
Atualizado e verificado em 17 de abril de 2026. Esta página resume o que é o DeepSeek V3.2, como ele se encaixa no ecossistema DeepSeek, como usar o modelo pela DeepSeek API e quais cuidados técnicos são importantes para produção. O objetivo é separar claramente fatos oficiais, boas práticas de integração e recomendações editoriais para desenvolvedores em português.
O DeepSeek V3.2 é um modelo de linguagem de grande porte da DeepSeek AI voltado a raciocínio, programação, uso de ferramentas e tarefas com contexto longo. Ele foi anunciado oficialmente em 1º de dezembro de 2025 como sucessor estável do DeepSeek V3.2-Exp. Segundo a documentação oficial, na API pública atual os IDs deepseek-chat e deepseek-reasoner correspondem ao DeepSeek-V3.2 com limite de contexto de 128K tokens, embora a versão usada no app e na web possa diferir da versão servida via API.
Resumo essencial: para novas integrações, trate deepseek-chat como o modo sem pensamento explícito do DeepSeek V3.2 e deepseek-reasoner como o modo com raciocínio. Esses nomes são IDs de modelo/modo, não endpoints separados. O endpoint principal de chat continua sendo /chat/completions, usando https://api.deepseek.com como base URL.
Resumo rápido do DeepSeek V3.2
| Item | Informação atual |
|---|---|
| Lançamento oficial | 1º de dezembro de 2025. |
| Status na API | Modelo atual associado aos IDs deepseek-chat e deepseek-reasoner. |
| Contexto | 128K tokens na API pública, conforme documentação oficial de Models & Pricing. |
| Modo sem pensamento | deepseek-chat — indicado para respostas diretas, chat, geração de texto, código, JSON e integrações gerais. |
| Modo com pensamento | deepseek-reasoner ou thinking: {"type": "enabled"} — indicado para problemas que exigem raciocínio mais profundo. |
| Tool calls | Suportados em modo sem pensamento e em Thinking Mode. A aplicação ainda precisa executar as ferramentas externas. |
| FIM Completion | Disponível para deepseek-chat em beta; não disponível para deepseek-reasoner. |
| V3.2-Speciale | Variante de alto raciocínio anunciada para avaliação. O endpoint temporário oficial informado pela DeepSeek expirou em 15 de dezembro de 2025; portanto, não deve ser tratado como endpoint atual de produção. |
| App/Web vs API | A documentação oficial afirma que a versão da API pode diferir da versão usada no DeepSeek App e na web oficial. |
O que mudou em relação ao V3.2-Exp
O DeepSeek V3.2 consolida a linha experimental V3.2-Exp em uma versão estável para uso amplo. A versão experimental introduziu o DeepSeek Sparse Attention (DSA), um mecanismo de atenção esparsa pensado para reduzir custo computacional em contextos longos. O V3.2 mantém essa direção, mas é apresentado pela DeepSeek como a versão sucessora oficial, disponível no App, na Web e na API.
Em termos práticos, a mudança mais importante para desenvolvedores é esta: se você estava usando a API com deepseek-chat ou deepseek-reasoner, a documentação oficial indica que esses IDs foram atualizados para DeepSeek-V3.2 desde 1º de dezembro de 2025. Não é necessário criar uma URL especial para “V3.2” no uso normal da API; o modelo é selecionado pelo campo model.
Arquitetura: DSA, MoE e foco em contexto longo
O DeepSeek V3.2 segue a família técnica da DeepSeek baseada em Transformer e Mixture-of-Experts (MoE), com foco em eficiência. A DeepSeek descreve três pilares técnicos para o V3.2: DeepSeek Sparse Attention (DSA), escalonamento de reinforcement learning no pós-treinamento e uma pipeline de síntese de tarefas agentic para treinar melhor o uso de ferramentas.
O DSA é a parte mais relevante para contexto longo. Em vez de permitir que cada token atenda a todo o histórico com custo crescente, o modelo seleciona partes relevantes do contexto para reduzir a complexidade computacional preservando qualidade. Para desenvolvedores, o efeito prático esperado é uma melhor relação entre contexto longo, latência e custo, especialmente em tarefas como análise de documentação extensa, logs, especificações técnicas e bases de conhecimento.
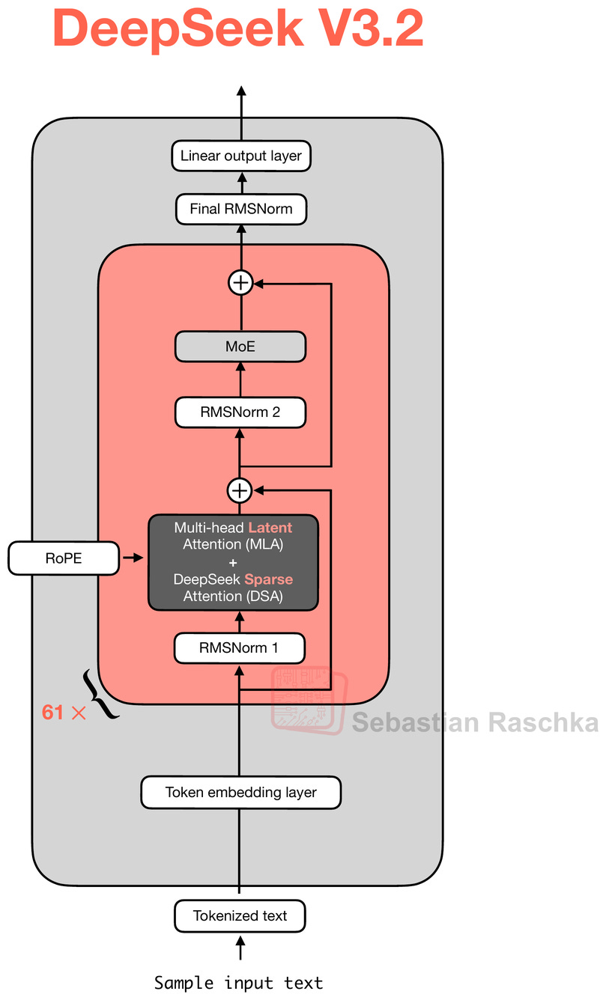
Quando usar deepseek-chat e quando usar deepseek-reasoner
Na API, o ponto mais importante é escolher corretamente o modo de operação. O ID deepseek-chat representa o DeepSeek V3.2 em modo sem pensamento explícito. Ele é adequado para assistentes de texto, atendimento, geração e revisão de conteúdo, programação, JSON, tool calls convencionais e cenários em que latência e objetividade importam.
O ID deepseek-reasoner representa o DeepSeek V3.2 em Thinking Mode. Ele deve ser usado quando a tarefa exige mais decomposição lógica, análise de várias etapas, investigação técnica, raciocínio matemático, planejamento ou uso de ferramentas com raciocínio intermediário. Esse modo pode retornar reasoning_content junto com a resposta final em content.
| Uso | Melhor escolha | Observação |
|---|---|---|
| Chat geral, FAQ, respostas rápidas | deepseek-chat | Mais direto e simples para produção. |
| Programação, code review, documentação técnica | deepseek-chat ou deepseek-reasoner | Use reasoner quando houver investigação complexa. |
| Problemas de lógica, matemática ou planejamento | deepseek-reasoner | Thinking Mode tende a ser mais adequado para múltiplas etapas. |
| Tool calls simples | deepseek-chat | A aplicação executa a ferramenta e devolve o resultado ao modelo. |
| Tool calls com raciocínio intermediário | deepseek-reasoner ou thinking habilitado | Exige implementar corretamente o envio de reasoning_content durante o mesmo turno. |
| Fill-in-the-middle para código | deepseek-chat | FIM está em beta e não é suportado no Thinking Mode. |
Integração via API
A DeepSeek API usa um formato compatível com a API da OpenAI. Isso significa que muitos SDKs e clientes compatíveis com OpenAI podem ser adaptados alterando a base_url para https://api.deepseek.com e usando uma chave da plataforma DeepSeek. O endpoint comum para chat é /chat/completions.
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "Responda em português do Brasil, com clareza e precisão."},
{"role": "user", "content": "Explique o que é DeepSeek Sparse Attention em linguagem simples."}
],
"stream": false
}'Para ativar raciocínio, use deepseek-reasoner como valor de model ou habilite explicitamente o parâmetro thinking, conforme a documentação oficial. Em Python, usando um SDK compatível com OpenAI, a estrutura conceitual fica assim:
from openai import OpenAI
client = OpenAI(
api_key="<DeepSeek API Key>",
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=[
{"role": "user", "content": "Analise este problema de arquitetura e proponha uma solução."}
]
)
final_answer = response.choices[0].message.content
reasoning = response.choices[0].message.reasoning_contentPara compatibilidade com softwares existentes, a DeepSeek também permite usar https://api.deepseek.com/v1 como base URL. A documentação deixa claro que esse v1 não tem relação com a versão do modelo; ele é apenas uma rota de compatibilidade.
Parâmetros importantes e cuidados com Thinking Mode
No modo sem pensamento, parâmetros como temperature podem ser usados para ajustar a criatividade ou previsibilidade da resposta. A página oficial de parâmetros recomenda valores diferentes por caso de uso, por exemplo temperatura baixa para código e matemática e valores mais altos para conversa geral, tradução e escrita criativa.
No Thinking Mode, porém, há uma diferença crítica: a documentação oficial informa que temperature, top_p, presence_penalty e frequency_penalty não têm efeito. Além disso, logprobs e top_logprobs podem gerar erro. Portanto, não recomende esses parâmetros como ferramenta de controle para deepseek-reasoner.
Regra prática: use temperature e top_p em conteúdo sobre execução local ou modo sem pensamento quando fizer sentido. Para Thinking Mode na API, explique que esses parâmetros não controlam a geração conforme a documentação oficial.
Conversas multi-turno: a API é stateless
Um erro comum é imaginar que a API “lembra” automaticamente conversas anteriores. A documentação oficial afirma que /chat/completions é uma API stateless: o servidor não grava o contexto das requisições do usuário. Para manter uma conversa multi-turno, sua aplicação precisa armazenar o histórico relevante e reenviá-lo no campo messages em cada nova chamada.
Isso impacta custo, privacidade e arquitetura. Em produção, evite reenviar histórico irrelevante. Prefira resumir conversas longas, recuperar apenas trechos importantes e aplicar políticas claras de retenção de dados. Se o seu produto lida com dados sensíveis, implemente anonimização, controles de acesso e logs auditáveis.
Tool calls: o modelo sugere, a aplicação executa
O DeepSeek V3.2 suporta tool calls, inclusive no Thinking Mode. Ainda assim, o modelo não executa APIs externas sozinho. Ele retorna uma chamada estruturada, por exemplo uma função para consultar clima, banco de dados, CRM, documentação interna ou sistema de tickets. O backend da sua aplicação executa a função real, valida o resultado e envia o retorno de volta ao modelo.
Para usar tool calls com segurança, defina schemas estritos, valide argumentos, limite permissões e registre as ações executadas. Nunca permita que o modelo execute comandos arbitrários em produção. Em fluxos críticos, adicione aprovação humana antes de ações irreversíveis, como apagar dados, enviar mensagens a clientes ou alterar configurações de infraestrutura.
JSON, FIM, cache e streaming
O DeepSeek V3.2 pode ser usado em saídas estruturadas. Para JSON Output, a documentação recomenda definir response_format como {"type": "json_object"}, incluir a palavra “json” no prompt e fornecer um exemplo do formato desejado. Também é importante ajustar max_tokens para evitar truncamento.
O FIM Completion, útil para completar trechos de código no meio de um arquivo, está disponível em beta para deepseek-chat, mas não para deepseek-reasoner. Já o Context Caching é habilitado por padrão para todos os usuários da API: quando requisições repetem prefixos de contexto, parte dos tokens de entrada pode contar como cache hit. Esse recurso ajuda em prompts com documentos longos, few-shot examples e conversas com prefixos repetidos, mas funciona em regime best-effort e não garante 100% de acerto de cache.
Para experiência de usuário em chats e assistentes, considere usar stream: true. A própria FAQ da DeepSeek observa que a API retorna respostas completas por padrão quando stream=false, enquanto streaming melhora a interatividade ao enviar tokens gradualmente.
Preços e impacto de custo
Os preços oficiais da DeepSeek API são definidos por 1 milhão de tokens e podem mudar. Em 17 de abril de 2026, a página oficial de Models & Pricing lista os seguintes valores para DeepSeek-V3.2: US$ 0.028 por 1M input tokens com cache hit, US$ 0.28 por 1M input tokens com cache miss e US$ 0.42 por 1M output tokens. Para uma explicação em português, consulte também nossa página de preços do DeepSeek.
Em aplicações reais, o custo não depende só do preço por token. Ele depende do tamanho do prompt, do histórico reenviado, do uso de contexto longo, do número de chamadas, do volume de output e da frequência de cache hits. Para produção, monitore prompt_cache_hit_tokens, prompt_cache_miss_tokens, tokens de saída, latência e taxa de erro.
DeepSeek V3.2-Speciale: cuidado com o status atual
O DeepSeek V3.2-Speciale foi anunciado como uma variante de alto raciocínio voltada a avaliação e pesquisa. A própria DeepSeek informou que o endpoint temporário da Speciale ficaria disponível até 15 de dezembro de 2025, 15:59 UTC, com o mesmo preço do V3.2 e sem tool calls. Como essa data já passou, não trate a URL temporária da Speciale como opção atual de produção.
Se o seu objetivo é integrar a API pública hoje, comece por deepseek-chat ou deepseek-reasoner. Se o objetivo é pesquisa, comparação ou execução local, consulte o repositório oficial no Hugging Face e confirme o status de pesos, licença, requisitos de hardware e ferramentas de inferência.
Execução local e open source
Os pesos do DeepSeek V3.2 foram publicados pela DeepSeek no Hugging Face sob licença MIT. Isso abre a possibilidade de pesquisa, fine-tuning, quantização e execução local, dependendo da infraestrutura disponível. Porém, “open source” ou “open weight” não significa custo zero: a organização ainda precisa pagar por GPU, armazenamento, inferência, engenharia, segurança, observabilidade e manutenção.
A recomendação oficial de temperature = 1.0 e top_p = 0.95 aparece no contexto de execução local no Hugging Face. Não misture essa recomendação com Thinking Mode da API, onde a documentação oficial diz que esses parâmetros não têm efeito.
Casos de uso técnicos para desenvolvedores
1. Assistente de programação e code review
O DeepSeek V3.2 pode ajudar a gerar funções, explicar trechos de código, revisar pull requests, sugerir testes, documentar APIs e identificar inconsistências. Para repositórios grandes, combine o modelo com busca semântica, seleção de arquivos relevantes e limites de contexto para evitar prompts desnecessariamente longos.
2. Análise de logs e incidentes
Em DevOps e SRE, o modelo pode resumir logs, encontrar padrões, explicar erros e sugerir hipóteses de causa raiz. Para não transformar o contexto longo em ruído, envie logs estruturados, destaque timestamps importantes e inclua metadados como serviço, ambiente, versão e janela temporal.
3. Documentação técnica
O V3.2 pode transformar código, changelogs, issues e especificações em documentação mais clara. Mesmo assim, a documentação gerada deve ser revisada por humanos, especialmente quando envolve APIs públicas, segurança, compliance ou instruções operacionais.
4. Suporte técnico interno
Empresas podem usar o modelo em copilotos internos que respondem dúvidas sobre infraestrutura, produto, políticas, banco de dados ou incidentes passados. O melhor resultado costuma vir de uma arquitetura com retrieval: o modelo recebe trechos relevantes de fontes internas e responde com base neles, em vez de depender apenas de conhecimento geral.
5. Agentes e pipelines automatizados
O V3.2 é especialmente relevante para agentes que combinam raciocínio, tool calls e etapas sucessivas. Exemplos incluem triagem de tickets, análise de pull requests, geração de relatórios, assistentes de dados, diagnósticos de infraestrutura e fluxos semi-autônomos. Em todos os casos, a aplicação deve controlar permissões e validar cada ação.
Controle, segurança e limites
Mesmo sendo um modelo avançado, o DeepSeek V3.2 pode errar, alucinar, omitir detalhes ou responder com excesso de confiança. Para usos críticos, valide respostas em fontes confiáveis e mantenha revisão humana. Isso é especialmente importante em segurança, jurídico, saúde, finanças, infraestrutura e decisões que afetem usuários reais.
Em aplicações públicas, adicione filtros de entrada, filtros de saída, rate limiting, detecção de abuso, logs anonimizados e monitoramento de qualidade. Em aplicações internas, controle quais dados podem ser enviados para a API e quais precisam ficar em ambiente próprio. Não envie segredos, senhas, chaves privadas, dados pessoais sensíveis ou informações confidenciais sem uma política explícita de segurança.
Ao usar tool calls, trate o modelo como um planejador probabilístico, não como autoridade final. Ele pode sugerir uma função ou argumento incorreto. O backend deve validar schema, permissões, limites e consequências antes de executar qualquer ação.
Como o DeepSeek V3.2 se relaciona com App, Chat e páginas do site
Se você quer testar o DeepSeek de forma simples no celular, veja a página DeepSeek App. Se quer experimentar uma interface rápida em português, acesse o DeepSeek Chat em português deste site. Para integrar o modelo em produtos, comece por DeepSeek API, preços e FAQ.
Esta página faz parte da seção de modelos DeepSeek e deve ser lida junto com os guias sobre DeepSeek R1, DeepSeek V3 e DeepSeek V3.2-Exp. Para entender aplicações práticas, consulte também casos de uso e soluções com DeepSeek AI.
Conclusão
O DeepSeek V3.2 é a versão central atual da família DeepSeek na API pública, conectando raciocínio, tool calls, contexto longo e uso em aplicações técnicas. A forma correta de usá-lo hoje é por meio dos IDs deepseek-chat e deepseek-reasoner, lembrando que eles representam modos do modelo na API, não endpoints independentes.
Para produção, a recomendação é simples: use deepseek-chat quando precisar de respostas diretas e eficientes; use deepseek-reasoner quando a tarefa exigir análise profunda; trate tool calls como ações controladas pelo seu backend; não dependa da API para “lembrar” conversas; e monitore tokens, cache, latência, qualidade e segurança. Com essa abordagem, o DeepSeek V3.2 pode servir como base robusta para assistentes, agentes, automações e produtos técnicos em português.
deepseek-portugues.chat é um projeto independente, sem afiliação oficial com a DeepSeek ou seus desenvolvedores. As informações desta página foram revisadas com base na documentação oficial disponível em 17 de abril de 2026. Para decisões de produção, confirme sempre a documentação oficial, os termos de uso e a página atual de preços.


