
O DeepSeek Coder é uma família de modelos de linguagem de IA especializada em programação e geração de código. Desenvolvido pela DeepSeek AI, esse modelo foi treinado do zero em um extenso conjunto de dados que combina código-fonte (cerca de 87%) e linguagem natural (13%) em inglês e chinês.
Graças a esse treinamento massivo – incluindo 2 trilhões de tokens de dados de código e texto técnico – o DeepSeek Coder adquiriu profundo entendimento de sintaxes e padrões de mais de 80 linguagens de programação. Diferentemente de modelos genéricos, ele foca em resolver problemas de codificação, oferecendo respostas precisas e contextualizadas para desenvolvedores.
Um dos grandes diferenciais do DeepSeek Coder é sua capacidade de lidar com projetos inteiros. Com uma janela de contexto de 16 mil tokens, ele consegue analisar trechos extensos de código, compreender arquivos completos e até mesmo preencher partes faltantes dentro de um código (técnica de fill-in-the-blank). Além disso, a DeepSeek AI forneceu o modelo em vários tamanhos (de ~1,3 bilhões até 33 bilhões de parâmetros) para atender a diferentes necessidades de desempenho e infraestrutura. O modelo base, chamado DeepSeek-Coder-Base, foi posteriormente refinado com 2 bilhões de tokens de dados de instruções para criar a versão DeepSeek-Coder-Instruct, voltada a seguir comandos de linguagem natural de forma alinhada.
Vale destacar que o DeepSeek Coder é disponibilizado como uma ferramenta aberta e gratuita para uso – incluindo usos comerciais – o que significa que desenvolvedores e empresas podem aproveitá-lo sem custos de licenciamento. Em resumo, trata-se de um assistente de programação de última geração, projetado para “deixar o código se escrever sozinho” e potencializar a produtividade de times de desenvolvimento.

Capacidades do Modelo
O DeepSeek Coder possui uma ampla gama de capacidades que auxiliam em diversas etapas do desenvolvimento de software. Entre as principais funções do modelo, destacam-se:
- Compreensão de múltiplas linguagens: reconhece e interpreta código-fonte em dezenas de linguagens (Python, JavaScript, C++, Java, Go, PHP, Ruby, entre outras), entendendo a sintaxe e as bibliotecas comuns de cada uma. Isso permite que ele responda a perguntas sobre trechos de código ou converta algoritmos de uma linguagem para outra com facilidade.
- Geração de código sob demanda: a partir de uma descrição em linguagem natural (por exemplo, “implemente uma função de ordenação rápida”), o modelo é capaz de escrever o código correspondente, criando funções, estruturas de dados e algoritmos completos conforme solicitado. Essa geração considera boas práticas da linguagem alvo e produz um código funcional na maioria dos casos.
- Autocompletar e preenchimento de código: pode prever a continuação de um código a partir de um contexto inicial, semelhante a um recurso de auto-complete turbinado por IA. Com seu longo contexto de 16k tokens, o DeepSeek Coder consegue sugerir os próximos trechos de um arquivo ou mesmo preencher lacunas no meio do código (infilling), o que é útil para completar funções inacabadas ou adicionar trechos omitidos.
- Depuração assistida: auxilia na identificação de erros e bugs, analisando código fornecido e apontando possíveis causas de falhas. O modelo pode sugerir correções para exceptions, problemas de lógica ou inconsistências, explicando onde o código pode estar falhando. Isso agiliza o processo de debugging, servindo como um “par” que ajuda a encontrar soluções.
- Explicação de código e documentação: dada uma função ou classe, o DeepSeek Coder consegue explicar em linguagem simples o que aquele código faz, passo a passo. Também pode gerar comentários explicativos ou até documentações resumidas de APIs a partir do código, o que é valioso para entender códigos legados ou aprendidos de repositórios.
- Geração de testes e exemplos: além do código de produção, o modelo pode criar casos de teste unitários ou exemplos de uso para uma dada função. Por exemplo, ele pode sugerir entradas de teste e seus resultados esperados, ajudando a validar se a implementação está correta.
Em conjunto, essas capacidades fazem do DeepSeek Coder um assistente versátil para desenvolvedores. Ele entende o que você deseja construir, escreve o código inicial, completa partes repetitivas, encontra erros e explica o comportamento do programa – tudo em uma única ferramenta de IA. A seguir, veremos algumas aplicações práticas dessas funcionalidades no dia a dia de programação.
Aplicações Práticas para Desenvolvedores
Nesta seção, exploramos como o DeepSeek Coder pode ser usado em situações reais de desenvolvimento, com exemplos em Python e JavaScript. Os exemplos ilustram desde a geração de um algoritmo do zero até a conclusão de código e explicação de funções já existentes.
Exemplo 1: Geração de código em Python
Imagine que você precisa implementar o algoritmo Quick Sort em Python, mas quer economizar tempo. Você pode simplesmente descrever a tarefa e deixar o DeepSeek Coder escrever o código para você. Por exemplo, ao solicitar ao modelo algo como “Implemente a função quick_sort em Python”, ele pode gerar automaticamente uma solução completa:
def quick_sort(arr):
"""Ordena a lista arr usando o algoritmo Quick Sort."""
if len(arr) <= 1:
return arr
else:
pivot = arr[0]
left = [x for x in arr[1:] if x <= pivot]
right = [x for x in arr[1:] if x > pivot]
# Chamada recursiva para sub-listas esquerda e direita
return quick_sort(left) + [pivot] + quick_sort(right)
# Exemplo de uso:
valores = [33, 10, 59, 26, 17]
ordenados = quick_sort(valores)
print(ordenados) # Saída: [10, 17, 26, 33, 59]
Nesse trecho acima, o DeepSeek Coder gerou a função completa do Quick Sort, incluindo a lógica de partição e chamadas recursivas, além de um exemplo de uso. O desenvolvedor pode então ajustar detalhes ou simplesmente integrar essa função ao seu projeto.
Exemplo 2: Autocompletar uma função em JavaScript
O DeepSeek Coder também é excelente para completar automaticamente blocos de código enquanto você desenvolve. Suponha que você esteja escrevendo uma função JavaScript para formatar datas e já tenha iniciado a estrutura básica. Basta fornecer ao modelo o código parcial e ele sugerirá o restante. Por exemplo, dado o início de uma função:
function formatDate(date) {
// Converte um objeto Date em string no formato DD/MM/YYYY
const dia = date.getDate().toString().padStart(2, '0');
const mes = (date.getMonth() + 1).toString().padStart(2, '0');
const ano = date.getFullYear();
// TODO: retornar a data formatada
}
Se pedirmos para o modelo completar o trecho marcado como TODO, ele poderá produzir algo assim:
// TODO: retornar a data formatada
return `${dia}/${mes}/${ano}`;
}
A função completa ficaria:
function formatDate(date) {
// Converte um objeto Date em string no formato DD/MM/YYYY
const dia = date.getDate().toString().padStart(2, '0');
const mes = (date.getMonth() + 1).toString().padStart(2, '0');
const ano = date.getFullYear();
// retorna a data formatada
return `${dia}/${mes}/${ano}`;
}
O modelo reconheceu o contexto e inseriu a linha de código correta para retornar a data formatada. Esse tipo de autocompletar inteligente acelera tarefas triviais e reduz erros de sintaxe ou esquecimento de detalhes.
Exemplo 3: Depuração assistida e explicação de código
Outra aplicação prática é usar o DeepSeek Coder como auxiliar de depuração e compreensão de código. Suponha que você tem uma função complexa cujo resultado não é o esperado, ou simplesmente quer entender seu funcionamento. Você pode pedir ao modelo para revisar o código e explicar o que ele faz ou identificar possíveis problemas.
Por exemplo, imagine a seguinte função Python que deveria calcular o fatorial, mas contém um bug:
def fatorial(n):
if n == 0:
return 1
else:
return n * fatorial(n-2) # bug: subtraindo 2 em vez de 1
Podemos perguntar ao DeepSeek Coder: “Encontre o erro na função fatorial acima e corrija-o.” Como resposta, o modelo pode explicar o problema e propor uma correção:
DeepSeek Coder: A implementação atual está reduzindo o valor de
nem 2 a cada chamada recursiva, em vez de 1. Isso fará com que o cálculo pule valores e eventualmentense torne negativo, causando chamadas recursivas incorretas ou um resultado errado. Para corrigir, a chamada recursiva deve usarn-1em vez den-2. Por exemplo:def fatorial(n): if n == 0: return 1 else: return n * fatorial(n-1)Com essa alteração, a função calculará o fatorial corretamente (n * (n-1) * (n-2) * … * 1).
No exemplo acima, o DeepSeek Coder detectou o erro lógico no código (o decremento incorreto) e forneceu uma explicação clara junto com a solução corrigida. Além de depurar, esse mesmo mecanismo de análise do modelo pode ser utilizado para explicar trechos de código. Basta solicitar algo como “Explique o que faz esta função” e o modelo retornará uma descrição detalhada do seu funcionamento, útil para aprendizado ou documentação.
Orientações para Integração via API ou Uso Local

Uma das vantagens do DeepSeek Coder é a flexibilidade de acesso: os desenvolvedores podem usá-lo através de uma API na nuvem ou executá-lo localmente em suas próprias máquinas/servidores. A seguir, explicamos as duas abordagens e como integrá-las aos seus projetos.
Integração via API na Plataforma DeepSeek
A DeepSeek AI oferece uma plataforma online que hospeda o modelo e disponibiliza uma API compatível com o padrão OpenAI. Isso significa que, se você já utilizou serviços como a API do GPT, vai se sentir em casa – as chamadas são semelhantes, mudando apenas a URL e a chave de acesso. Você pode obter uma chave de API criando uma conta na plataforma DeepSeek (site oficial) e então realizar requisições HTTP para os endpoints fornecidos. Por exemplo, uma chamada via curl ou utilizando a biblioteca requests em Python seguiria o formato:
POST https://platform.deepseek.com/api/generate
Headers: Authorization: Bearer <sua-chave-de-api>
Body: {
"model": "deepseek-coder",
"prompt": "Descrição ou pergunta sobre código"
}
A resposta virá em formato JSON contendo o resultado gerado (código ou explicação solicitada). A API é RESTful e utiliza modelos inference de texto, de forma muito similar ao uso da API da OpenAI. Vale notar que este serviço funciona em modelo pay-as-you-go, ou seja, você paga conforme o uso, a um preço competitivo. Essa opção de nuvem é interessante para quem não quer se preocupar com infraestrutura local ou precisa escalonar o uso para múltiplos desenvolvedores em um time.
Uso Local do Modelo (Self-Hosted)
Para quem prefere controlar a infraestrutura ou trabalhar offline, o DeepSeek Coder também pode ser executado localmente. Os pesos do modelo (model weights) estão disponíveis para download – inclusive através do Hub do Hugging Face – permitindo que você carregue o modelo em seu próprio ambiente.
Os requisitos de hardware vão depender do tamanho do modelo escolhido. Versões menores (como ~6,7B de parâmetros) podem ser rodadas em GPUs de ~16 GB (ou até mesmo na CPU, com performance reduzida), enquanto a versão completa de 33B pode exigir GPUs de 24~32 GB (ou técnicas de otimização como quantização em 4-bits para caber em menos memória).
Há também variantes DeepSeek Coder V2 muito maiores com tecnologia de especialistas (Mixture-of-Experts), mas estas demandam servidores de alto porte e são voltadas a casos de uso corporativos avançados.
Para usar localmente via Python, por exemplo, você pode utilizar a biblioteca Hugging Face Transformers. Após baixar os pesos, o carregamento é feito com poucas linhas de código, conforme ilustrado abaixo:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-6.7B-Instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-6.7B-Instruct", torch_dtype="auto").cuda()
prompt = "Explique o c\u00f3digo para calcular o n\u00famero Fibonacci."
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
No exemplo acima, carregamos a versão de ~6,7 bilhões de parâmetros (instruções) do DeepSeek Coder e geramos uma resposta para um prompt de exemplo. Ferramentas como Ollama, text-generation-webui ou vLLM também oferecem formas simplificadas de executar modelos grandes localmente, com interfaces amigáveis ou maior velocidade de inferência.
Dica: Ao rodar localmente, certifique-se de usar a versão Instruct do modelo para interações com linguagem natural (prompts do usuário). As versões base tendem a esperar somente continuação de código e podem não responder adequadamente a perguntas/descritivos em texto. A versão instruída foi afinada justamente para seguir comandos e dialogar de forma mais útil.
Benefícios para Produtividade e Colaboração em Equipes
A incorporação do DeepSeek Coder no fluxo de trabalho diário pode trazer ganhos significativos de produtividade e melhorar a colaboração em times de engenharia de software. Abaixo, listamos alguns benefícios-chave:
- Aceleração de tarefas repetitivas: Muitas atividades rotineiras – escrever funções utilitárias, criar classes boilerplate, converter formatos de dados – podem ser automatizadas pelo modelo. Em vez de codificar tudo manualmente, o desenvolvedor pode delegar essas partes ao DeepSeek Coder e focar em aspectos mais complexos do sistema. Isso agiliza entregas e reduz o cansaço com “tarefas braçais” de código.
- Codificação como par programador (pair programming): O modelo atua como um colega virtual que está disponível a todo momento para discutir soluções. Ele pode propor aproximações diferentes para um problema, sugerir algoritmos alternativos ou melhorar um trecho escrito pelo desenvolvedor. Essa dinâmica de pair programming com IA enriquece o processo de desenvolvimento, trazendo ideias novas e ajudando a evitar armadilhas comuns.
- Aprendizado e capacitação da equipe: Para times com desenvolvedores juniores ou em fase de aprendizado de novas linguagens, o DeepSeek Coder serve como uma ferramenta educacional. Ele explica código desconhecido, mostra exemplos de uso de bibliotecas e reforça boas práticas de programação em suas respostas. Desse modo, ao interagir com o modelo, a equipe acaba absorvendo conhecimento e se aprimorando tecnicamente.
- Revisão de código e qualidade: Integrado ao processo de code review, o modelo pode atuar como um “segundo par de olhos”, apontando possíveis erros ou trechos que podem ser refatorados. Embora não substitua a revisão humana, ter sugestões automáticas ajuda a pegar problemas mais cedo e garante uma base de código mais consistente. Além disso, ao gerar testes unitários sugeridos, o DeepSeek Coder incentiva a cobertura de testes e a confiança no software produzido.
- Documentação e comunicação: Em equipes grandes, nem sempre todos entendem de imediato o código escrito por outros. Utilizar o DeepSeek Coder para gerar descrições claras de funções ou módulos facilita a comunicação entre os membros. Ele pode produzir resumos que servem de documentação inicial, que depois podem ser refinados pelos devs. Isso promove uma melhor troca de conhecimento dentro do time e menos dependência de indivíduos específicos para entender certas partes do sistema.
Em suma, quando bem aproveitado, o DeepSeek Coder não só aumenta a velocidade de programação, mas também eleva a qualidade do trabalho em grupo. Os desenvolvedores conseguem entregar mais valor em menos tempo, aprendendo uns com os outros (via IA) e reduzindo retrabalho.
Boas Práticas para Adoção Segura e Eficiente
Apesar dos benefícios, é importante adotar o DeepSeek Coder de forma consciente. A seguir, algumas boas práticas recomendadas para utilizar o modelo com segurança e obter os melhores resultados:
- Revisão humana contínua: Sempre revise o código gerado pelo modelo. Embora ele acerte muita coisa, não é infalível – pode produzir soluções não otimizadas ou até erros sutis. Trate a sugestão da IA como um rascunho inicial que deve passar pelo crivo de um desenvolvedor experiente antes de integrar à base de código principal. Testes automatizados são aliados importantes nesse processo.
- Uso gradual e avaliação: Introduza o modelo aos poucos no seu fluxo de trabalho. Comece pedindo ajuda em tarefas pequenas e avalie a qualidade das respostas. Com o tempo, à medida que você ganhar confiança e entender melhor os pontos fortes e fracos do DeepSeek Coder, amplie seu uso para tarefas mais críticas.
- Proteção de dados sensíveis: Se estiver usando a versão em nuvem (API), evite enviar informações proprietárias ou dados sigilosos nos prompts, pois eles serão processados em servidores externos. Para projetos com código altamente confidencial, considere usar o modelo localmente, onde você mantém total controle sobre o ambiente e os dados.
- Contexto adequado nos prompts: Para obter respostas mais úteis, forneça o máximo de contexto relevante ao fazer uma pergunta. Por exemplo, inclua a assinatura da função, explique o objetivo ou forneça um trecho de código relacionado. O DeepSeek Coder aproveita muito bem contextos maiores (especialmente com 16k tokens), então detalhar o prompt pode resultar em soluções mais precisas.
- Atualização e versões do modelo: Fique atento às atualizações da DeepSeek AI sobre novos modelos ou melhorias. O DeepSeek Coder V2, por exemplo, expandiu o suporte de ~86 para 338 linguagens de programação e ampliou o contexto para 128 mil tokens. Sempre que possível, utilize as versões mais recentes/instrucionadas, pois elas tendem a corrigir limitações e trazer ganhos de desempenho.
- Conheça a licença e limites de uso: Mesmo sendo livre para uso comercial, o modelo possui uma licença customizada. Tenha certeza de ler os termos (baseados na licença CreativeML Open RAIL, similar à do Stable Diffusion, conforme o autor explicou) e entenda que ele pode ocasionalmente gerar trechos de código presentes nos dados de treinamento. Evite dependência cega: use o bom senso e monitore possíveis implicações legais se for incorporar grandes partes do código gerado em projetos proprietários.
Seguindo essas práticas, você garante uma adoção segura, ética e eficaz do DeepSeek Coder, colhendo seus benefícios enquanto minimiza riscos.
Desempenho, Limitações e Contexto Ideal de Uso
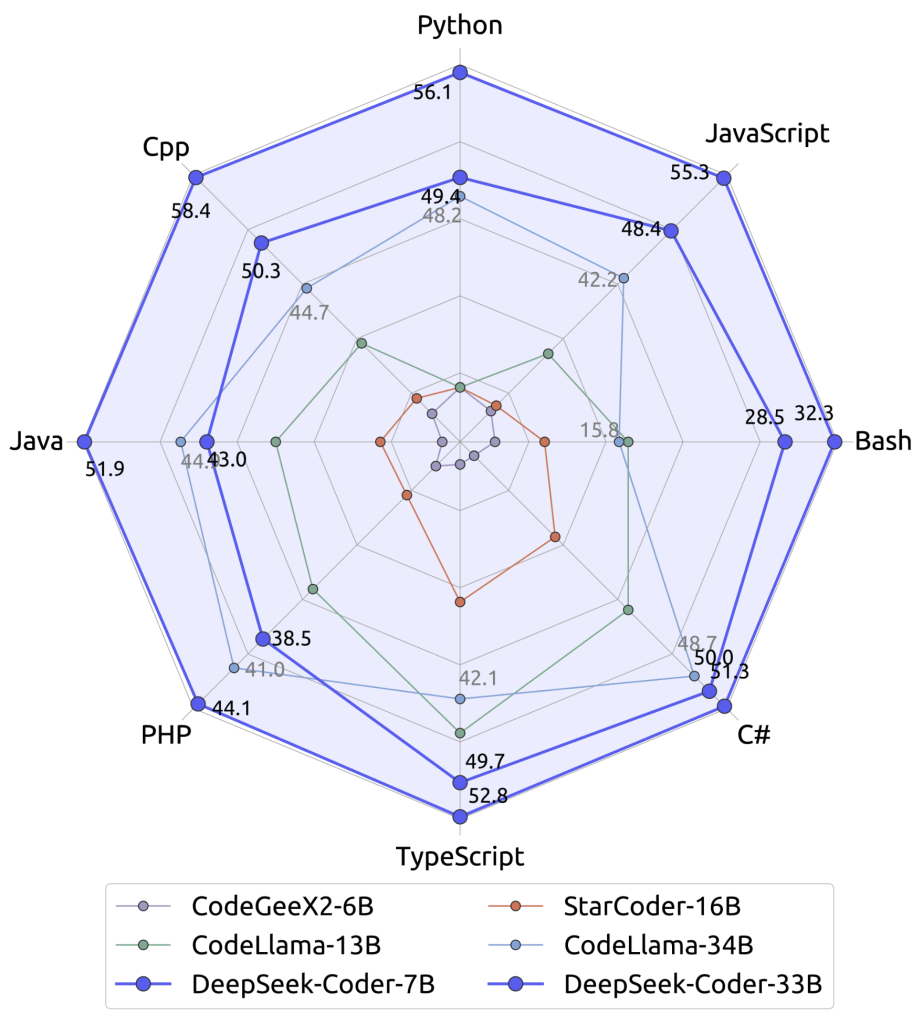
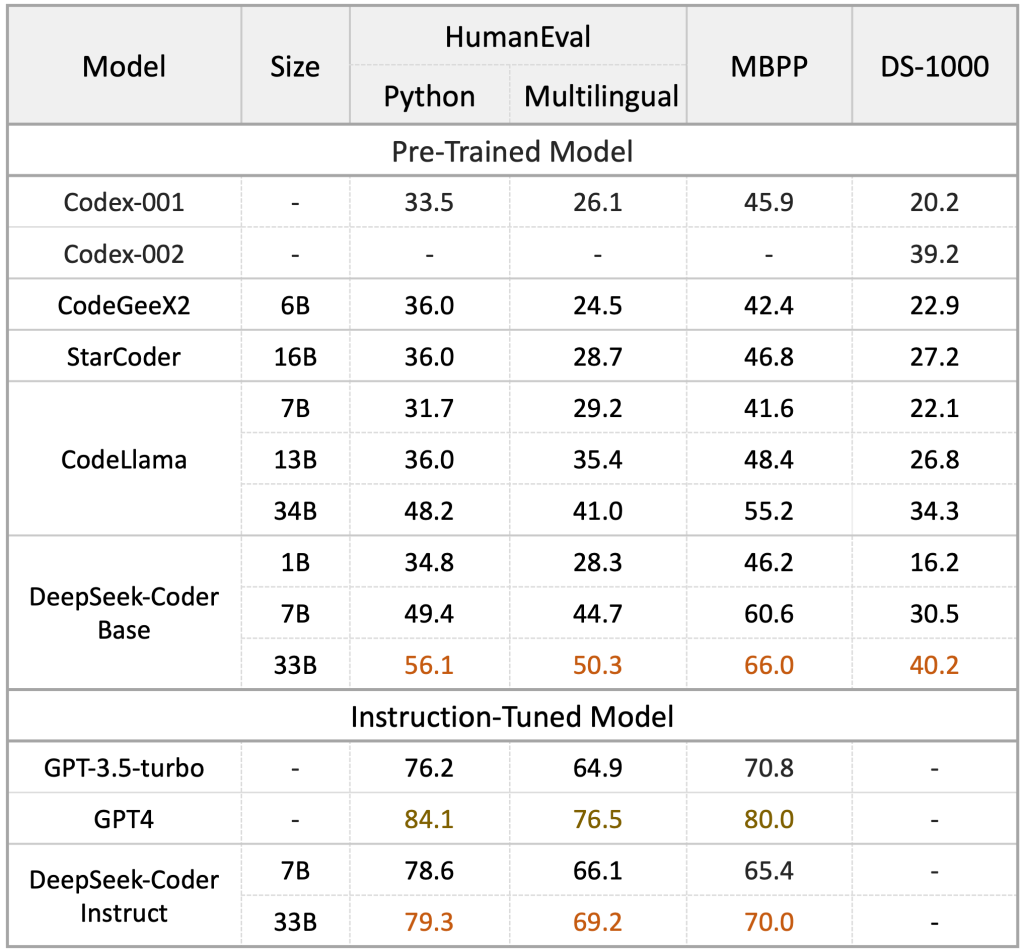
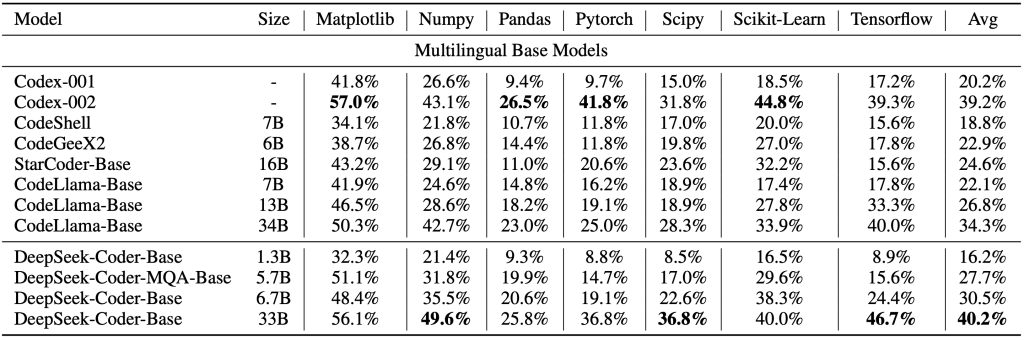
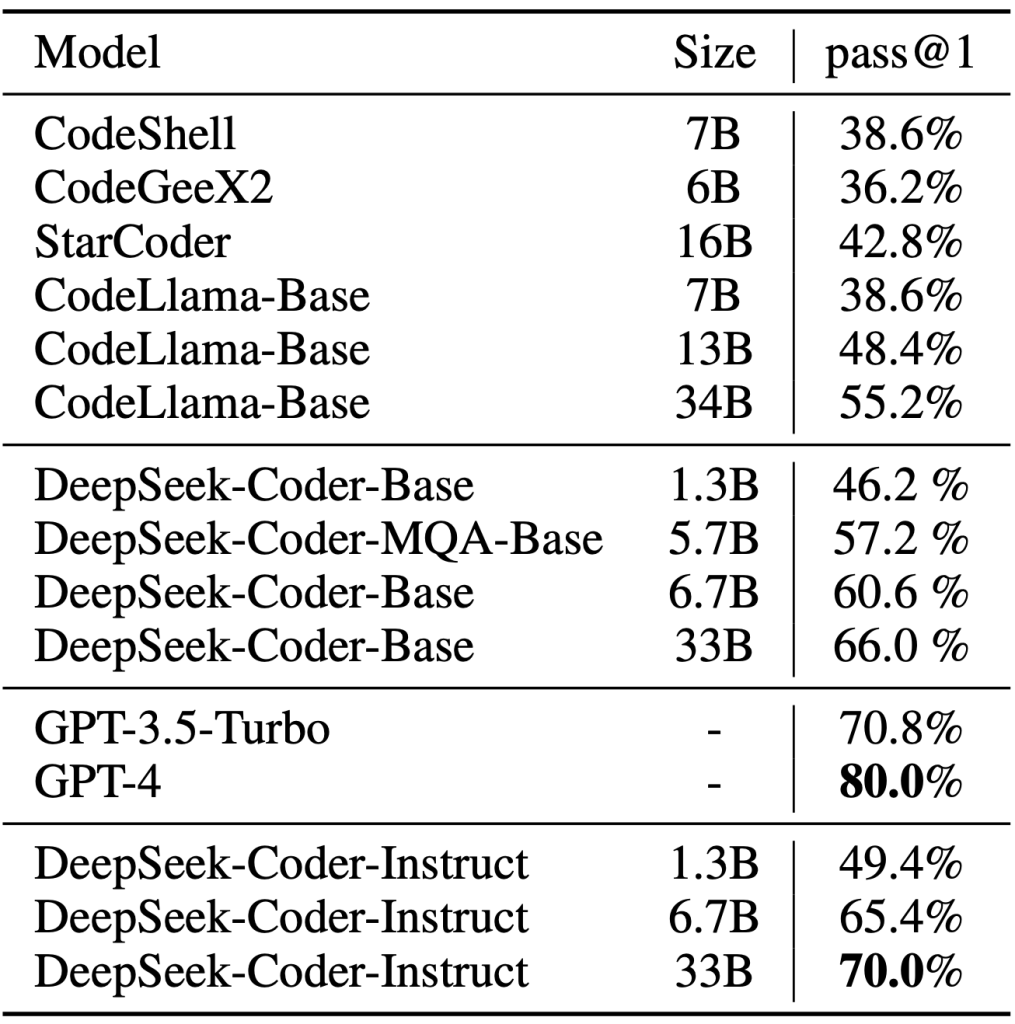
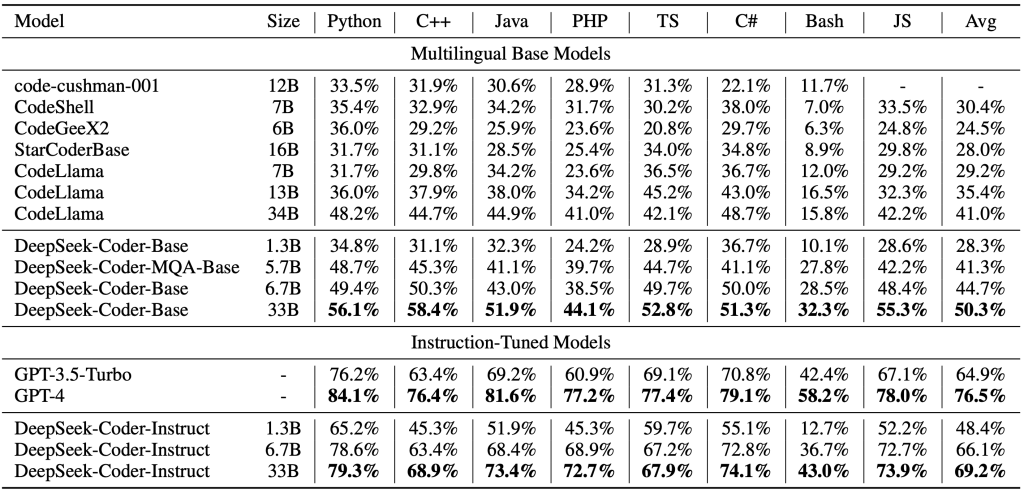
O desempenho do DeepSeek Coder tem se mostrado excelente em tarefas de código, muitas vezes equiparável a soluções proprietárias de ponta. Benchmarks como HumanEval e MBPP indicam que as versões maiores (como a de 33B de parâmetros) atingem taxa de acerto muito alta em problemas de programação, figurando entre os melhores modelos open-source disponíveis.
Isso significa que, para a maioria das tarefas de desenvolvimento comuns (gerar funções, resolver desafios de algoritmos, etc.), o modelo fornece respostas corretas na primeira tentativa em boa parte dos casos. Além disso, a equipe DeepSeek continua evoluindo o modelo – a versão V2 mencionada trouxe não apenas ampliação do suporte a linguagens e contexto, mas também melhorias nas habilidades de raciocínio lógico e matemático, tornando-o mais robusto em desafios que envolvem cálculos ou lógica complexa.
No entanto, é importante ter clareza sobre as limitações. Assim como outros modelos de linguagem, o DeepSeek Coder pode ocasionalmente gerar código sintaticamente válido mas que não resolve exatamente o problema pretendido (por exemplo, um bug em um caso extremo ou uma solução menos eficiente).
Ele depende muito do padrão de prompt fornecido; perguntas ambíguas ou incompletas podem levar a respostas igualmente vagas. Por ter sido treinado majoritariamente em inglês, interações em português podem não ser tão precisas – embora o código em si seja independente de idioma, descrições de problemas muito coloquiais em português podem não ser interpretadas com a mesma precisão que em inglês.
Além disso, o modelo não possui conhecimento atualizado em tempo real: seu entendimento se baseia em padrões aprendidos nos dados de treinamento (até certo período). Portanto, se questionado sobre uma biblioteca lançada ontem ou uma API que mudou na última versão, ele pode não saber ou pode confundir com algo semelhante. Nessas situações, caberá ao desenvolvedor atualizar manualmente o código sugerido.
O contexto ideal de uso do DeepSeek Coder é como um assistente de programação integrado ao fluxo de trabalho, e não como um sistema autônomo completo. Ele brilha quando usado para: prototipar soluções rapidamente, tirar dúvidas sobre implementação de algo, automatizar partes chatas do código e servir de segunda opinião em problemas de lógica.
Em tarefas bem definidas e repetitivas, a economia de tempo é notável. Em projetos educacionais ou experimentais, ele acelera a curva de aprendizagem. Entretanto, para módulos de software que exigem alto grau de confiança, otimização fina ou que sejam totalmente inovadores (onde não há muitos exemplos nos dados de treino), o desenvolvedor deve estar pronto para intervir e ajustar o resultado.
Em resumo, use o DeepSeek Coder como ferramenta de suporte para potencializar sua capacidade, sabendo que o input e o feedback humanos ainda são peças-chave para um produto final de qualidade.
Conclusão
O DeepSeek Coder representa um passo empolgante na interseção entre inteligência artificial e desenvolvimento de software. Ao longo deste artigo, vimos como esse modelo de IA voltado para código pode transformar a forma de programar, aliviando tarefas repetitivas, ajudando a encontrar soluções e atuando como um verdadeiro copiloto para desenvolvedores. Com suas amplas capacidades – de escrever código a explicá-lo – e a flexibilidade de uso via API ou localmente, a ferramenta se adapta a diversos cenários e equipes.
Para os desenvolvedores brasileiros, o DeepSeek Coder abre oportunidades de aumentar produtividade e aprendizado no dia a dia de trabalho. Seja você um programador experiente buscando agilizar entregas, ou um iniciante querendo apoio para entender novos conceitos, vale a pena experimentar o DeepSeek Coder em seus projetos. Você pode começar acessando o chat demo no site oficial ou integrando o modelo a um editor/IDE de sua preferência. Lembre-se das boas práticas discutidas para obter o máximo de benefícios com segurança.
Em um mundo onde a colaboração humano-IA se torna cada vez mais real, ferramentas como o DeepSeek Coder se destacam por empoderar desenvolvedores – não substituindo-os, mas elevando suas capacidades. Que este guia sirva como ponto de partida para você aproveitar o melhor que essa tecnologia oferece. Boas codificações, e que seu novo “par programador” de IA ajude a levar seus projetos a um próximo nível.


