
Empresas de tecnologia podem treinar ou utilizar o V3.2 para responder perguntas de suporte de nível 2 ou 3, aquelas de cunho mais técnico, para seus times internos. Imagine um chatbot para engenheiros de suporte onde perguntas como “Por que o serviço X está lento hoje?” ou “Como posso aumentar o limite de conexões do banco de dados Y?” são respondidas pelo modelo.
O DeepSeek V3.2, tendo sido alimentado com as documentações internas e histórico de incidentes (graças ao contexto longo), pode fornecer respostas detalhadas, citando possíveis causas, comandos de solução, etc., quase como um engenheiro experiente faria. Além disso, com a capacidade de usar ferramentas, ele poderia, por exemplo, consultar um banco de dados de métricas se integrado a tal função. Esse sistema de suporte interno reduz o tempo gasto por especialistas humanos em consultas repetitivas e fornece respostas imediatas aos desenvolvedores que buscam ajuda, aumentando a eficiência organizacional.
Ferramentas SaaS técnicas baseadas em IA
Startups podem construir novos produtos SaaS aproveitando o DeepSeek V3.2 como componente central. Por exemplo, uma plataforma de revisão de arquitetura pode permitir que o usuário envie sua infraestrutura como código (CloudFormation, Terraform, etc.) e o modelo analise e forneça recomendações de melhoria ou pontos fracos de segurança. Ou uma ferramenta de qualidade de código SaaS onde o modelo faz uma análise estática inteligente do repositório, encontrando cheiros de código e sugerindo refatorações com justificativas. Outro caso é um assistente de banco de dados que recebe queries SQL complexas e as otimiza ou explica.
Em todos esses cenários, o V3.2 funciona “nos bastidores”, processando entradas extensas (código, configs, queries) e retornando sugestões ou análises baseadas em seu conhecimento e raciocínio. Como o modelo foi treinado para pipelines e instruções complexas, ele se encaixa bem em fluxos de SaaS onde o usuário talvez envie uma tarefa grande e espere um resultado estruturado e útil. Vale salientar que, por não ser um modelo genérico de conversação casual, e sim focado em tarefas de desenvolvimento, o DeepSeek V3.2 tende a produzir respostas mais objetivas e técnicas – exatamente o que se espera em aplicações profissionais.
Em todos os casos acima, é fundamental notar que o modelo atua como um auxílio ao desenvolvedor, acelerando tarefas e provendo inteligência adicional. Contudo, as saídas devem ser verificadas e validadas, especialmente em ambiente de produção, dado que mesmo modelos avançados podem ocasionalmente cometer equívocos ou não possuir conhecimento atualizado sobre um tópico muito novo. Dito isso, a amplitude e profundidade das capacidades do DeepSeek V3.2 abrem espaço para uma gama muito rica de aplicações voltadas ao público técnico.
Integração via API
Uma das grandes vantagens do DeepSeek V3.2 é a facilidade de integrá-lo em aplicações através de APIs. Desenvolvedores interagem com o modelo predominantemente via chamadas de API REST fornecidas pela plataforma DeepSeek, o que permite incorporar o modelo em servidores backend, aplicativos web ou serviços em nuvem de forma relativamente simples.
Conceitualmente, o fluxo de uma chamada de API com o V3.2 segue o padrão comum a modelos de linguagem: o cliente envia uma requisição contendo a mensagem ou prompt (possivelmente estruturado em um formato de conversa, com um histórico de diálogo), e o serviço retorna a resposta gerada pelo modelo.
O DeepSeek V3.2 adota um formato de diálogo compatível com o estilo da OpenAI (roles de user e assistant), inclusive com alguns aprimoramentos no template de chat. Por exemplo, a mensagem do usuário é marcada como User, a resposta do modelo vem como Assistant, e existe um conceito de conteúdo de “pensamento” (ou reasoning content) que pode ser habilitado internamente se o modo de pensamento estiver ativo. Embora o API oficial não exija que o desenvolvedor gerencie explicitamente essas tags (isso é gerenciado pelo servidor DeepSeek quando o modo de pensamento é ligado), é útil entender que sob o capô o modelo trabalha com uma sintaxe especial para demarcar pensamentos e chamadas de ferramenta.
Para usar o modelo, o desenvolvedor geralmente obtém uma chave de API na plataforma DeepSeek e envia requisições HTTP para endpoints específicos. A estrutura típica de requisição envolve um JSON com campos como model (por exemplo "deepseek-v3.2"), messages (uma lista de mensagens, cada uma com um role e um content), e parâmetros de geração (temperatura, top_p, etc.). A resposta virá também em JSON, contendo o conteúdo gerado pelo modelo possivelmente junto com metadados. Por exemplo, um request pode ter este formato conceitual:
{
"model": "deepseek-v3.2",
"messages": [
{"role": "user", "content": "Explique o algoritmo de Dijkstra."}
],
"max_tokens": 500,
"temperature": 0.7
}
E o response esperado traria a mensagem do assistente, como:
{
"id": "...",
"object": "chat.completion",
"created": 1700000000,
"choices": [
{
"message": {
"role": "assistant",
"content": "O algoritmo de Dijkstra encontra o caminho mais curto em um grafo... (resposta detalhada) ..."
},
"finish_reason": "stop"
}
]
}
(Obs.: O exemplo acima é ilustrativo; a API real da DeepSeek pode usar nomenclaturas ligeiramente diferentes, mas o conceito é similar.)
Uma consideração importante é que o DeepSeek V3.2 introduziu um novo modo de operação chamado “Thinking Mode”, que pode ser ativado para habilitar saída com chain-of-thought (cadeia de raciocínio). Quando esse modo está ativado nas chamadas de API (por meio de um parâmetro ou endpoint específico), o modelo passa a retornar, além da resposta final, trechos de “pensamento” ou justificativas internas, muitas vezes intercalados com chamadas de ferramenta.
Esse recurso é útil para desenvolvedores que desejam maior transparência do processo ou que estão implementando agentes baseados no modelo – pois possibilita interceptar o pensamento do modelo e executar ações (ferramentas) conforme necessário. Por padrão, no entanto, o modo de pensamento pode vir desativado, e o modelo funciona como um assistente conversacional tradicional, retornando apenas a resposta final para o usuário.
Boas práticas de uso em produção incluem gerenciar cuidadosamente os parâmetros de geração e o contexto enviado. Recomenda-se ajustar a temperatura e top_p de acordo com o caso de uso: para respostas mais determinísticas e consistentes, uma temperatura baixa (p. ex. 0.2–0.5) é adequada, enquanto para respostas que podem se beneficiar de criatividade (geração de texto livre, sugestões de código alternativas) pode-se usar temperatura ~1.0 (o time do DeepSeek sugeriu temperatura 1.0, top_p 0.95 como padrão para uso geral).
Em produção, costuma-se limitar o comprimento máximo de resposta (max_tokens) para controlar custos e latência – embora o V3.2 possa gerar respostas longas, nem sempre é desejável que ele se estenda indefinidamente. Outra boa prática é utilizar mensagens de sistema (sistema ou system prompt) no início do contexto para orientar o comportamento do modelo (por exemplo, definindo o estilo de resposta ou fornecendo instruções invariantes). O modelo tende a seguir fielmente essas orientações iniciais, uma vez que foi treinado para cumprir instruções e manter consistência de formato.
Quando integrando via API, deve-se também considerar o uso de streaming de respostas (se a API suportar). O DeepSeek V3.2, por ser volumoso, pode ter um tempo de latência perceptível para respostas muito elaboradas. Com a resposta por streaming (tokens sendo enviados à medida que são gerados), a aplicação consegue começar a exibir o output parcial antes do modelo terminar toda a geração, melhorando a responsividade percebida pelo usuário final – um padrão útil em chats ou assistentes onde o usuário acompanha a resposta sendo “digitada”.
Caso a aplicação exija alta taxa de chamadas simultâneas, é importante implementar filas ou usar múltiplas chaves de API para paralelismo, respeitando limites de requisição da plataforma (p. ex., número de tokens por minuto). A escalabilidade pode ser obtida escalonando horizontalmente instâncias que chamam a API, já que a DeepSeek oferece o serviço gerenciado do modelo na nuvem; alternativamente, para organizações que necessitam controle total, a disponibilidade do modelo em open-source permite implantação em infraestrutura própria, mas aí caberá gerenciar escalabilidade via Kubernetes ou similar, instanciando múltiplos servidores de modelo conforme demanda.
Do ponto de vista de latência e custo, desenvolvedores devem estar cientes de que modelos grandes como o DeepSeek V3.2 consomem bastante recurso a cada consulta. Cada token gerado tem um custo computacional e, se usando o serviço API, um custo financeiro associado. O contexto longo é um recurso fantástico, mas enviar muitos milhares de tokens de uma só vez aumentará proporcionalmente o tempo de processamento e o custo daquela requisição. Por isso, recomenda-se enviar somente o necessário no prompt e, se possível, aproveitar técnicas de resumo ou busca interna para reduzir o texto de entrada mantendo relevância.
A versão especial V3.2-Speciale, em particular, foi mencionada como tendo performance superior porém com maior uso de tokens na geração de respostas (devido a raciocínios mais extensos). Na prática, isso significa que se você optar por usar a variante Speciale para casos muito complexos, deve esperar respostas mais longas (e ligeiramente mais lentas) e fatorar esse aumento de tokens no custo. Em contrapartida, a versão padrão V3.2 foi treinada com restrições de tokens para atingir um bom compromisso entre custo e benefício em produção – ela tende a ser mais concisa e direta, mantendo alto desempenho sem extrapolar no uso de tokens.
Assim, escolha a variante e configuração de geração de acordo com a necessidade: para uso cotidiano e escalável, V3.2 (padrão) com limites moderados de tokens é ideal; para casos que exigem exaustividade e máxima acurácia (por exemplo, resolução de um problema matemático olímpico), V3.2-Speciale pode ser usada esporadicamente, ciente do maior custo computacional.
Em termos de padronização de integração, o DeepSeek V3.2 segue convenções de mercado, então desenvolvedores acostumados com outras APIs de IA (como OpenAI, etc.) encontrarão conceitos similares. A curva de aprendizado para fazer a primeira chamada é mínima – muitas vezes reduzida a preencher um formulário de JSON adequado. A DeepSeek fornece documentação e exemplos (incluindo notebooks e SDKs em Python, provavelmente) para auxiliar na adoção.
Para produção, é importante também tratar os possíveis erros da API, como tempos de resposta excedidos ou limites atingidos: implemente retries exponenciais e degrade graciosamente a funcionalidade se o modelo não responder, para garantir robustez do seu sistema integrado. Além disso, acompanhe os logs e métricas de uso: plataformas de API normalmente fornecem logs de quantos tokens foram usados por chamada e latência média – esses dados ajudam a otimizar seu uso, por exemplo, detectando se prompts muito longos estão sendo enviados desnecessariamente.
Em resumo, a integração via API do DeepSeek V3.2 foi pensada para ser developer-friendly, permitindo que times adicionem rapidamente capacidades de linguagem avançadas aos seus produtos sem a necessidade de entender todos os detalhes internos do modelo.
Controle, segurança e previsibilidade
Ao adotar um modelo como DeepSeek V3.2 em aplicações reais, é fundamental ter mecanismos de controle e considerações de segurança, bem como entender o nível de previsibilidade de suas respostas. Felizmente, diversos aspectos do design e treinamento do V3.2 visam justamente melhorar a consistência e controlabilidade comparado a gerações anteriores.
Em termos de consistência das respostas, o modelo foi explicitamente ajustado para manter coerência de estilo e formato. Por exemplo, durante o aprendizado por reforço, foi empregada uma recompensa de consistência de linguagem – penalizando situações em que o modelo mudasse de idioma ou de registro de forma inadequada no meio da resposta. Assim, se a interação está em Português, ele tende a continuar integralmente em Português, evitando respostas bilíngues ou trechos fora de contexto.
Da mesma forma, a estrutura de resposta pode ser influenciada por instruções no prompt inicial (sistema), e o modelo se mostrou confiável em segui-las. Isso significa que desenvolvedores têm um grau razoável de controle simplesmente definindo claramente o formato desejado: por exemplo, se você pedir “responda em formato de lista numerada”, o V3.2 provavelmente obedecerá essa formatação.
A previsibilidade também vem do fato de que o modelo passou por extensivos testes internos e ajustes finos – por exemplo, removendo recompensas auxiliares que poderiam torná-lo verbose demais e ajustando penalizações para respostas muito longas. Essas decisões mitigam comportamentos extremos, fazendo o modelo tender a respostas equilibradas em tamanho e detalhamento para a maioria das consultas.
No quesito controle de comportamento, além das orientações via prompt, o DeepSeek V3.2 introduziu a possibilidade de modular certos modos de operação. Conforme citado, há um modo de “pensamento” que pode ser ativado ou desativado, permitindo controlar se o modelo deve expor seu raciocínio passo a passo ou entregar apenas a conclusão. Em cenários sensíveis – digamos, um chatbot ao usuário final – provavelmente o pensamento deve ficar oculto, tanto para não confundir o usuário quanto por segurança (os passos intermediários podem conter informação indevida se não filtrados).
Já em cenários de desenvolvimento ou depuração, habilitar o pensamento pode dar visibilidade sobre como o modelo chegou àquela resposta, o que é valioso. O modelo também possui uma nova role de mensagem chamada developer (destinada a cenários de agente de busca), que no entanto é bloqueada no uso público da API – isso foi uma decisão de design para evitar mau uso dessa role indevidamente; ela é reservada para contextos específicos controlados. Para o desenvolvedor que integra o modelo, basta saber que roles aceitas são essencialmente usuário e assistente (e possivelmente system para contexto inicial), simplificando o controle.
Sobre segurança e uso responsável, apesar de ser um modelo aberto, o DeepSeek V3.2 vem de um processo de alinhamento que incluiu filtros e verificações para evitar respostas indevidas. Durante o RLHF/RLVR, é provável que conteúdos claramente tóxicos, preconceituosos ou inseguros tenham sido penalizados. No entanto, nenhum modelo é perfeito: ainda é possível que, sob certas instruções, o modelo produza saída inadequada ou incorreta.
Assim, recomenda-se implementar camadas de segurança na aplicação. Isso pode incluir: filtros de conteúdo nas entradas (não enviar ao modelo prompts que claramente violem políticas, por exemplo, usuários tentando obter instruções perigosas), e filtros nas saídas (verificar se a resposta contém palavreado ofensivo, informações sensíveis ou conselhos potencialmente danosos antes de exibí-la ao usuário final). Ferramentas de detecção de toxicidade ou listas de termos proibidos podem ser úteis nesse contexto. Além disso, monitorar ativamente as interações é importante – por exemplo, logar prompts e respostas (anonimizando dados pessoais) para auditoria posterior, e ter um processo de revisão humana para casos-limite.
Um aspecto positivo do V3.2 é que, por ser altamente orientado a tarefas técnicas, ele tende a se manter no assunto técnico sem divagações para temas delicados, exceto se explicitamente perguntado. Isso reduz naturalmente o espaço para abusos em comparação com modelos de conversação genérica. Ainda assim, se integrado em um produto usuário-final, deve-se deixar claro aos usuários as limitações do modelo e lembrá-los de que estão interagindo com uma IA (por transparência e alinhamento com princípios éticos).
Limitações conhecidas do DeepSeek V3.2 devem ser reconhecidas e comunicadas de forma neutra. Embora seja um modelo de ponta, ele não é infalível. Uma limitação é a possibilidade de alucinações: como qualquer LLM, ele pode algumas vezes “inventar” fatos ou respostas com segurança aparente, mas que estão incorretos.
Isso pode ocorrer especialmente em domínios onde ele não foi exaustivamente treinado ou quando extrapola conhecimento. Por isso, em usos críticos (ex.: dando explicações de segurança, diagnósticos médicos, etc.), deve haver validação especializada das respostas.
Outra limitação é que, apesar do grande contexto, o modelo pode demonstrar degradação de performance se o contexto for extremamente longo e disperso – afinal, selecionar informações relevantes entre dezenas de milhares de tokens é desafiador. O DSA mitiga isso focando nos tokens relevantes, mas se a informação crucial estiver mascarada por irrelevantes, o modelo pode falhar em considerá-la.
Portanto, mesmo com contexto extenso, é boa prática estruturar bem a entrada (colocando talvez um sumário inicial no prompt, ou indicando quais partes são mais importantes). Também foi relatado no relatório técnico que a variante Speciale do V3.2, apesar de alcançar resultados impressionantes, o faz às custas de gerar mais tokens e passos de raciocínio que modelos proprietários equivalentes. Isso indica que o V3.2 às vezes pode ser verboso ou “pensar demais” para chegar à resposta, o que implica menor eficiência.
A equipe apontou que pretende trabalhar na densidade de inteligência (fazer o modelo ser mais conciso sem perder qualidade), mas no estado atual, esse é um trade-off: ou respostas muito detalhadas e longas (alta qualidade, baixa eficiência) ou respostas mais objetivas (alta eficiência, talvez ligeiramente menos desempenho máximo). A versão oficial V3.2 escolheu o equilíbrio pela eficiência, mas é algo a ter em mente ao comparar com alternativas.
Por fim, é preciso citar uma limitação de ferramentas: curiosamente, o DeepSeek V3.2-Speciale, por ter foco extremo em raciocínio puro, não suporta o recurso de chamadas de ferramenta integrado. Ou seja, se você precisa que o modelo atue como um agente que consulta APIs, bancos de dados, etc., deve usar a versão padrão V3.2 (que suporta pensamento com ferramentas) – a variante Speciale serve mais para obter soluções diretamente via raciocínio interno.
Essa decisão de design foi feita para segmentar os usos: Speciale maximiza raciocínio autônomo (ótimo para problemas de concurso, por exemplo), enquanto V3.2 normal mantém versatilidade para agentes. Conhecer essa diferença evita surpresas: um desenvolvedor poderia estranhar que a Speciale não está chamando ferramentas mesmo quando deveria – mas é porque não foi treinada para isso. Em resumo, a abordagem responsável é conhecer os limites do modelo e complementar sua integração com salvaguardas, supervisão humana quando necessário e feedback iterativo para melhoria contínua.
DeepSeek V3.2 em ambientes de produção
Decidir usar o DeepSeek V3.2 em um ambiente de produção é, antes de tudo, reconhecer quando faz sentido optar por esse modelo. Dada sua potência e características, ele é uma excelente escolha técnica quando a aplicação exige: (a) raciocínio complexo ou resposta contextualizada – por exemplo, assistentes que precisem entender contexto grande ou resolver problemas intrincados; (b) integração com fluxos de trabalho – como bots que precisam acionar outras ferramentas ou lidar com etapas múltiplas; (c) suporte a entradas/saídas longas – sistemas que trabalham com documentação extensa, códigos longos, transcrições grandes etc.; e (d) alto grau de confiabilidade nas respostas – projetos em que se busca respostas mais corretas e explicáveis, tirando proveito do extenso alinhamento do modelo.
Se sua necessidade se alinha com esses pontos, o V3.2 tende a ser uma boa escolha. Em contrapartida, se o caso de uso é muito simples (e.g., completar frases curtas ou responder a FAQs triviais) e os recursos são limitados, um modelo menor ou menos especializado poderia atender com custo menor. O DeepSeek V3.2 brilha mesmo em tarefas que “esticam” as capacidades de um LLM, onde modelos comuns tropeçariam seja pela falta de lógica, seja pela limitação de contexto ou falta de integração com processos.
Os tipos de aplicações mais adequadas a ele incluem muitas das já mencionadas: plataformas de desenvolvimento assistido (IDE inteligentes, gerenciamento de configuração, análise de código), chatbots técnicos (suporte de TI, atendimento especializado), ferramentas de análise de dados e logs, sistemas de tomada de decisão semi-autônomos em domínios de engenharia, entre outros. Por exemplo, numa empresa de software, integrá-lo no pipeline CI/CD para explicar porque um build falhou e sugerir a correção seria um uso de alto impacto.
Em produtos ao cliente final, pode habilitar funcionalidades como um help center inteligente que entende perguntas de usuários sobre configuração avançada de produto e responde adequadamente. O denominador comum dessas aplicações é a necessidade de inteligência adaptativa e profunda, mais do que apenas recuperação de respostas pré-definidas.
Ao fazer o deploy (implantação) do DeepSeek V3.2 em produção, alguns cuidados são essenciais. Primeiro, se optar por usar o serviço via API, verifique os SLAs e limites da API para dimensionar sua arquitetura. Certifique-se de que sua aplicação tenha lógica de retentativa para chamadas que eventualmente falhem ou demorem, e considere implementar circuit breakers caso o serviço fique indisponível, para não impactar todo o sistema.
Segundo, pense em cachear resultados para queries repetidas – por exemplo, se múltiplos usuários costumam perguntar a mesma coisa ao assistente, guardar a resposta gerada (talvez indexada por uma hash do prompt normalizado) pode poupar chamadas redundantes. A DeepSeek chegou a introduzir um recurso de context caching na API, o que possivelmente ajuda a reutilizar o estado de conversas de forma otimizada; vale explorar se isso se aplica ao seu caso (por exemplo, conversas contínuas podem se beneficiar desse cache para reduzir latência).
Se a escolha for hospedar o modelo on-premise (localmente), os cuidados se voltam a infraestrutura: garantir máquinas com GPUs suficientemente poderosas (ou um cluster) para rodar o modelo com performance aceitável. O DeepSeek V3.2, contendo MoE e atenção avançada, pode ser pesado – possivelmente requer múltiplas GPUs de alto VRAM se carregado em FP16, ou uso de técnicas de quantização (int8/fp8) para caber em menos memória.
A documentação indica suporte até para formato FP8, sinal de que o time pensou em eficiência de inferência. Ainda assim, montar um servidor de inferência para ele não é trivial: envolva sua equipe de MLOps para configurar bem o ambiente, preferindo bibliotecas otimizadas (Transformers, TRT, etc.). Uma vez de pé, monitore o uso de GPU, throughput e escalabilidade – pode ser necessário servir instâncias em paralelo e distribuir as consultas.
Um ponto crítico em produção é o monitoramento e ajuste contínuo. Para modelos de linguagem, isso significa monitorar tanto métricas técnicas (latência, taxas de erro, uso de memória) quanto métricas de qualidade de resposta. Considere implementar um sistema de feedback onde as respostas do modelo que geram baixa satisfação ou estão incorretas sejam sinalizadas, de modo que você possa aprimorar as instruções ou efetuar fine-tuning adicional se possível.
O DeepSeek V3.2 sendo open-source permite que, se acumular dados específicos do seu domínio (ex.: conversas de suporte da sua empresa), você faça um ajuste fino supervisionado para especializá-lo ainda mais. Todavia, lembre que isso requer recurso computacional considerável e expertise, então pode não ser viável para todos – mas fica como possibilidade para próximos passos.
Outro aspecto de monitoramento é a auditoria de segurança e compliance. Assegure-se de registrar quando o modelo fornecer respostas potencialmente problemáticas, e tenha um mecanismo de desativação de emergência (por exemplo, se for detectado que o modelo está dando conselhos perigosos devido a algum ataque adversarial do usuário, talvez tenha que suspender o serviço até aplicar um patch nas instruções).
Como parte de devops, teste periodicamente o modelo com entradas de controle (por exemplo, uma bateria de perguntas de teste cujas respostas esperadas são conhecidas). Isso serve para flagrar qualquer regressão após atualizações – por exemplo, se você atualizar para um hipotético DeepSeek V3.3 no futuro, rodar o mesmo conjunto de perguntas teste e comparar resultados garante que nada crítico se perdeu.
Em termos de próximos passos operacionais, mantenha-se atento às atualizações do ecossistema DeepSeek. Novos modelos ou versões podem ser lançados (como um possível DeepSeek V4 ou DeepSeek R2 focado em raciocínio, conforme especulações do setor).
A DeepSeek, assim como outras, pode publicar patches ou melhorias incrementais para V3.2, seja nos pesos ou nas ferramentas de implantação – acompanhe o repositório oficial e a comunidade (Discord, fóruns). Às vezes, ajustar para a versão mais recente traz melhorias de segurança e desempenho importantes.
Por fim, planeje a experiência do usuário ao incorporar o modelo. Em produção, não é só sobre a tecnologia funcionar, mas como ela interage com pessoas ou sistemas. Certifique-se de que as respostas do modelo sejam apresentadas de forma amigável e útil: se for um chatbot, formate as respostas com Markdown ou HTML conforme o caso; se for um sistema de recomendação interna, integre com a interface adequada (por exemplo, os resultados de uma análise de log pelo modelo podem ser exibidos em um dashboard com destaque nos trechos relevantes). Pequenos detalhes como esses potencializam o valor entregue pelo modelo e demonstram profissionalismo do produto final.
Considerações finais para desenvolvedores
O DeepSeek V3.2 representa uma escolha tecnicamente robusta para equipes de desenvolvimento que buscam incorporar inteligência artificial de última geração em seus projetos. Em resumo, este modelo é uma boa escolha quando se requer um alto nível de raciocínio automático, aliado à flexibilidade de integração e controle. Times que lidam com produtos ou sistemas complexos – onde perguntas não trivialmente mapeáveis a respostas prontas, ou onde o fluxo de interação varia muito – irão se beneficiar bastante das capacidades do V3.2.
Por exemplo, equipes de P&D de IA, desenvolvedores de plataformas devops, startups de analytics de dados ou segurança – todos esses perfis podem alavancar o modelo para ganhar eficiência e entregar funcionalidades antes impraticáveis. O modelo se alinha bem com times experientes que sabem explorar sua potência: desenvolvedores capazes de criar bons prompts, refinar instruções e interpretar as saídas obtêm resultados excepcionais.
Já equipes menos experientes também podem usá-lo, mas talvez não extraiam todo seu potencial sem investir em aprender as melhores práticas de prompt design e as particularidades do modelo. Em outras palavras, o DeepSeek V3.2 é como uma ferramenta de nível profissional – nas mãos certas, ele brilha; requer um certo manejo, mas recompensa com desempenho superior.
Ao longo deste artigo, vimos como o DeepSeek V3.2 funciona internamente, o que mudou em relação às versões anteriores, como desenvolvedores podem utilizá-lo e em quais cenários ele mais se destaca. Um próximo passo natural, após entender o modelo, é experimentá-lo diretamente. Recomenda-se que desenvolvedores interessados façam pequenos projetos piloto: integrem a API em um script, testem perguntas do seu domínio, avaliem as respostas.
Nada substitui a experiência prática para ganhar confiança no comportamento da IA. A partir daí, pode-se aprofundar em personalizações – por exemplo, ajustar o prompt de sistema ideal para sua aplicação, ou criar uma biblioteca de prompts reutilizáveis (prompt engineering) para casos recorrentes.
Outra sugestão de próximo passo é acompanhar o relatório técnico oficial e outros materiais disponibilizados (como notebooks de exemplo, código no HuggingFace, etc.), pois eles contêm detalhes que podem inspirar formas criativas de uso do modelo.
Por exemplo, entender a estrutura exata de entrada esperada pelo modelo (com as tags especiais) pode permitir integração mais low-level se você estiver self-hosting. Além disso, a comunidade DeepSeek parece bastante ativa – envolver-se em fóruns ou grupos pode ajudar a sanar dúvidas, trocar best practices e ficar a par de atualizações.
Em termos de evolução, se sua equipe domina o DeepSeek V3.2, o próximo passo poderia ser olhar para especializações ou complementos. A família DeepSeek inclui variações como a DeepSeek Math (especializada em matemática) e DeepSeek Coder, etc. Talvez para seu caso de uso uma dessas variações seja ainda mais adequada ou possa ser executada em conjunto. Entretanto, evite pular para variantes sem primeiro extrair o máximo do modelo principal; muitas vezes, pequenos ajustes no uso do V3.2 já atendem bem, sem precisar de um modelo separado.
Por fim, vale refletir sobre o impacto arquitetural: inserir o DeepSeek V3.2 em sua stack pode abrir novas possibilidades de produto e alterar fluxos existentes. Esteja preparado para iterar no design do sistema aproveitando a IA – por exemplo, funções que antes eram totalmente manuais podem ser semi-automatizadas com o modelo no loop; feedback dos usuários finais pode guiar melhorias de prompt ou de lógica de chamada; e métricas de sucesso (como tempo de resolução de um ticket de suporte) podem melhorar significativamente. Medir e divulgar esses ganhos ajuda a solidificar o valor da adoção dessa tecnologia perante stakeholders.
Em conclusão, o DeepSeek V3.2 é uma peça tecnológica de ponta que, quando bem compreendida e aplicada, potencializa equipes de desenvolvimento e produtos técnicos a um novo patamar de inteligência. Ele combina uma engenharia de modelo sofisticada (eficiência e escala) com um treinamento orientado a aplicações práticas (raciocínio, agentes), resultando em uma ferramenta alinhada às necessidades de desenvolvedores profissionais. Com a abordagem correta – uso consciente, controle das saídas e integração harmoniosa no sistema – o DeepSeek V3.2 tem tudo para ser um trunfo no arsenal de tecnologia de sua equipe, resolvendo problemas antes complexos de forma elegante e poderosa. Bom desenvolvimento!


