
O DeepSeek V3 é um modelo de linguagem de grande porte (Large Language Model – LLM) desenvolvido pelo laboratório DeepSeek, focado em fornecer capacidades avançadas de inteligência artificial generativa. Esse modelo foi projetado para entender e gerar texto de forma altamente competente, servindo a diversos propósitos em tecnologia e desenvolvimento.
Com uma arquitetura inovadora de combinação de especialistas (MoE) e impressionantes 671 bilhões de parâmetros (dos quais 37 bilhões são ativados por token), o DeepSeek V3 se destaca pela eficiência e poder de processamento. Treinado em 14,8 trilhões de tokens de dados diversificados e de alta qualidade, ele foi refinado através de etapas de ajuste fino supervisionado e aprendizado por reforço para atingir um desempenho de ponta. Em outras palavras, o DeepSeek V3 é capaz de realizar tarefas complexas de linguagem natural – desde entender consultas e gerar respostas contextualmente relevantes até escrever código ou resolver problemas matemáticos – com rapidez e precisão notáveis.
Como um modelo aberto e de última geração, o DeepSeek V3 foi concebido para ser utilizado por desenvolvedores e profissionais de tecnologia em soluções práticas. Diferentemente de muitos modelos proprietários, o DeepSeek V3 enfatiza a acessibilidade e colaboração da comunidade: tanto o modelo quanto seus artigos de pesquisa associados foram disponibilizados abertamente, promovendo transparência e permitindo que equipes de engenharia e pesquisa aprendam e construam em cima dessa tecnologia.
Ao longo deste guia completo, exploraremos em detalhes a arquitetura e características técnicas do DeepSeek V3, suas aplicações práticas (especialmente do interesse de desenvolvedores), exemplos de uso com código Python, como integrar o modelo via API ou localmente, os benefícios e vantagens que ele traz para times de engenharia/produto, melhores práticas de uso e considerações de segurança, além de aspectos de desempenho e limitações. Ao final, você terá uma compreensão abrangente desse modelo de linguagem e estará pronto para explorar o DeepSeek V3 em seus próprios projetos.
Arquitetura e Características Técnicas
Mixture-of-Experts (MoE) e Parâmetros: O DeepSeek V3 adota uma arquitetura do tipo Mixture-of-Experts, o que significa que o modelo é dividido em diversos “especialistas” neurais que colaboram para gerar respostas mais eficazes. Ele possui 671 bilhões de parâmetros no total, porém utiliza de forma inteligente apenas 37 bilhões de parâmetros por token durante a inferência, graças ao mecanismo MoE. Esse design permite que diferentes partes do modelo sejam ativadas conforme necessário para cada pedaço da entrada, otimizando a eficiência computacional sem sacrificar a capacidade.
Em termos de capacidade de contexto, o DeepSeek V3 suporta entradas extremamente longas – com uma janela de contexto de até 128.000 tokens – possibilitando que ele processe documentos extensos, códigos fonte volumosos ou múltiplas instruções em uma única consulta. Essa extensa janela de contexto é um diferencial importante para tarefas como análise de código em projetos grandes ou sumarização de documentos longos, onde modelos convencionais esbarrariam em limites bem menores.
Inovações na Arquitetura (MLA e Balanceamento de Carga): Para alcançar inferência eficiente e treinamento econômico, o DeepSeek V3 incorpora inovações significativas em sua arquitetura. Uma delas é o Multi-head Latent Attention (MLA) – uma variação do mecanismo de atenção que permite ao modelo focar em múltiplos aspectos latentes da entrada simultaneamente. Em outras palavras, o MLA melhora a capacidade do modelo de extrair diferentes tipos de informação relevante de um texto de uma só vez, aumentando a eficiência e a qualidade das respostas. Além disso, o DeepSeek V3 implementa uma estratégia de balanceamento de carga sem perdas auxiliares (auxiliary-loss-free load balancing). Em modelos MoE, é comum usar perdas auxiliares para garantir que todos os especialistas sejam utilizados de forma equilibrada, mas isso pode introduzir alguma degradação de desempenho. O DeepSeek V3 pioneiramente dispensa essas perdas auxiliares, adotando um método de balancear a carga entre especialistas sem impactar negativamente o resultado. Essa estratégia mantém a estabilidade do treinamento e assegura que o modelo use seus múltiplos especialistas de maneira uniforme, evitando que apenas alguns componentes façam todo o trabalho. O resultado é um modelo mais estável durante o treinamento e eficiente na inferência.
Objetivo de Previsão de Múltiplos Tokens: Outra característica técnica notável é o uso de um objetivo de previsão de múltiplos tokens (Multi-Token Prediction, MTP) durante o treinamento. Diferente do treinamento tradicional, onde o modelo aprende a prever um token seguinte por vez, o DeepSeek V3 foi treinado para, em certos momentos, prever vários tokens em paralelo. Esse objetivo ajuda a impulsionar o desempenho do modelo e possibilita técnicas como decodificação especulativa, onde o modelo pode gerar blocos de texto de maneira mais rápida durante a inferência. Em termos práticos, isso significa que o DeepSeek V3 consegue gerar respostas em alta velocidade, aumentando a produtividade em aplicações interativas. De fato, testes indicam uma capacidade de geração em torno de 60 tokens por segundo, tornando a experiência de uso bastante fluida mesmo em diálogos complexos. (Observação: 60 tokens/s é um valor de referência sob condições ideais; o desempenho real pode variar conforme a infraestrutura.)
Treinamento e Capacidade de Aprendizado: O DeepSeek V3 foi pré-treinado em um volume massivo de dados (14,8 trilhões de tokens) cobrindo diversos domínios da linguagem, o que lhe confere um conhecimento enciclopédico de fatos, linguagens de programação, problemas matemáticos e muito mais. Após o pré-treino, o modelo passou por ajuste fino supervisionado – onde recebeu orientações em tarefas específicas por meio de exemplos rotulados – e etapas de aprendizado por reforço para refinar suas respostas de acordo com critérios de utilidade e segurança. Esse processo em múltiplas fases, semelhante ao utilizado em outros LLMs avançados, permite que o DeepSeek V3 não só entenda padrões de linguagem, mas também aprenda a realizar raciocínios estruturados e fornecer respostas alinhadas às expectativas humanas.
Vale destacar que os pesquisadores da DeepSeek aplicaram técnicas de treinamento altamente otimizadas para contornar limitações de hardware e custo: por exemplo, foi usada precisão mista FP8 (float de 8 bits) para acelerar o treinamento sem perda significativa de qualidade, e um pipeline de treinamento distribuído eficiente que praticamente eliminou gargalos de comunicação entre GPUs. Graças a essas inovações – apelidadas de DualPipe em comunicados da empresa – o custo total de treinamento do DeepSeek V3 ficou abaixo de 6 milhões de dólares, um número impressionantemente baixo em comparação com outros modelos de ponta. Essa otimização demonstra que, com criatividade em engenharia, é possível treinar modelos gigantes com orçamento reduzido, algo de grande interesse para a comunidade de IA.
Resumindo as especificações técnicas principais do DeepSeek V3:
- Arquitetura: MoE (Mixture-of-Experts) de última geração, com mecanismos avançados de atenção (MLA).
- Parâmetros: 671 bilhões (37B ativos por token).
- Contexto máximo: ~128 mil tokens de entrada (janela de contexto estendida).
- Treinamento: 14,8T tokens pré-treinados + ajuste fino supervisionado + reforço (incluindo distilações de modelos de raciocínio da própria DeepSeek).
- Inovações: Balanceamento de carga sem perda auxiliar, objetivo de multi-token, treinamento em precisão FP8, distilação de raciocínio, entre outros.
- Desempenho: Geração rápida de texto (~60 tokens/segundo) e desempenho competitivo em tarefas complexas (código, matemática, PLN), atingindo qualidade comparável a modelos proprietários líderes, porém alcançado com custo e infraestrutura significativamente menores.
Aplicações Práticas para Desenvolvedores
O DeepSeek V3 foi concebido com um amplo leque de aplicações práticas em mente, muitas das quais são especialmente relevantes para desenvolvedores de software, cientistas de dados e outros profissionais de tecnologia. Graças à sua capacidade de raciocínio avançado e compreensão profunda de linguagem, este modelo pode ser usado de forma eficaz nas seguintes situações:
- Assistência na Codificação: Uma das áreas de destaque do DeepSeek V3 é a geração e análise de código fonte. O modelo consegue completar trechos de código, sugerir correções de bugs e otimizações e até explicar o que um determinado código faz. Desenvolvedores podem integrá-lo em IDEs ou ferramentas de revisão de código para obter sugestões inteligentes em tempo real (similar a um “pair programmer” de IA). De fato, sua arquitetura foi aprimorada para lidar com tarefas de programação, tornando-o adequado para desafios de código complexos. Equipes podem utilizá-lo para acelerar o desenvolvimento, garantindo melhor qualidade de código e reduzindo o tempo de depuração.
- Agentes Autônomos e Ferramentas de IA: O DeepSeek V3 pode servir como o cérebro por trás de agentes de IA autônomos. Por exemplo, combinando-o com frameworks que permitem chamadas de função ou acesso a ferramentas externas, é possível criar agentes que realizam tarefas automaticamente (busca de informações, cálculos, interações com sistemas) a partir de comandos em linguagem natural. Sua janela de contexto extensa (128k tokens) permite que um agente mantenha “memória” de longas sessões ou carregue instruções detalhadas, o que é valioso em automação de processos complexos.
- Resposta a Perguntas e Suporte Inteligente: Por ser um modelo de linguagem treinado em vasta quantidade de conhecimento, o DeepSeek V3 é muito eficaz em respondência de perguntas (Question Answering). Ele pode extrair respostas precisas de documentação técnica, bases de conhecimento ou texto livre, sendo útil para criar chatbots de suporte técnico, assistentes virtuais de TI ou mesmo motores de busca aprimorados por IA. Em cenários corporativos, pode ser integrado a sistemas de FAQ avançados onde usuários fazem perguntas em linguagem natural e recebem respostas ricas e contextuais.
- IA Conversacional Avançada: Assim como os famosos chatbots de IA, o DeepSeek V3 pode conduzir conversas naturais com usuários. Por ter sido ajustado também para interação dialogal (possui um modelo de chat subjacente), ele pode manter contexto de diálogos prolongados e produzir respostas coerentes e pertinentes. Isso abre espaço para aplicações em atendimento automatizado, assistentes pessoais, educação (tutores virtuais) e entretenimento, onde a conversa com o usuário é a interface principal. Desenvolvedores podem utilizar o modelo para criar experiências conversacionais customizadas, definindo personalidades de chatbot ou regras de interação por meio de prompts de sistema.
- Geração de Conteúdo e Resumos: Com sua habilidade de gerar texto fluido em português (e outras línguas, dado seu treinamento amplo) e sintetizar informações, o DeepSeek V3 pode ser empregado para gerar artigos, relatórios ou resumos automaticamente. Por exemplo, ele pode resumir documentos extensos em pontos-chave, converter dados estruturados em descrições textuais (NLG – Natural Language Generation) ou até ajudar na escrita de documentação técnica a partir de especificações. Para profissionais de produto e marketing, isso significa acelerar a produção de conteúdo informativo, enquanto pesquisadores podem utilizá-lo para resumir papers ou gerar hipóteses baseadas em dados.
Em essência, qualquer tarefa que envolva compreensão e geração de linguagem natural pode potencialmente se beneficiar do DeepSeek V3. Seus pontos fortes em raciocínio lógico e manipulação de código o diferenciam particularmente para usos técnicos. Por exemplo, imagine integrar o DeepSeek V3 em um pipeline DevOps: ele poderia revisar descrições de pull requests, encontrar possíveis impactos de um commit analisando o código modificado, ou auxiliar na geração de scripts de configuração a partir de comandos em linguagem natural. As possibilidades vão desde acelerar tarefas triviais do dia a dia de um desenvolvedor (como escrever funções repetitivas) até soluções de IA sofisticadas, como sistemas de diálogo com capacidade de planejamento e resolução de problemas.
Exemplos de Uso com Código (Python)
Para ilustrar como desenvolvedores podem interagir com o DeepSeek V3 na prática, vamos ver alguns exemplos simples em Python. A maneira mais direta de usar o modelo é por meio da API de serviço do DeepSeek, oferecida pela plataforma oficial. Essa API segue um padrão compatível com o da OpenAI, o que torna sua adoção bastante intuitiva para quem já utilizou APIs de modelos de linguagem anteriormente.
1. Fazendo uma consulta simples à API (Chat Completion): No exemplo abaixo, usamos a biblioteca requests para enviar uma requisição HTTP à API do DeepSeek. Suponha que queremos que o modelo responda a uma pergunta ou tarefa qualquer – o fluxo básico envolve enviar um prompt no formato de conversa (com possíveis papéis de system e user) e receber a resposta do modelo como mensagem assistant.
import requests
import json
API_KEY = "SUA_CHAVE_DE_API_AQUI" # Substitua pela sua chave de API válida
API_URL = "https://api.deepseek.com/chat/completions"
# Montando o cabeçalho de autorização com a chave
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
# Exemplo de mensagem: vamos pedir ao modelo para explicar um trecho de código
mensagem_usuario = {
"role": "user",
"content": "Explique o seguinte código Python que calcula factorial:\n```python\ndef factorial(n):\n return 1 if n <= 1 else n * factorial(n-1)\n```"
}
data = {
"model": "deepseek-chat", # especifica o modelo DeepSeek V3 (versão chat)
"messages": [
{"role": "system", "content": "Você é um assistente de programação útil."},
mensagem_usuario
],
"temperature": 0.7
}
response = requests.post(API_URL, headers=headers, data=json.dumps(data))
if response.status_code == 200:
resposta_modelo = response.json()
texto_resposta = resposta_modelo["choices"][0]["message"]["content"]
print(texto_resposta.strip())
else:
print(f"Erro {response.status_code}: {response.text}")
No código acima, note que usamos o endpoint /chat/completions da API do DeepSeek, muito semelhante ao formato da API do OpenAI. Montamos um JSON com a chave do modelo (deepseek-chat para indicar o DeepSeek V3 em modo conversacional), uma lista de mensagens (incluindo um contexto de sistema que define brevemente o comportamento do assistente, e a mensagem do usuário contendo o prompt de interesse) e outros parâmetros como temperature para controlar a criatividade da resposta. Após fazer o POST, verificamos se o status retornado é 200 (sucesso) e então extraímos o conteúdo da resposta do modelo.
Caso tudo esteja configurado corretamente (chave de API válida, internet ativa, etc.), o modelo retornará um texto explicando o código Python de fatorial de forma clara e útil. Esse exemplo demonstra a facilidade de integração – em poucas linhas conseguimos enviar um pedido ao modelo e obter uma resposta. Desenvolvedores podem adaptar esse código para diversas finalidades, como construir chatbots personalizados, ferramentas de análise de código, entre outros.
2. Análise automatizada de código com DeepSeek V3: Expandindo a ideia anterior, podemos criar uma função Python que aproveita o poder do modelo para atuar como um revisor de código automatizado. Por exemplo, dado um trecho de código fonte, queremos que o DeepSeek V3 faça uma revisão, apontando erros, sugerindo melhorias e apresentando alternativas. Podemos definir uma função revisar_codigo(trecho) que formata um prompt adequadamente e usa a função auxiliar get_deepseek_response (semelhante à do exemplo anterior) para obter a resposta:
def revisar_codigo(trecho_codigo):
prompt = f"""
Trecho de Código:
{trecho_codigo}
Tarefa: Analise o trecho de código fornecido. Identifique quaisquer erros ou possíveis melhorias, sugira otimizações e, se aplicável, apresente implementações alternativas.
"""
return get_deepseek_response(prompt) # Usa a função que consulta a API do DeepSeek
Com essa função, poderíamos alimentar automaticamente diversos pedaços de código (por exemplo, extrair funções de um repositório) e obter feedback do modelo para cada um. Esse tipo de automação, integrado a um sistema de CI/CD ou a um editor, pode melhorar significativamente a qualidade do código, oferecendo revisões iniciais antes mesmo de um revisor humano olhar o código. Vale notar que no prompt acima incluímos instruções claras sobre a tarefa esperada (análise de código, identificação de erros, sugestões). Escrever bons prompts é parte essencial de obter respostas úteis de modelos de linguagem.
3. Interface interativa com Gradio (opcional): Para criar uma interface gráfica simples que permita a qualquer usuário colar um código e receber feedback do DeepSeek V3, podemos usar a biblioteca Gradio. Por exemplo:
import gradio as gr
# Função wrapper para o interface do Gradio
def interface_revisor(codigo):
return revisar_codigo(codigo)
gr.Interface(
fn=interface_revisor,
inputs=gr.Code(language='python', lines=15, label="Cole seu código aqui"),
outputs=gr.Textbox(label="Feedback do DeepSeek V3"),
title="Assistente de Revisão de Código (IA)",
description="Cole um trecho de código e receba uma análise com feedback e sugestões de melhorias do DeepSeek V3."
).launch(share=True)
Com o código acima, lançamos um pequeno aplicativo web local onde é possível colar códigos Python e ver as sugestões geradas pelo modelo. Este exemplo demonstra como é simples prototipar ferramentas úteis combinando o DeepSeek V3 com bibliotecas de interface amigáveis. O modelo age como motor de análise por trás, enquanto o Gradio cuida da interação com o usuário final.
Os exemplos fornecidos são apenas ilustrativos. Em um ambiente de produção, desenvolvedores devem gerenciar aspectos adicionais (como tratamento de erros, limites de taxa da API, armazenamento seguro da chave de API, etc.). Ainda assim, eles evidenciam que integrar o DeepSeek V3 em fluxos de trabalho existentes ou novos aplicativos é relativamente direto. Seja para automatizar respostas em um chatbot, revisar código ou gerar conteúdo dinâmico, alguns trechos de código Python bastam para colocar o poder do modelo em ação.
Instruções para Integração via API ou Modelo Local
O DeepSeek V3 pode ser acessado de duas formas principais: através da API em nuvem oferecida pela DeepSeek (método mais simples) ou executando o modelo localmente (self-hosted), caso haja necessidade de maior controle ou de trabalhar offline. A seguir, detalhamos ambos os métodos de integração:
Uso da API na Nuvem (Plataforma DeepSeek)
Integrar via API é geralmente a forma mais rápida de começar a usar o DeepSeek V3 em sua aplicação. Os passos básicos para isso são:
- Obter Credenciais de API: Acesse o site oficial da DeepSeek (há uma seção de API Platform ou Open Platform) e crie uma conta de desenvolvedor. Após login, gere uma chave de API exclusiva. Essa chave será utilizada para autenticar suas requisições. Muitas vezes, a DeepSeek fornece algum nível de acesso gratuito para testes iniciais, mas para uso contínuo ou em larga escala pode ser necessário adicionar créditos pagos (verifique o painel de desenvolvedor para informações de tarifas por token, que costumam ser apresentadas de forma transparente).
- Fazer Requisições para o Endpoint Correto: A API do DeepSeek V3 utiliza endpoints REST semelhantes aos da OpenAI. O endpoint principal para conversas é
https://api.deepseek.com/chat/completions. Você deverá fazer requisições HTTP POST para esse endpoint, incluindo no header a autorização Bearer com sua chave de API, e no corpo um JSON contendo os parâmetros da chamada (modelo a ser usado, mensagens ou prompt, temperatura, etc., conforme exemplificado na seção anterior). A resposta virá em formato JSON com a saída do modelo. A documentação da API DeepSeek fornece detalhes completos sobre todos os parâmetros opcionais (como ajuste de max_tokens, top_p, n respostas, uso de streaming, etc.), mas para muitas aplicações basta enviar um prompt e receber a conclusão. - Tratamento de Respostas e Erros: Ao integrar, certifique-se de tratar adequadamente as respostas. Uma resposta de sucesso (
status_code 200) conterá possivelmente uma lista de opções (choices) com o texto gerado pelo modelo. Em caso de erro (códigos 4XX ou 5XX), a API retorna mensagens de erro que ajudam a diagnosticar (por exemplo, código 401 para chave inválida, 429 para limite de requisições excedido, etc.). Implemente lógica de retentativa ou fallback conforme a criticidade da aplicação.
Uma vez configurada a comunicação básica, você pode incluir o DeepSeek V3 dentro de sua aplicação de diversas maneiras: chamadas síncronas do backend para gerar respostas ao usuário, processamento em lote de vários prompts, ou até mesmo utilizando o modo streaming da API para exibir as respostas token a token (útil para interfaces tipo chat mostrando a digitação do assistente em tempo real).
Dica: Ao utilizar a API em um produto, tenha atenção para não expor a chave de API em clientes (front-end). Mantenha as chamadas à API em um servidor controlado ou use proxies seguros. Além disso, monitore o uso de tokens para evitar custos inesperados – a DeepSeek fornece métricas de uso no painel do desenvolvedor.

Execução do Modelo Localmente (Self-Hosted)
Para alguns casos de uso, pode ser desejável ou necessário executar o modelo DeepSeek V3 em infraestruturas próprias, seja por questões de privacidade, custo de longo prazo ou customização. A boa notícia é que o DeepSeek V3 disponibiliza seus modelos para uso local; a consideração importante aqui é que trata-se de um modelo extremamente grande, exigindo hardware de ponta para rodar eficientemente.
Requisitos de Hardware: Devido aos seus 671 bilhões de parâmetros, rodar o DeepSeek V3 na íntegra requer GPUs de classe data center com alta memória VRAM. Estimativas indicam a necessidade de múltiplas GPUs de 80GB (ou mais) em paralelo para carregar o modelo completo. Por exemplo, soluções recentes têm usado GPUs AMD Instinct MI300X ou NVIDIA H100 em configurações de 8 ou mais placas interligadas. Em setups menores, versões compactadas ou distiladas do modelo podem ser usadas (a DeepSeek e a comunidade lançaram algumas variações reduzidas, embora muitas vezes com trade-offs de desempenho). Em síntese, para executar localmente o modelo full, prepare-se para usar servidores equipados com aceleradores de última geração e infraestrutura de interconexão rápida (InfiniBand, PCIe Gen5, etc.).
Obtendo os Pesos do Modelo: Os pesos (weights) do DeepSeek V3 estão disponíveis publicamente, por exemplo, através do Hub do Hugging Face no repositório deepseek-ai/DeepSeek-V3. Você pode usar o cliente de linha de comando do Hugging Face (huggingface-cli) para baixar os arquivos do modelo para o seu ambiente. Tenha em mente que o download é enorme (centenas de gigabytes, ou até perto de 1 terabyte, dado que o próprio repositório indica ~685 bilhões de valores quando inclui módulos auxiliares). Certifique-se de ter espaço em disco e paciência para essa etapa.
# Exemplo: Baixando o modelo DeepSeek V3 via huggingface-cli
pip install huggingface_hub[cli]
huggingface-cli download deepseek-ai/DeepSeek-V3
O comando acima (executado no terminal) irá autenticar e baixar os arquivos do modelo para o cache local do Hugging Face (tipicamente em ~/.cache/huggingface). Esse processo pode demorar bastante tempo devido ao tamanho massivo do modelo.
Configurando um Servidor de Inferência: Devido à arquitetura MoE e ao tamanho, rodar o DeepSeek V3 não é tão trivial quanto carregar um modelo menor via transformers padrão. A DeepSeek, em parceria com a comunidade, fornece componentes de software especializados para a inferência. Um exemplo é o SGLang – um servidor de inferência otimizado para modelos de próxima geração. Conforme documentação de terceiros, um fluxo de setup no ambiente Linux envolve construir um container Docker com suporte a ROCm (para GPUs AMD) ou CUDA (para NVIDIA), montar os pesos baixados no container e executar um servidor que expõe uma API local compatível com o formato de chat. Um comando típico, após baixar os pesos e clonar o repositório do servidor, seria similar a:
docker run -d --gpus all --ipc=host -v $HOME/.cache/huggingface:/root/.cache/huggingface -p 30000:30000 \
my_deepseek_image:latest \
python3 -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3 --tp 8 --host 0.0.0.0 --port 30000
No exemplo acima (hipotético), assumimos que uma imagem Docker configurada com os requisitos (como o SGLang) está disponível e usamos --tp 8 para indicar tensor parallelism com 8 GPUs. O servidor de inferência abriria uma porta (30000) para receber requisições no mesmo formato da API (ex: POST /v1/chat/completions semelhante ao endpoint cloud), mas rodando localmente. A partir daí, o uso do modelo seria via chamadas REST internas ou mesmo adaptadores para frameworks de ML. Novamente, configurar isso exige um nível avançado de conhecimento em deploy de modelos e acesso a hardware especializado.
Opção de Modelos Menores: Caso sua necessidade seja rodar localmente mas você não dispõe de infra para o V3 completo, considere usar modelos alternativos ou compactados. A DeepSeek lançou, por exemplo, um modelo denominado R1-0528-Qwen3-8B que é uma versão destilada de 8 bilhões de parâmetros visando hardware limitado. Embora não possua todo o poder do V3 gigante, esse tipo de modelo pode ser suficiente para protótipos ou aplicações menos exigentes, e pode rodar em GPUs de ~16GB. Além disso, a comunidade Open Source vem trabalhando em reproduzir variantes abertas (como o projeto Open-R1 mencionado em blogs). Portanto, avalie o trade-off entre desempenho e viabilidade de deployment conforme seu caso de uso.
Resumo (API vs Local): Integrar via API é recomendado para começar rápido, sem preocupações com infraestrutura – você obtém acesso imediato ao DeepSeek V3 completo, pagando apenas pelo uso (tokens processados). Já a execução local faz sentido para quem precisa de controle total, latência reduzida in-loco, garantir privacidade dos dados (sem envio a terceiros), ou quer evitar custos de token em longo prazo ao já possuir hardware. Em ambos os cenários, o DeepSeek V3 oferece flexibilidade para atender às demandas dos desenvolvedores.
Benefícios e Vantagens para Times de Engenharia, Pesquisa e Produto
A adoção do DeepSeek V3 pode trazer diversos benefícios para equipes técnicas e de produto que buscam incorporar inteligência artificial de linguagem em seus projetos. Abaixo destacamos as principais vantagens e pontos fortes deste modelo:
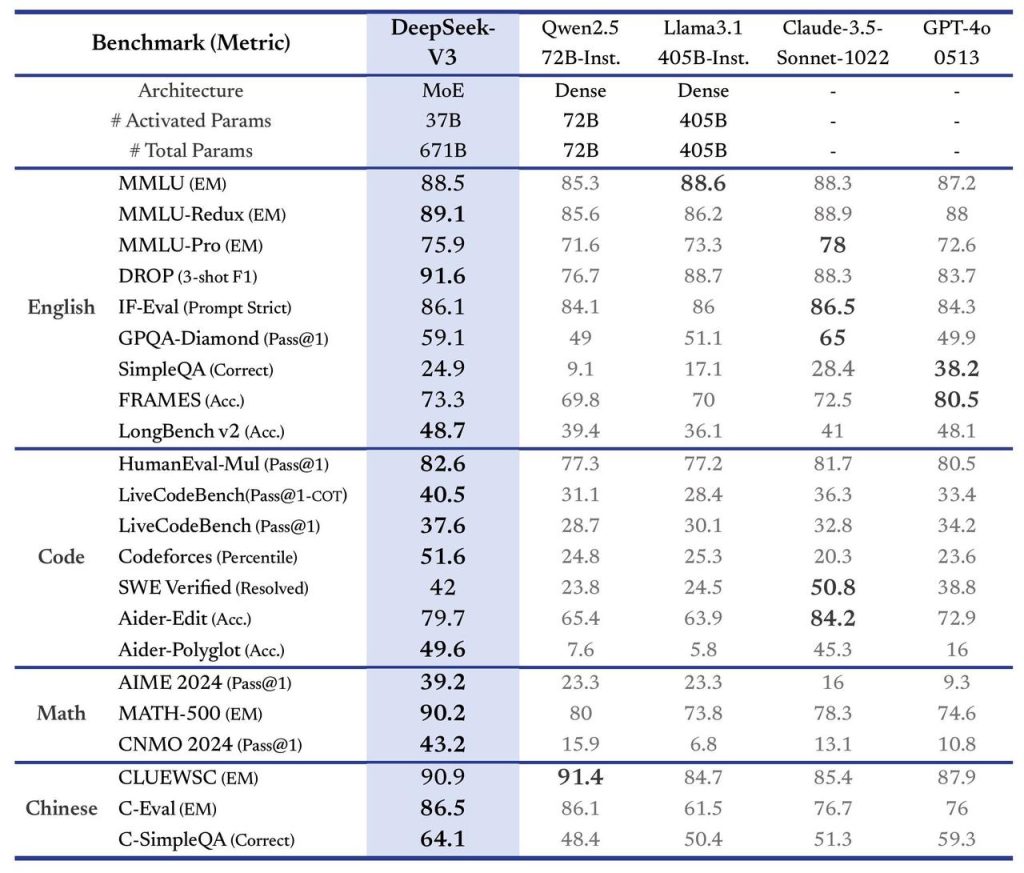
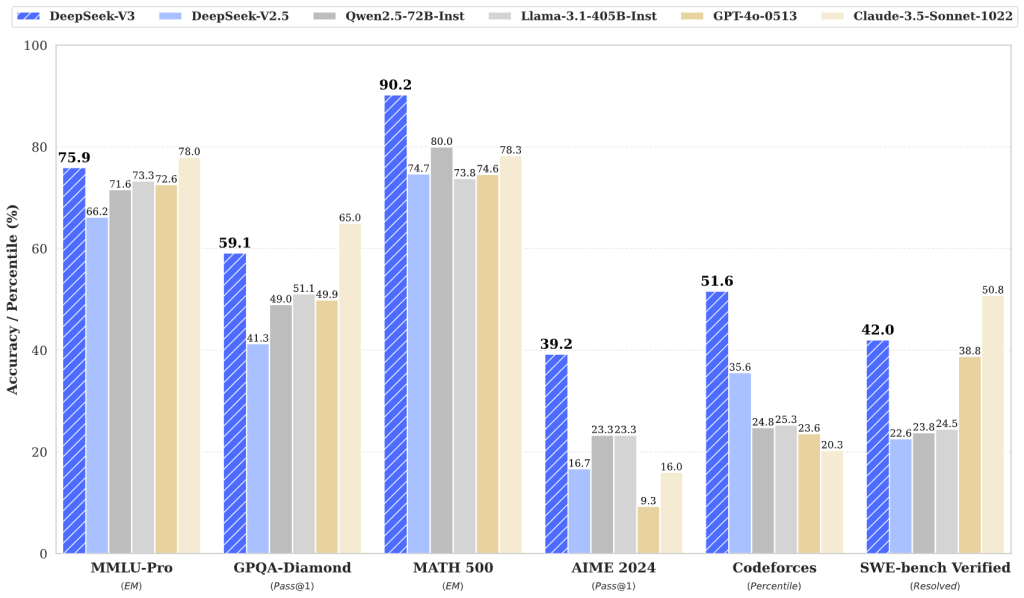
Desempenho de Ponta em Tarefas Complexas: O DeepSeek V3 demonstra desempenho excepcional em tarefas que tradicionalmente desafiam os LLMs, como resolução de problemas matemáticos, entendimento de código e raciocínio lógico. Para um time de engenharia, isso significa poder contar com uma ferramenta que ajuda a navegar em problemas difíceis, sugerindo soluções de algoritmo, identificando falhas sutis ou testando cenários. Ele pode atuar como um consultor inteligente disponível 24/7, potencializando a capacidade do time de resolver issues e implementar features corretamente.
Janela de Contexto Ampla (128k): Muitos modelos comerciais impõem limites de contexto menores (por exemplo, 4k, 8k ou 32k tokens), o que restringe o quanto de informação podemos fornecer de uma só vez. Com o DeepSeek V3, a equipe pode aproveitar até 128 mil tokens de contexto. Na prática, isso permite fornecer documentação inteira, múltiplos arquivos de código, ou longas sequências de conversa ao modelo de uma só vez, obtendo respostas que levam em conta todos esses detalhes. Para times de produto, isso se traduz em assistentes mais contextuais (por exemplo, um helpdesk AI que lê manuais inteiros do produto antes de responder ao cliente) e para pesquisa, a capacidade de analisar grandes volumes de texto (conjuntos de artigos, logs extensos) de maneira integrada.
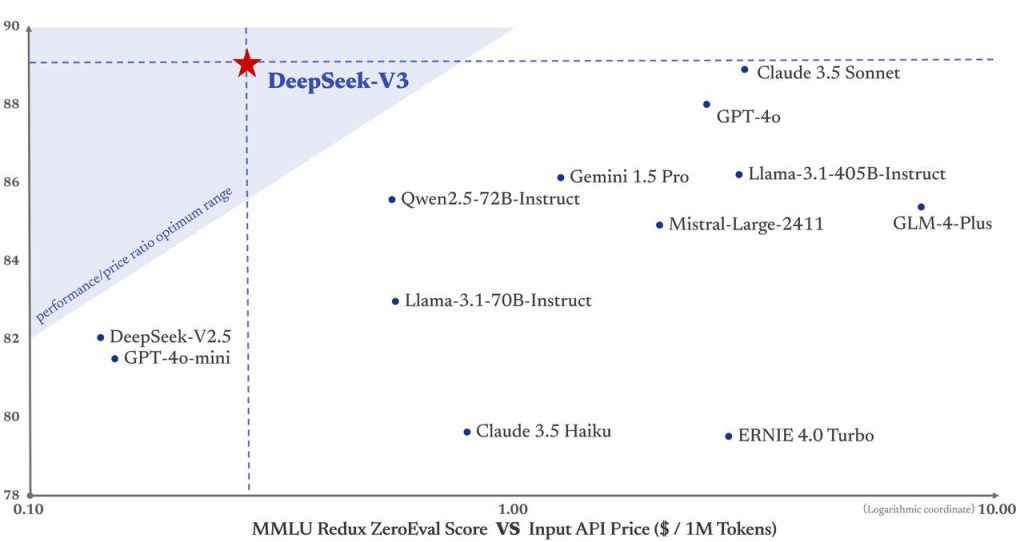
Open Source e Custos Acessíveis: Diferentemente de certas soluções proprietárias, o DeepSeek V3 tem um forte compromisso com abertura. Os pesos do modelo base estão disponíveis sob licença permissiva (MIT para código, e uma licença de modelo aberta), o que dá à comunidade liberdade para uso e até adaptação. Além disso, a DeepSeek disponibiliza acesso gratuito ao modelo via aplicativos e web, e as cobranças de API (caso você exceda os limites gratuitos) tendem a ser mais acessíveis do que de provedores tradicionais, tornando viável sua utilização mesmo em startups ou projetos com orçamento limitado. Para times de produto, isso significa a possibilidade de oferecer funcionalidades de IA avançadas aos usuários finais com custo menor, melhorando ROI. Para pesquisa, significa poder experimentar, auditar e modificar o modelo conforme necessário, algo crucial para desenvolvimentos científicos.
Colaboração e Comunidade: Ao ser amplamente aberto, o DeepSeek V3 atraiu uma comunidade de desenvolvedores ativa globalmente. Novas ferramentas, tutoriais e integrações surgem rapidamente (como conectores para diferentes linguagens, plugins em editores, etc.). Equipes de engenharia podem se beneficiar desse ecossistema vibrante – economizando tempo ao usar soluções prontas da comunidade e contribuindo de volta com melhorias. Essa colaboração lembra o modelo open source de software, onde inovações são compartilhadas. No caso do DeepSeek V3, já vemos iniciativas de terceiros para torná-lo mais leve, ou incorporá-lo em plataformas como a OpenRouter e Together AI, facilitando ainda mais seu consumo. Ter um modelo de IA de alto nível que não é uma “caixa preta” proprietária também facilita a conformidade e auditoria: a equipe pode inspecionar o modelo em busca de vieses ou ajustar seu comportamento via fine-tuning se necessário, sem ficar presa a um vendor.
Versatilidade de Uso e Integração: Como demonstrado, o DeepSeek V3 pode atuar em diversos papéis – desde um simples autocomplete de código até um agente conversacional estratégico. Essa versatilidade agrega valor a times de produto, que com um único modelo podem habilitar múltiplas features inteligentes na aplicação (busca semântica, chat de suporte, geração de conteúdo, etc.), mantendo uma consistência de comportamento e minimizando a necessidade de soluções fragmentadas. Para equipes de pesquisa e data science, ter uma plataforma comum capaz de lidar com NLP, NLG e até tarefas multi-modais (via extensões) simplifica o pipeline de experimentos.
Em resumo, o DeepSeek V3 oferece a combinação atraente de alto desempenho técnico, flexibilidade de implantação e acessibilidade econômica. Ele nivela o campo de jogo, permitindo que mesmo organizações menores tenham acesso a capacidades de IA que rivalizam com as de gigantes do setor (sem incorrer nos mesmos custos).
Para times de engenharia buscando aumentar produtividade, para pesquisadores explorando novas fronteiras em processamento de linguagem, ou para gerentes de produto desejando agregar inteligência a seus aplicativos, o DeepSeek V3 representa uma ferramenta poderosa e viável.
Melhores Práticas de Uso e Segurança
Ao integrar um modelo de linguagem poderoso como o DeepSeek V3 em produtos e fluxos de trabalho, é importante adotar boas práticas tanto para obter os melhores resultados quanto para garantir segurança e conformidade. Aqui estão algumas recomendações importantes:
Engenharia de Prompt Eficiente: A qualidade das saídas do modelo depende fortemente de como as entradas (prompts) são formuladas. Forneça instruções claras e contextuais nas mensagens de sistema ou usuário. Por exemplo, defina o papel do modelo (“Você é um assistente de código…”) e seja específico no pedido (“Analise este código buscando erros de lógica…”). Evite prompts ambíguos. Teste variações de prompt para ver quais levam às respostas mais úteis. Documente internamente exemplos de prompts eficazes para que todo o time siga padrões semelhantes.
Validação e Supervisão das Respostas: Embora o DeepSeek V3 apresente alta competência, como qualquer LLM ele pode gerar outputs incorretos ou inesperados (também conhecido como alucinações). Portanto, crie mecanismos de validação das respostas antes de usá-las cegamente. Se o modelo gerar código, por exemplo, faça com que o sistema tente compilá-lo/executá-lo em um ambiente isolado e verifique erros. Se a resposta for uma informação factual crítica, considere checá-la contra fontes confiáveis. Em contexto de atendimento automatizado, é recomendável manter um humano de prontidão para revisar ou aprovar respostas em casos sensíveis.
Filtro de Conteúdo e Políticas de Uso: Utilize filtros ou verificações de conteúdo para evitar que o modelo produza saídas inadequadas (ofensivas, preconceituosas, confidenciais). Apesar do treinamento e do RL terem incluído esforços para evitar vieses e linguagem tóxica, nenhum modelo é perfeito. Implementar uma camada de moderação – seja via regras simples (palavras banidas) ou usando outro modelo classificador – ajuda a assegurar que seu produto não veicule conteúdo indevido gerado pela IA. Além disso, configure limites de comprimento de resposta e evite compartilhar dados sensíveis nos prompts. Se precisar que o modelo analise dados privados (como código proprietário ou documentos internos), avalie a opção de rodá-lo localmente ou garanta em contrato que dados enviados à API não serão usados para re-treino e serão mantidos confidenciais.
Segurança e Privacidade dos Dados: Ao usar a API em nuvem, entenda que os dados enviados (prompts e respostas) transitam e potencialmente ficam armazenados nos servidores da DeepSeek, que estão sujeitos às leis e políticas do país de origem (China, no caso da DeepSeek). Para cumprir requisitos de privacidade (por exemplo, LGPD, GDPR) e políticas corporativas, evite enviar informações pessoais identificáveis ou propriedade intelectual ultra-sensível para a API. Se sua organização for de um setor altamente regulado (saúde, financeiro, governamental), consulte a área jurídica sobre o uso de um serviço de IA estrangeiro – inclusive houve casos de órgãos públicos banindo o uso do DeepSeek por preocupações de vazamento de dados e segurança. Uma solução é optar pela implantação on-premises (local) do modelo para manter todos os dados internamente. Caso use a nuvem DeepSeek, revise a política de privacidade e considere anonimar/criptografar partes sensíveis dos prompts.
Limites de Taxa e Escalonamento: Adote práticas de rate limiting no uso da API para não exceder limites e para distribuir carga de maneira estável. Em uma aplicação de produção, um surto de requisições poderia tanto gerar custos altos quanto saturar o serviço (levando a lentidão ou erros 429). Implemente filas ou backpressure no sistema caso o volume de chamadas ao modelo aumente além do previsto. Para cenários de altíssimo volume, avalie se modelos menores ou caches de respostas podem ser empregados para aliviar carga.
Manutenção e Atualizações do Modelo: Acompanhe as atualizações no ecossistema DeepSeek. A empresa pode lançar versões aprimoradas (como V3.1, V3.2 etc.) ou patches de segurança. Esteja pronto para testar e migrar para versões mais novas que tragam melhorias significativas ou correções. Da mesma forma, fique atento a insights publicados pela comunidade sobre melhor utilização do modelo. Por exemplo, descobertas sobre tokens especiais que ativam certos modos, ou configurações ótimas de hyperparâmetros de inferência para melhorar performance sem custo adicional. Incorporar essas melhorias contínuas fará seu uso do DeepSeek V3 permanecer eficiente e seguro ao longo do tempo.
Em suma, tratar um modelo de linguagem avançado na sua stack exige a mesma diligência que qualquer outro componente crítico: planejamento, testes abrangentes, monitoramento e medidas de controle. Seguindo as melhores práticas, você colhe o melhor do DeepSeek V3 – colaborações homem-IA produtivas, recursos inteligentes no seu produto – minimizando riscos de surpresas desagradáveis. A IA responsável é um princípio chave: use o poder do modelo de forma consciente e planejada, garantindo que ele agregue valor real aos usuários finais com confiança.
Considerações sobre Desempenho e Limitações
Apesar de todo o potencial do DeepSeek V3, é importante entender também suas limitações e desafios práticos para calibrar expectativas e planejar mitigações:
Infraestrutura Exigida: Como enfatizado, o DeepSeek V3 é extremamente pesado em termos computacionais. Isso implica que, sem acesso à infraestrutura adequada (GPUs de alto nível ou serviço cloud), torna-se inviável utilizá-lo localmente. Mesmo na nuvem, requisições que utilizem muitos tokens (por exemplo, contexto próximo do limite de 128k) podem ter latências maiores e custos proporcionais. Portanto, em termos de desempenho, o modelo brilha em capacidade, mas exige recursos robustos. Equipes devem dimensionar bem seus servidores e orçamentos de acordo com o uso previsto. Para inferências mais rápidas e leves, considere a possibilidade de usar versões distiladas ou limitar o tamanho do contexto efetivamente utilizado quando possível (não enviar documentação inteira se um resumo bastar, por exemplo).
Comportamento em Contextos Extremos: A janela de 128k tokens é suportada, mas nem sempre o desempenho do modelo será linearmente ótimo até esse limite. Há relatos de degradação de qualidade de respostas com contextos muito extensos, ou consumo elevado de memória que pode forçar paging. É recomendável testar gradualmente contextos maiores e verificar onde começam eventuais perdas de coerência. Em muitos casos, 64k tokens bem estruturados já atendem, e a DeepSeek inclusive ajustou sua plataforma para otimizar recursos em torno desse patamar. Use o contexto com sabedoria: mais não é sempre melhor, especialmente se partes do prompt não forem diretamente relevantes à pergunta feita.
Limitações de Conhecimento Atualizado: O DeepSeek V3, assim como outros LLMs, foi treinado em dados até certo período (provavelmente até meados de 2024, dado seu lançamento no final de 2024). Isso significa que não tem conhecimento de eventos ou dados muito recentes a menos que explicitamente fornecidos no prompt. Para aplicações que requerem informações atualizadas (por exemplo, responder perguntas sobre acontecimentos de 2025 em diante), será necessário combinar o modelo com mecanismos de atualização, como consultas a bancos de dados ou APIs externas dentro de um agente, ou fornecer contexto fresco manualmente.
Não Especializado em Visão ou Áudio: O DeepSeek V3 é um modelo somente de texto. Diferentemente de alguns outros grandes modelos que têm variantes multimodais, o V3 padrão não processa imagens ou áudio. Portanto, se o seu produto exigir compreensão direta de imagens ou fala, seria preciso usar modelos adicionais (como um OCR ou um modelo de voz-para-texto) para converter essas modalidades em texto antes de enviar ao DeepSeek. A DeepSeek possui outros modelos especializados (e.g., Janus-Pro para visão), mas isso foge do escopo do V3 textual em si.
Licenciamento e “Abertura” Limitada: Embora o DeepSeek V3 seja amplamente aberto para uso, os desenvolvedores devem estar cientes de que nem tudo é 100% open source no sentido estrito. A empresa não liberou, por exemplo, o conjunto completo de dados de treinamento nem todo o código de treinamento interno. Os pesos do modelo têm uma licença específica (LICENSE-MODEL) que, embora permita uso comercial gratuito, ainda impõe alguns termos (como atribuição e isenção de responsabilidade). Em contextos acadêmicos ou corporativos muito sensíveis a licenças, convém revisar essas licenças para garantir conformidade. Além disso, o fato de não se conhecer completamente a origem dos dados de treino significa que podem existir vieses desconhecidos no modelo. Equipes devem monitorar as saídas para identificar e mitigar vieses ou erros sistemáticos que possam surgir (por exemplo, se o modelo tende a performar pior em inputs de um determinado domínio ou linguagem minoritária).
Comparação com Especialistas Humanos: É fundamental notar que, apesar de seu avançado desempenho médio, o DeepSeek V3 não substitui julgamento humano especializado em todas as situações. Por exemplo, ao gerar código, ele pode não conhecer detalhes específicos do framework interno da sua empresa; ao responder perguntas médicas/jurídicas, pode dar uma resposta convincente mas não 100% precisa juridicamente. Ele não tem “compreensão” ou intenção própria – pode inventar justificativas erradas com confiança. Portanto, a limitação inerente aqui é a de todos os modelos de IA generativa atuais: use-os como auxiliares e não autoridades finais. Eduque os usuários finais (e sua equipe) de que as respostas são geradas automaticamente e podem conter erros. Mantenha humanos “no circuito” quando a decisão tomada a partir da saída do modelo tiver alto impacto.
Em termos de desempenho bruto, o DeepSeek V3 atingiu um marco ao demonstrar que é possível chegar ao estado da arte com uma fração do custo de treinamento usual, mas essa eficiência de custo veio acompanhada de enorme engenharia customizada. Nem todos os usuários finais perceberão isso, mas é um feito notável: a DeepSeek conseguiu entregar uma IA comparável às melhores, treinada com apenas ~2.8 milhões de horas GPU H800 (segundo seu relatório técnico), e fazendo isso sem incidentes de instabilidade no treinamento.
Isso reforça que, se houver limitações, elas não derivam de falta de qualidade intrínseca, mas sim de quão bem conseguimos aplicar o modelo no mundo real. Em suma, conhecer as limitações permite contorná-las – seja restringindo certos usos, complementando o modelo com outras ferramentas ou setando expectativas corretas com stakeholders e usuários. Com esse entendimento em mente, o DeepSeek V3 pode ser aproveitado com máxima efetividade e mínimo risco.
Conclusão e Próximos Passos
O DeepSeek V3 representa um avanço significativo no campo de modelos de linguagem, unindo capacidade colossal com inovações arquiteturais que o tornam viável e útil para a comunidade de desenvolvimento. Neste artigo, exploramos desde a definição do que é o DeepSeek V3 e sua finalidade, passando por detalhes técnicos da sua arquitetura MoE e treinamento, aplicações práticas em cenários de codificação, agentes autônomos e conversação, até exemplos concretos de código Python demonstrando como interagir com o modelo via API e localmente.
Também discutimos como integrar o modelo nos seus projetos, realçando os benefícios que ele traz para equipes de engenharia, pesquisa e produto – desde desempenho superior em tarefas desafiadoras até custos mais acessíveis e uma comunidade open source engajada. Abordamos ainda as melhores práticas para um uso responsável e seguro, bem como as considerações de desempenho e limitações que convém ter em mente.
Em resumo, o DeepSeek V3 se posiciona como uma ferramenta poderosa e versátil para quem deseja incorporar IA de linguagem natural em soluções de software. Quer você esteja construindo um assistente de programação para seu time, um chatbot inteligente para seus clientes ou investigando novos métodos de raciocínio automático, vale a pena explorar o que o DeepSeek V3 pode oferecer. A chave para o sucesso é alinhar seus recursos e restrições ao seu caso de uso: aproveitar a API em nuvem para rapidez ou investir em uma implantação local para controle total; usar prompts bem elaborados e monitorar as saídas; e manter-se atualizado com a evolução do modelo.
Chamada para Ação: Se você ficou interessado em experimentar o DeepSeek V3, o próximo passo é simples – acesse a plataforma oficial da DeepSeek e obtenha uma chave de API gratuita para começar a fazer testes. Tente integrar o modelo em um pequeno projeto piloto, como um bot de chat no seu site ou um script que analisa pedaços do seu código. Sinta na prática como o modelo se comporta, e então avalie as possibilidades de escalá-lo para algo maior. A documentação oficial e a comunidade (forums, GitHub, etc.) estão à disposição para ajudar nas dúvidas durante a jornada.
O mundo da inteligência artificial generativa está se movendo rápido, e o DeepSeek V3 é uma das tecnologias na vanguarda dessa onda – explore-o e descubra como ele pode impulsionar seus projetos e talvez inspirar novas ideias que antes não eram possíveis. Boa exploração e bom desenvolvimento!


